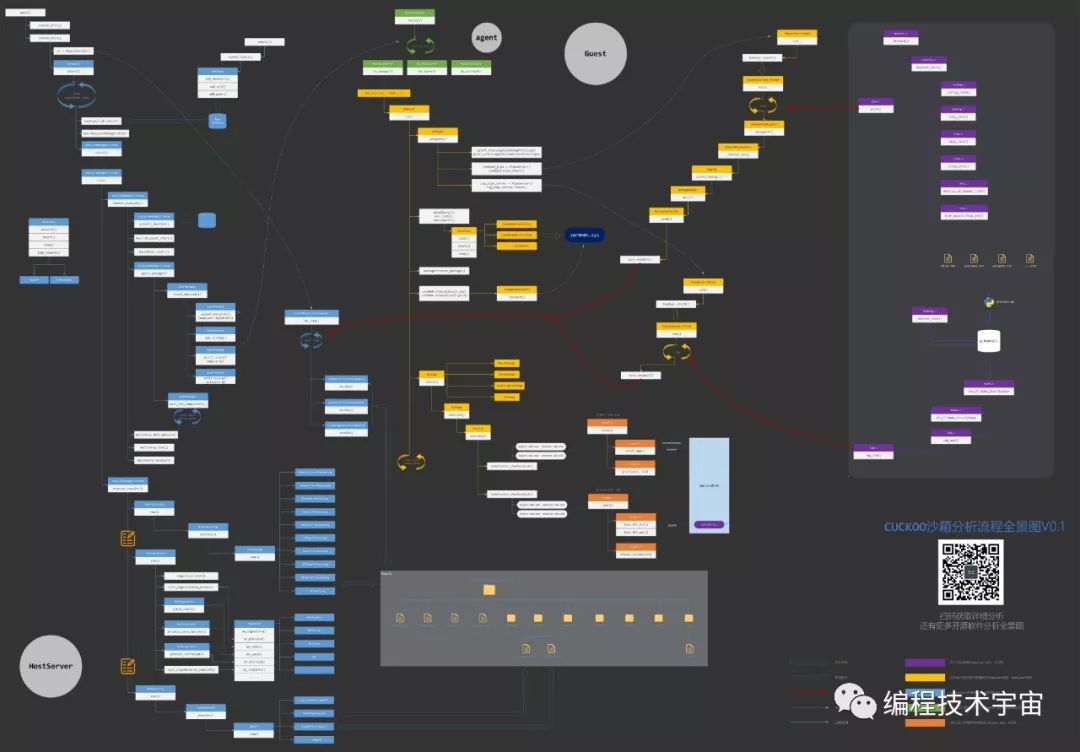
导言
本文总计四千余字,十余张图,浏览时间较长,建议先mark
从事信息安全技术行业的小伙伴们都知道沙箱技术(有些也称沙盒),用来判断一个程序或者文件是否是恶意的病毒、木马、漏洞攻击exp或其他恶意软件。其原理简单来说就是提供了一个虚拟的环境,把分析目标放到这个虚拟环境中,通过一系列技术来“观测”其行为,根据观测结果来判定这是一个正常良民(合法文件)还是一个不怀好意的坏家伙(恶意文件)。
说起沙箱技术,最出名的当属国外的FireEye。国内也有许多厂商推出沙箱产品,不过,这其中有相当部分厂商和团队都弘扬了拿来主义精神:基于开源的cuckoo进行二次开发,小轩也不例外

。但网络上关于cuckoo的介绍实在有限,于是花了点时间将cuckoo代码进行了粗浅分析,整理绘制了cuckoo技术全景图,分享出来,欢迎探讨。
Cuckoo架构概览
在看全景图前,先看看cuckoo官网的一张技术架构图:
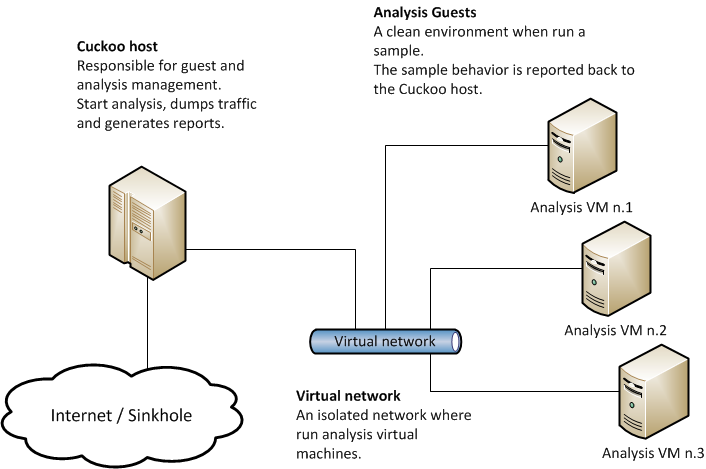
整个cuckoo分为两部分:
Cuckoo Host:
Cuckoo的核心服务端,负责分析任务的启动和分析结果报告的生成,还要负责管理多个虚拟机。
Analysis Guest:
分析客户机,可以理解为一台虚拟机,负责提供虚拟环境供目标样本运行,检测目标的运行情况,并将检测到的数据汇报给Cuckoo Host。
两者之间通过虚拟网络连接,多台虚拟机与Cuckoo Host组成一个局域网。
官网对于Cuckoo的技术架构描述就这么多了,接下来是小轩的分析。我们从cuckoo的启动和一次分析任务的发起,来看看Cuckoo的整体流程是如何运转的。
Host启动运行与初始化
首先是host部分,Cuckoo Host是采用Python开发,最初的启动流程如图:
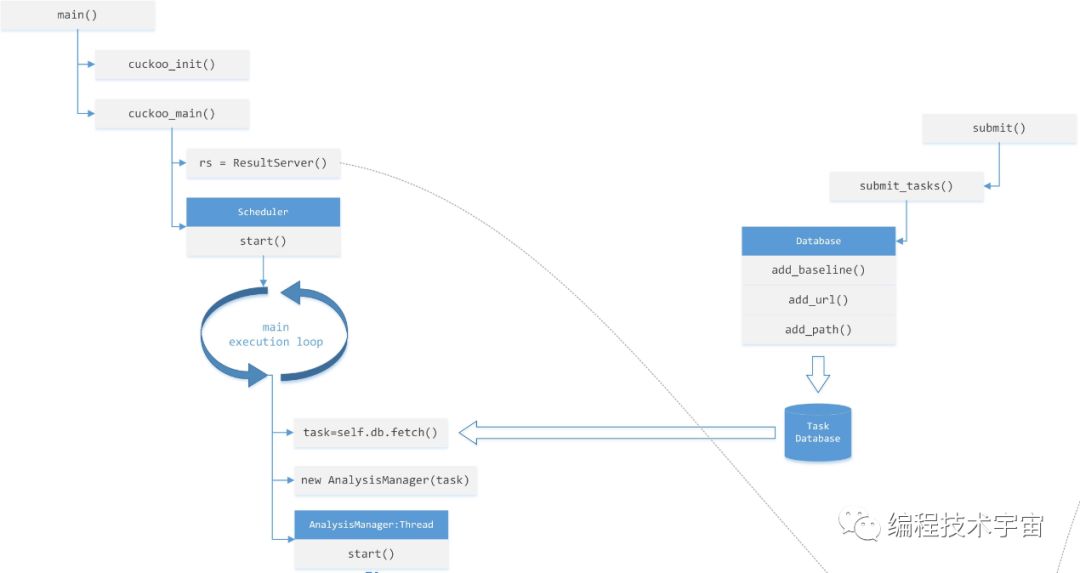
启动是从main.py中的main()开始,首先进行cuckoo_init()初始化,然后进入cuckoo_main()。进入之后,最主要的两件事:
1、通过socket启动一个ResultServer(),用于接收虚拟机中guest发送过来的监测结果,这个后面会用到:
2、紧接着创建任务调度器Scheduler,并调用start方法启动之。启动之后就进入主执行循环,不断的从任务数据库中提取任务并执行。任务的来源通过submit()提交写入数据库,分析的目标可以是文件,可以是域名,也可以是一个目录。
任务的执行部分主要是AnalysisManager类在负责,这个类是继承自Thread,调用start启动该任务。

在AnalysisManager的线程执行函数run()中,主要干了两件事:启动分析和处理分析结果。处理分析结果后面再说,先看启动分析的过程。
通过launch_analysis()函数发起分析,首先申请虚拟机,得到一个Machiney,然后启动虚拟机,顺便提一句,Machinery是一个抽象类,具体实现可以是VirtualBox,也可以是VMware或者其他虚拟机,这取决于你的安装配置文件。
启动虚拟机以后,进入内部函数guest_manage()。
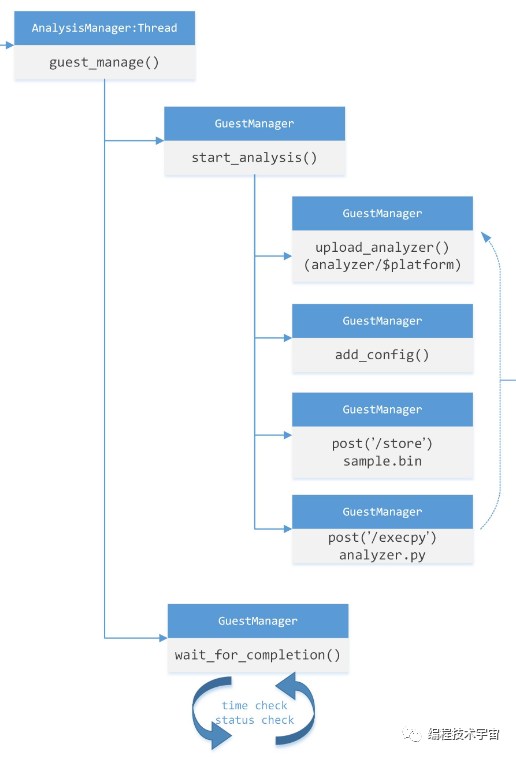
真正向Guest虚拟机发起任务执行的动作,是由类GuestManager完成的,在guest_manage()中间首先调用GuestManger的start_analysis()方法启动分析,启动完成后,再调用其wait_for_complement()进入循环检测,等待分析的完成。
而start_analysis()进来之后,做了4件事:
1、upload_analyzer(): 把虚拟机对应平台(windows/linux/···)的分析器程序代码传上去
2、add_config(): 将本次分析的一些参数设置到guest中去
3、上传待分析的目标样本
4、让虚拟机guest机器执行analyzer.py脚本,流程转入到Guest虚拟机中去
Guest中启动分析流程
上面四步是如何实现的呢?
原来,Guest机器中安装时会事先安装一个代理程序Agent,也是python编写,这个程序随虚拟机自启动,这个Agent用于Guest和Cuckoo Host之间的通信,其主要逻辑就是开启一个web服务,提供RESTful接口,Host通过这些接口来和Agent进行通信,上面的文件上传,就是通过Agent提供的RESTful接口完成的:
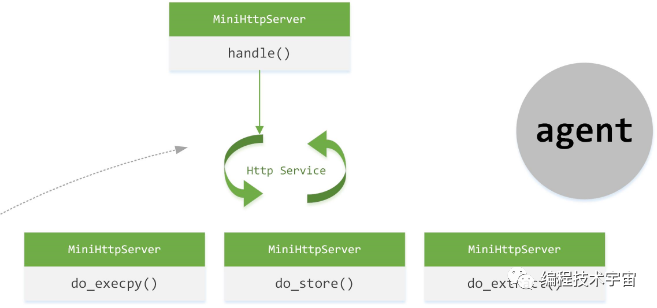
在上面提到的第四步,通过Agent来启动analyzer.py脚本(通过do_execpy()完成),开启在Guest机器上的分析执行。

analyzer.py脚本启动后,通过Analyzer类的run方法,启动分析。在启动目标样本运行前,有许多前置工作需要做:
1、prepare():
- 准备工作,提升当前进程(Analyzer所属的python进程)权限,获得SeDebugPrivilege和SeLoadDriverPrivilege权限,用于后续操作样本所在进程和加载驱动使用。
- 启动两个管道服务器,分别用于和目标样本进程的代码日志传输和函数执行记录传输
2、启动一系列辅助分析工具,Auxiliary为抽象基类,遍历所有该类的子类并启动之,主要包括截屏工具、驱动加载工具等
3、选择package,所谓package,是cuckoo为不同扩展名的文件选定不同的命令来启动分析,比如exe文件,是直接启动,如果是doc,就是office进程,如果是url,就是打开浏览器等等。这些不同的逻辑通过引入一个Package的概念作为基类,使用多态的形式为不同扩展名的文件实现不同的启动方式。
4、调用驱动功能,实现对当前进程(Analyzer进程)和父进程(Agent)的隐藏,防止目标检测到cuckoo的存在。
选定package之后,调用其start方法,正式启动:
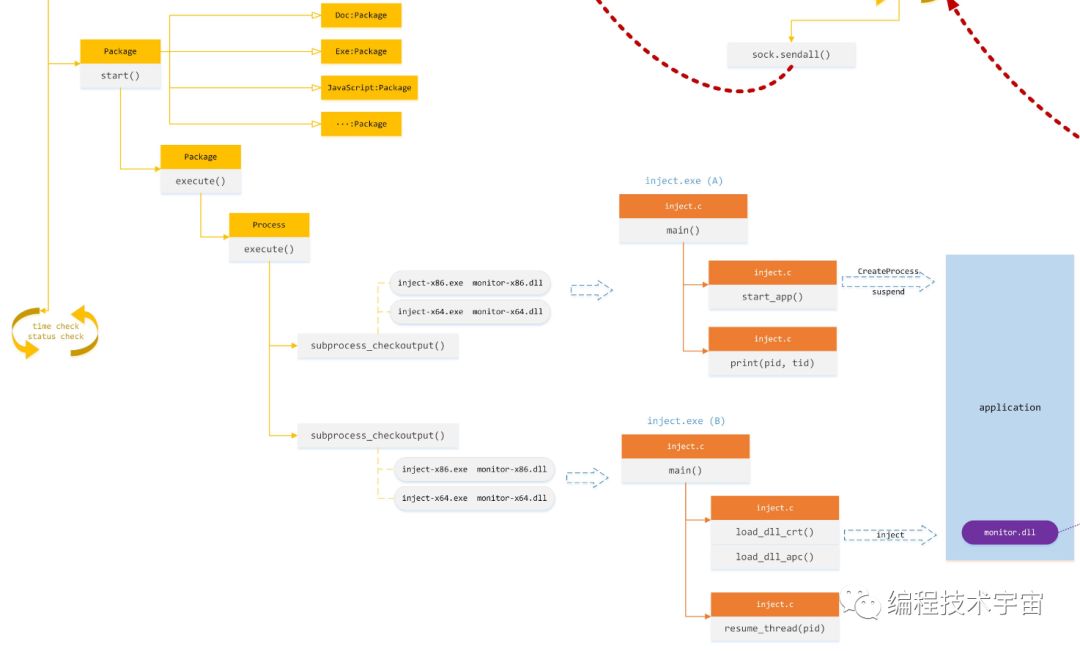
目标样本进程的启动过程还挺复杂,通过一系列的函数封装,进入Process的execute()函数。在这里分为两步进行:
第一步:启动inject-x86/x64.exe作为中间人,它的任务是负责把目标样本的进程给启动,但是将主线程给挂起来suspend,同时把目标样本进程的pid和主线程tid通过print输出,随后便退出。
第二步:再次启动inject-x86/x64.exe作为中间人,这一次它的主要任务是执行注入功能,将cuckoo的核心模块monitor-x86/x64.dll注入到目标样本的进程,注入方式有两种:远程线程注入和apc注入。最后,通过唤醒目标样本进程的主线程,真正让样本run起来了。
注入模块monitor
在目标样本进程中的monitor.dll,在注入的时候做了哪些事情呢?需要注意的是,从inject.exe开始到monitor.dll,其源代码开始使用C语言编写。
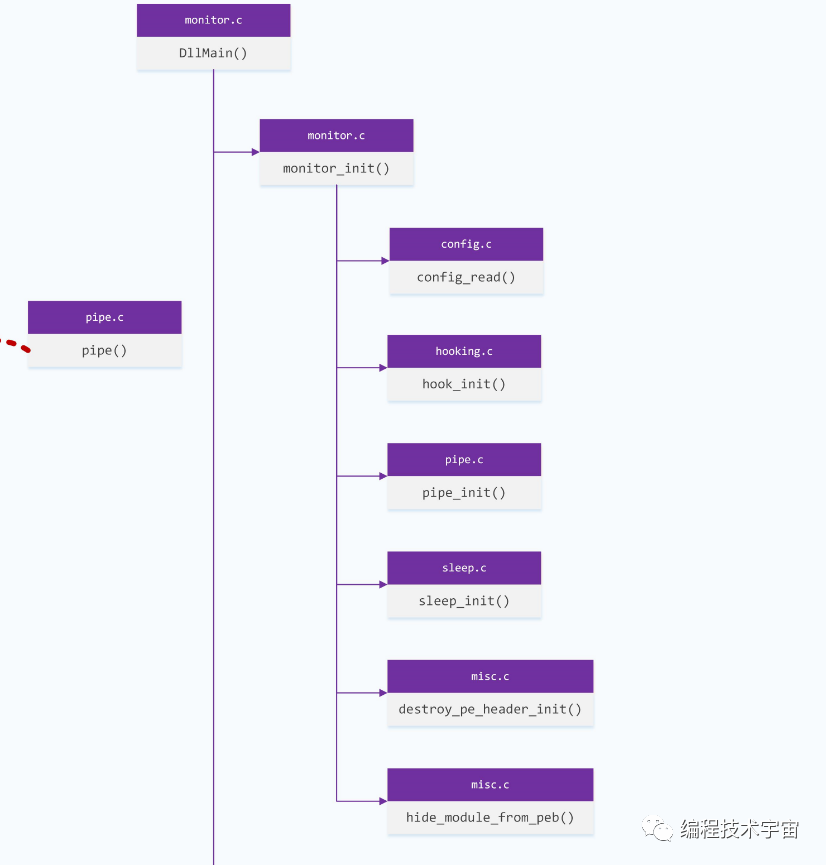
首先是执行monitor_init(),里面有一堆初始化:
1、配置读取初始化
2、hook初始化
3、管道初始化,连接前面Analyzer进程开启的两个管道
4、sleep初始化,针对sleep函数进行特殊处理
5、monitor模块的自我隐藏:抹去PE头数据+从PEB中的模块链表中将自己摘掉
这一系列初始化完成之后,进入monitor_hook()函数:
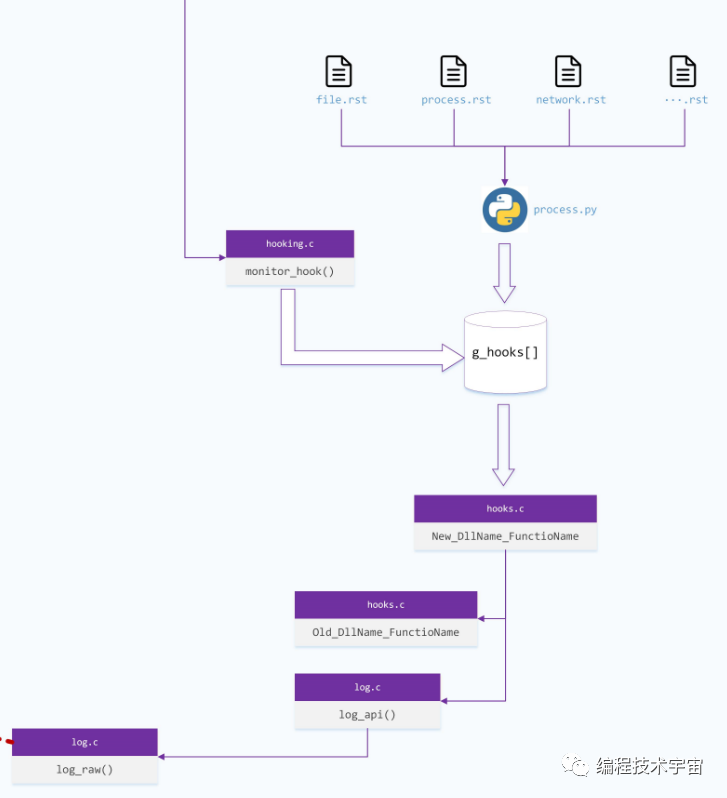
这个函数要做的事情便是非常核心的安装HOOK。
Cuckoo采用了一种非常聪明的方式,将要HOOK的函数定义在rst文件中,根据不同功能分为了file.rst、process.rst、network.rst等等,这些rst文件中罗列了所有需要HOOK的函数的信息,包括函数所在的模块名,函数名称、函数的所有参数信息、函数的返回值等。在monitor.dll在编译之前,先通过提供的工具脚本process.py,将所有rst文件通过一个hooks.c的代码模板渲染出来,得到完整的hooks.c文件,该代码文件里面定义了一个全局的g_hooks的数组,来记录所有待hook的函数信息。
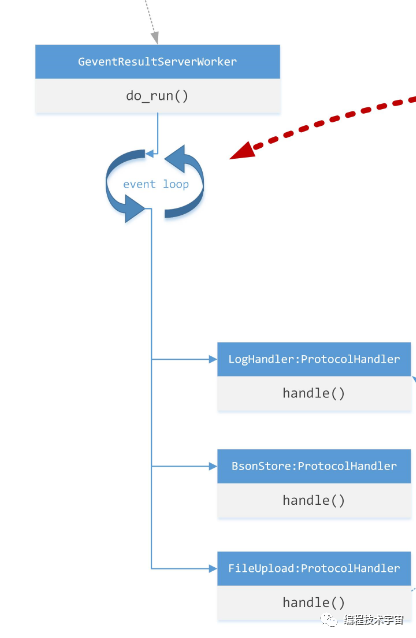
回到monitor_hook()函数,它要做的事情就是遍历这个数组,依次安装HOOK。HOOK后的函数要做的事情也大体类似,首先调用原来真实的函数,然后调用log_api()将这次函数的调用信息记录下来形成日志,转换成bson格式,最终调用log_raw()将数据通过之前Analyzer开辟的管道,发送出去。
在monitor中代码执行的日志和上面api调用记录日志通过不同的管道送到了Analyzer进程,该进程又通过socket连接发送到Cuckoo Host最开始启动的ResultServer中去,至此,完成了目标样本进程的运行信息被虚拟机外的Host服务器掌控。
运行结果分析与处理
样本的运行就说到这里,回到文章最开始说的,cuckoo_main的两件事,第二件就是对运行结果的分析了。
上面说到,Cuckoo Host通过ResultServer获取到了样本执行的情况,它将这些信息写入了Cuckoo工作目录下的storage/analyse/{task_id}下面了,接下来就是对这些数据的分析处理。
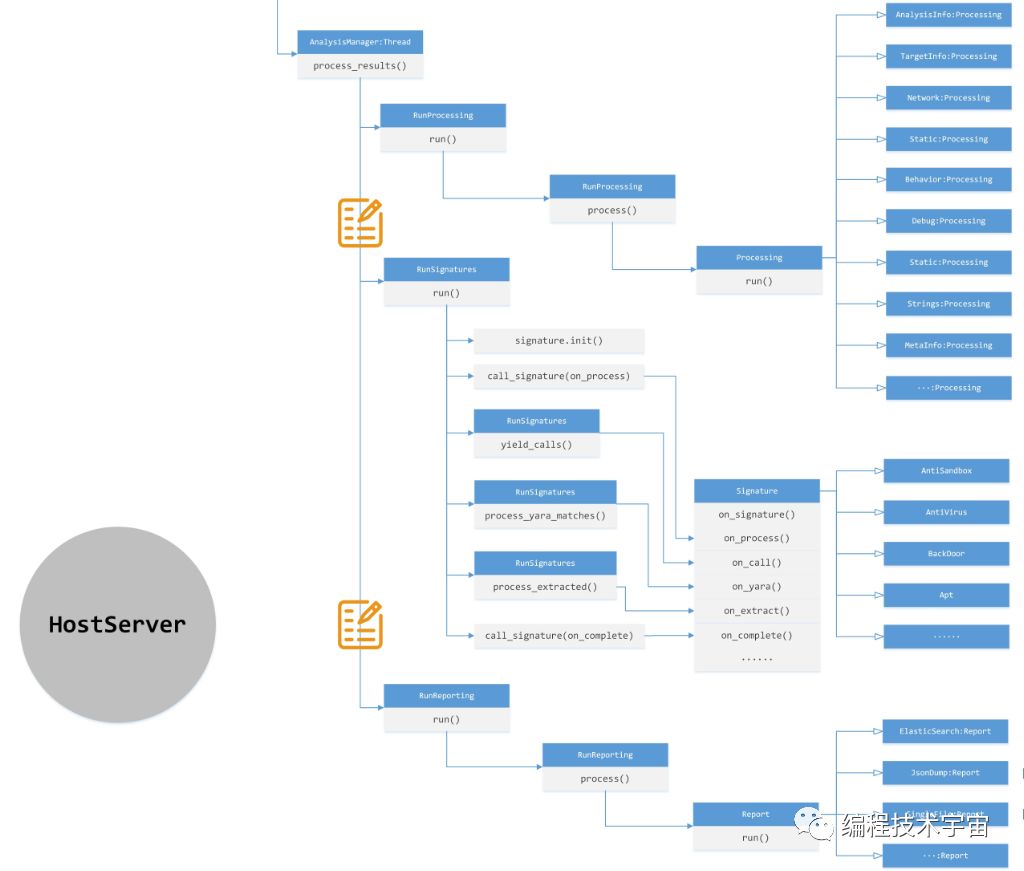
对运行结果的分析是通过process_results()进入。该函数通过三个核心类完成分析处理:
1、RunProcessing,执行处理过程。Cuckoo提供了Processing框架,通过Processing基类派生了很多处理模块,我们可以添加自己的分析模块,继承自Processing即可。每个模块可以对数据进行分析,并选择性的可以产生自己的分析结果,Cuckoo框架会拿到你的结果最终汇集到总的处理结果字典中。
2、RunSignatures,执行特征匹配。Cuckoo提供了特征匹配框架,通过Signature基类派生了很多特征匹配模块,我们同样可以添加自己的特征匹配模块,继承自Signature即可。特征匹配模块提供了丰富的外部调用接口,供Cuckoo框架本身回调。
3、RunReporting,执行结果上报,经过上面两步的分析处理,最终得到的结果需要上报处理了。我们可以选择生成json到文件,也可以选择上传到ElasticSearch非关系型数据库,还可以有我们自定义的上报方式。Cuckoo提供了强大的框架接口供我们实现。
至此,Cuckoo整体的工作流程就分析的差不多了,下面是上面所有流程的全景图: