002计算机图形学之直线画线算法
主要思想是,由于我们在缓存区上画点,全部是整数。那么在画线的时候,当斜率k小于1的时候,下一个点是取(x+1,y+1)还是(x+1,y)取决于点(x+1,y+0.5)是在该直线的上方或者下方,从而将可以通过判断一个参数的的符号来得到下一个点的位置,提高了代码的效率。
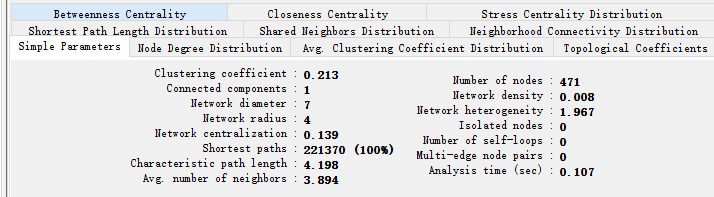
使用Cytoscape的NetworkAnalyzer工具计算网络相关属性
在之前的文章中,介绍过igraph工具,可以通过编程处理网络数据,该工具使用与大规模,大批量数据的处理。如果只是偶尔需要分析下网络数据,采用cytoscape这种图形界面工具更加的简单便捷。
基于TypeScript从0到1搭建一款爬虫工具
今天,我们将使用TS这门语言搭建一款爬虫工具。目标网址是什么呢?我们去上网一搜,经过几番排查之后,我们选定了这一个网站。
自托管服务清单——GitHub 热点速览 v.21.01
这是新年 2021 年的第一期 GitHub 热点趋势,下篇开始小鱼干想整点不一样的,在形式不变的前提下,下期的看点关键词由你来定,除了给关键词之外,你也可以在评论区推荐相关的 Repo。

Vue webpack 压缩打包上线 首屏加载时间过长 优化方案
最近博客上线,但是在首次加载的时候,需要消耗很多时间,大概在50秒左右,就是说第一页登录页面,就需要用户等待50秒(服务器是最低配置也是一个原因),看了一下network,发现有两个文件加载的时间特别长,一个是vendor.js,一个是app.js,打包的时候,这两个文件也提示文件过大

大数据工具:IKAnalyzer分词工具介绍与使用
为什么要分词呢,当大数据处理中要提取语句的特征值,进行向量计算。所有我们要用开源分词工具把语句中的关键词提取出来。
手把手教你搭建自己的 AV1 Analyzer
随着最近H.266标准的完成,其惊人的复杂度令人生畏,与此同时,新兴的AOM组织于2018年年中耗时3年完成的AV1标准吸引了不少业内人的眼球,不仅仅是其有竞争力的编码性能,还有其在流媒体方面的优异表现,最重要的是其免专利费(royalty-free)使用这一项就会吸引各大厂商跟进。
手把手教你搭建自己的 AV1 Analyzer
随着最近H.266标准的完成,其惊人的复杂度令人生畏,与此同时,新兴的AOM组织于2018年年中耗时3年完成的AV1标准吸引了不少业内人的眼球,不仅仅是其有竞争力的编码性能,还有其在流媒体方面的优异表现,最重要的是其免专利费(royalty-free)使用这一项就会吸引各大厂商跟进。
lucene实现搜索浅谈
项目中实现检索功能是现在许多网站项目都存在的功能,比如cms系统等。
Rust的开发环境与工具
无论使用何种系统, 均可以根据 Rust 官方网站提供的 rustup-init 工具完成 Rust 的安装. rustup-init 下载地址:
使用Lucene.Net做一个简单的搜索引擎-全文索引
Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎。

前端静态资源缓存策略
页面加载提速是战场,首当其冲要优化的就是 静态资源(js|css) 的加载速度。我们小组去年基于Vue开发了一个积分商城单页面应用。本文旨在与大家分享在单页应用中使用纯前端手段加速静态资源的获取,从而达到页面加速。

Solr和Spring Data Solr
Solr是一个开源搜索平台,用于构建搜索应用程序。 它建立在Lucene(全文搜索引擎)之上。 Solr是企业级的,快速的和高度可扩展的。Solr可以和Hadoop(http://www.yiibai.com/hadoop/)一起使用。由于Hadoop处理大量数据,Solr帮助我们从这么大的源中找到所需的信息。不仅限于搜索,Solr也可以用于存储目的。像其他NoSQL数据库一样,它是一种非关系数据存储和处理技术。总之,Solr是一个可扩展的,可部署,搜索/存储引擎,优化搜索大量以文本为中心的数据。

cuckoo沙箱技术分析全景图
从事信息安全技术行业的小伙伴们都知道沙箱技术(有些也称沙盒),用来判断一个程序或者文件是否是恶意的病毒、木马、漏洞攻击exp或其他恶意软件。其原理简单来说就是提供了一个虚拟的环境,把分析目标放到这个虚拟环境中,通过一系列技术来“观测”其行为,根据观测结果来判定这是一个正常良民(合法文件)还是一个不怀好意的坏家伙(恶意文件)。
Lucene 全文检索
全文检索就是先分词创建索引,再执行搜索的过程。分词就是将一段文字分成一个个单词。全文检索就将一段文字分成一个个单词去查询数据

Elasticsearch Mapping
Elasticsearch Mapping用于定义文档。比如:文档所拥有的字段、文档中每个字段的数据类型、哪些字段需要进行索引等。本文将先后从mapping type、mapping parameter、mapping field和mapping explosion这四个维度展开。
javaweb-Lucene-1-61
Lucene是一个基于Java开发全文检索工具包。
就是将不规范的文档的内容单词进行分割,建立单词-文档索引,这样查询某个单词内容时可以通过索引快速查找相关文档,内容
对于一些网站内部的内容检索有需要
这项技术其实有更成熟的封装,比如专门的服务器等,这里只是普及一下相关概念,后面会解释进行其他的基于lucene的上层封装的相关技术
工程:https://github.com/Jonekaka/javaweb-Lucene-1-61
【全文检索_03】Lucene 基本使用
在上一文 【全文检索_02】Lucene 入门案例 中我们使用 Lucene 默认分词器对中文版双城记进行分词,这个操作其实是有问题的。哎?!我们明明分词成功而且搜索到了啊,怎么会有问题。我们之前成功搜索是因为我们搜索的是一个关键字,而不是一个关键词。我们先来看一下默认分词器的分词效果是怎么样的。

快速学习Lucene-Lucene分析器
使用方法:
第一步:把jar包添加到工程中
第二步:把配置文件和扩展词典和停用词词典添加到classpath下
【Lucene4.8教程之四】分析
分析(Analysis),在Lucene中指的是将域(Field)文本转换成最主要的索引表示单元–项(Term)的过程。在搜索过程中,这些项用于决定什么样的文档可以匹配查词条件。