终于开始攻克并行这一块了,有点小兴奋,来看看网络上R语言并行办法有哪些:
赵鹏老师(R与并行计算)做的总结已经很到位。现在并行可以分为:
隐式并行:隐式计算对用户隐藏了大部分细节,用户不需要知道具体数据分配方式 ,算法的实现或者底层的硬件资源分配。系统会根据当前的硬件资源来自动启动计算核心。显然,这种模式对于大多数用户来说是最喜闻乐见的。
显性并行:显式计算则要求用户能够自己处理算例中数据划分,任务分配,计算以及最后的结果收集。因此,显式计算模式对用户的要求更高,用户不仅需要理解自己的算法,还需要对并行计算和硬件有一定的理解。值得庆幸的是,现有R中的并行计算框架,如parallel (snow,multicores),Rmpi和foreach等采用的是映射式并行模型(Mapping),使用方法简单清晰,极大地简化了编程复杂度。R用户只需要将现有程序转化为*apply或者for的循环形式之后,通过简单的API替换来实现并行计算。
简单总结就是:
隐式并行:OpenBLAS,Intel MKL,NVIDIA cuBLAS,H2O(参考我的博客)等
显性并行:parallel(主打lapply应用)、foreach(主打for循环)、SupR、还有利用GPU的办法(gpuR)
同时并行时对内存的消耗极大,超级容易爆发内存问题,而且R的内存问题一直都是R很难解决的问题,这边笔者也把看到的一些方式列出来。
当然在使用一些高大上的并行包以及框架之前,如果你能够从编码小细节优化,效率也能提高很多,譬如:
方法:速度, nrow(df)/time_taken = n 行每秒
原始方法:1X, 856.2255行每秒(正则化为1)
向量化方法:738X, 631578行每秒
只考虑真值情况:1002X,857142.9行每秒
ifelse:1752X,1500000行每秒
which:8806X,7540364行每秒
Rcpp:13476X,11538462行每秒
apply处理并行——————————————————————————————————————————————————————
在最后笔者在实践中遇到的问题,进行对应的解决:
应用一:使用parallel包时,能不能clusterExport整个函数呢?
应用二:在使用parallel包时,报错:Error in unserialize(node$con) : error reading from connection
——————————————————————————————————
一、parallel包的使用方法
多数内容参考:R语言并行化基础与提高
parallel是base包,所以不用install.packages就可以直接调用。
原理:是利用CPU的核心进行训练。
应用场景:跟apply族(lapply/sapply效果一致)(
R语言︱数据分组统计函数族——apply族用法与心得
)
1、使用步骤
设置核心数:no_cores <- detectCores() - 1
步骤分群环境:cl <- makeCluster(no_cores)
用到的变量与包复制给不同的核心:clusterEvalQ(包)、clusterExport(变量)
运行算法:clusterApply(cl, c(9,5), get("+"), 3)
关闭集群:
stopCluster(cl)就OK啦。但是这里面很从前不一样的是,如果有环境里面的外置变量(自己定义)那么需要额外插入,复制到不同核上面,而且如果有不同包里面的函数,都要额外加载、复制多份给不同的电脑核心。
2、案例
library(parallel)
cl <- makeCluster(getOption("cl.cores", 2))
clusterApply(cl, c(9,5), get("+"), 3) #加减乘除
parSapply(cl, c(9,5), get("+"), 3) 案例一:c1就是设置的核心数,此时是2核心,然后就可以利用clusterApply/parSapply等函数进行调用。
xx <- 1
clusterExport(cl, "xx")
clusterCall(cl, function(y) xx + y, 2)案例二:这个里面有xx这个变量是额外定义的,所以需要额外加载,需要用clusterExport函数,导入到并行环境中。
3、parallel内存优化与管理
(1)注意数据容量的均匀分布
parLapply <- function (cl = NULL, X, fun, ...)
{
cl <- defaultCluster(cl)
do.call(c, clusterApply(cl, x = splitList(X, length(cl)),
fun = lapply, fun, ...), quote = TRUE)
}
注意到splitList(X, length(cl)) ,他会将任务分割成多个部分,然后将他们发送到不同的集群中。这里一个问题就是,譬如假设有一个list,里面数据量分别是:</p><p>(99,99,99,2,5,2)
如果是两个核数据分为了(99,99,99)、(2,5,2),第一个核分为到了那么多任务,第二个核很少,那么就会空闲,于是乎,效率还是不高,所以数据容量要尽量均匀分布。
(2)集群内存类型:FORK和PSOCK
FORK适用unix/max,实现内存共享以及节省内存,大数据环境下内存问题报错少
PSOCK适用所有(一般window都是这个)
parallel包中通过函数来设置:
makeCluster(4,type="FORK")
FORK对性能提升很显著,但是window下不可适用。
4、parallel万一报错了咋办?
lapply在使用的时候也会出现这样的问题,如果出现问题,那么就白跑了,而且也不可能给你停顿下来。那么如何让lapply运行中跳过报错的办法呢?
R语言相关的报错处理函数可见:R语言-处理异常值或报错的三个示例
用tryCatch跳过:
result = tryCatch(
{expr},
warning = function(w) {warning-handler-code},
error = function(e) { error-handler-code},
finally = {cleanup-code}
)
出现warning、error时候怎么处理,就可以跳过了。例子:
result = tryCatch(
{segmentCN(txt)},
warning = function(w) {"出警告啦"},
error = function(e) { "出错啦"},
)分词时候,容易因为Lapply中断之后,就不会运行了,这样功亏一篑所以可以用这个办法跳过。
5、parSapply/parLapply函数使用技巧
函数的大体结构是:
parSapply(cl,x,fun) 其中cl是预先设定好的,x是需要循环的变量,而fun是函数。</p><p> 那么一般来说,fun之中要使用的任何内容都需要用clusterEvalQ(包)、clusterExport(变量)复制到不同的核心之中。</p><p> 而x则可以不用布置到全局,因为他是在源环境下调用出来,并拆分任务的。</p><p>——————————————————————————————————
二、foreach包的使用方法
1、简单使用案例
设计foreach包的思想可能想要创建一个lapply和for循环的标准,初始化的过程有些不同,你需要register注册集群:
library(foreach) library(doParallel)
cl<-makeCluster(no_cores)
registerDoParallel(cl)
要记得最后要结束集群(不是用stopCluster()):
stopImplicitCluster()foreach函数可以使用参数.combine控制你汇总结果的方法:
> foreach(exponent = 2:4,
.combine = c) %dopar%
base^exponent
[1] 4 8 16> foreach(exponent = 2:4, .combine = rbind) %dopar% base^exponent
[,1]
result.1 4 result.2 8 result.3 16foreach(exponent = 2:4, .combine = list, .multicombine = TRUE) %dopar% base^exponent
[[1]]
[1] 4 [[2]]
[1] 8 [[3]]
[1] 16注意到最后list的combine方法是默认的。在这个例子中用到一个.multicombine参数,他可以帮助你避免嵌套列表。比如说list(list(result.1, result.2), result.3) :
> foreach(exponent = 2:4,
.combine = list) %dopar%
base^exponent
[[1]]
[[1]][[1]]
[1] 4[[1]][[2]]
[1] 8
[[2]]
[1] 16
2、变量作用域
在foreach中,变量作用域有些不同,它会自动加载本地的环境到函数中:
> base <- 2
> cl<-makeCluster(2)
> registerDoParallel(cl)
> foreach(exponent = 2:4,
.combine = c) %dopar%
base^exponent
stopCluster(cl)
[1] 4 8 16但是,对于父环境的变量则不会加载,以下这个例子就会抛出错误:
test <- function (exponent) {foreach(exponent = 2:4,
.combine = c) %dopar%
base^exponent
}
test()
Error in base^exponent : task 1 failed - "object 'base' not found"
为解决这个问题你可以使用.export这个参数而不需要使用clusterExport。注意的是,他可以加载最终版本的变量,在函数运行前,变量都是可以改变的:
base <- 2
cl<-makeCluster(2)
registerDoParallel(cl)base <- 4
test <- function (exponent) {
foreach(exponent = 2:4,
.combine = c,
.export = "base") %dopar%
base^exponent
}
test()stopCluster(cl)
[1] 4 8 16
相似的你可以使用.packages参数来加载包,比如说:.packages = c("rms", "mice")
——————————————————————————————————
三、SupR
通过对现有R 内核的改进实现在单机上的多线程和在集群上的分布式计算功能。SupR目前仍处在内部试用和补充完善阶段。
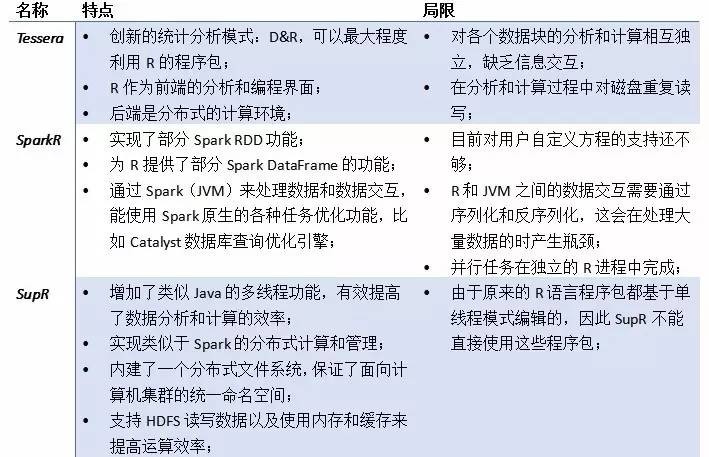
据说supR很好用,而且小象学院的讲师(游皓麟)已经开始教授这个系统的使用方法,挺好用的。
——————————————————————————————————
四、内存管理
方法有三: 一、升级硬件 二、改进算法 三、修改操作系统分配给R的内存上限, memory.size(T)查看已分配内存
memory.size(F)#查看已使用内存
memory.limit()#查看内存上限
object.size()#看每个变量占多大内存。
memory.size()#查看现在的work space的内存使用
memory.limit()#查看系统规定的内存使用上限。如果现在的内存上限不够用,可以通过memory.limit(newLimit)更改到一个新的上限。注意,在32位的R中,封顶上限为4G,无法在一个程序上使用超过4G (数位上限)。这种时候,可以考虑使用64位的版本。
详情看:R语言︱大数据集下运行内存管理 以及 R语言之内存管理
——————————————————————————————————
应用一:使用parallel包时,能不能clusterExport整个函数呢?
R语言在使用Parallel时候,会出现这样的疑问,一些东西都需要广播给不同的核心,那么在clusterExport步骤怎么办呢?能不能clusterExport一整个函数?然后直接parLapply呢?
答案否定的。笔者在用的时候,怎么样都不能把整个函数加载进去,所以只能另想办法。
既然不能clusterExport整个函数,那就只能改造我们的函数去适应parallel包了。
来看几个函数“被”改造的例子,一般来说有两个办法:
1、方法一:通过.GlobalEnv广播成全局变量
clusterExport(cl=cl, varlist=c("text.var", "ntv", "gc.rate", "pos"), envir=environment())
在函数导入的时候,加入envir变量让其广播给不同的核心,这个可以放在函数之中来使用。</p><h3 id="dlv3k" name="2%E3%80%81%E6%96%B9%E6%B3%95%E4%BA%8C%EF%BC%9A%E6%8A%8AparLapply%E5%B5%8C%E5%A5%97%E8%BF%9B%E5%87%BD%E6%95%B0%E4%B9%8B%E4%B8%AD">2、方法二:把parLapply嵌套进函数之中</h3><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0">par.test <- function(text.var, gc.rate=10){
require(parallel)
pos <- function(i) {
paste(sapply(strsplit(tolower(i), " "), nchar), collapse=" | ")
}
cl <- makeCluster(mc <- getOption("cl.cores", 4))
parLapply(cl, text.var, function(text.vari, gc.rate, pos) {
x <- pos(text.vari)
if (i%%gc.rate==0) gc()
x
}, gc.rate, pos)
}
可以看到的这个例子,就是把内容嵌套到parLapply之中了。同时也可以学习到,parLapply使用方法也很不错,也可以学习一下。</p><p> 再来看一个例子:</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0">mainFunction <- function(cl) {
fa <- function(x) fb(x)
fb <- function(x) fc(x)
fc <- function(x) x
y <- 7
workerFunction <- function(i) {
do.call(functionNames[[i]], list(y))
}
environment(workerFunction) <- .GlobalEnv
environment(fa) <- .GlobalEnv
environment(fb) <- .GlobalEnv
environment(fc) <- .GlobalEnv
functionNames <- c("fa", "fb", "fc")
clusterExport(cl, varlist=c("functionNames", functionNames, "y"),
envir=environment())
parLapply(cl, seq_along(functionNames), workerFunction)
}
library(parallel)
cl <- makeCluster(detectCores())
mainFunction(cl)
stopCluster(cl)
——————————————————————————————————
应用二:在使用parallel包时,报错:Error in unserialize(node$con) : error reading from connection
在R语言中使用并行算法的时候,会出现报错,无法连接到核心,即使在本来连接上的时候。通过查阅文献看到了,这是因为“调用核心数--计算机内存”的不匹配造成的。
如果你的数据集很大,调用了很多核心,那么你的计算机内存如果不够匹配,就会出现连接不上的不错,甚至还出现卡机,一动不动的情况(当然,只要耐心等待,其实他还是会继续运行的...等待的时候会有点长)
解决办法一:调用FORK,window不能...
FORK适用unix/max,实现内存共享以及节省内存,大数据环境下内存问题报错少
PSOCK适用所有(一般window都是这个)
不过调用FORK也还是治标不治本。
解决办法二:分开并行,小步迭代
譬如10万数据,那么就“2万+2万+2万+2万+2万”的跑,如果还出现脱机,就用之前tryCatch跳过,让损失降低到最小。
最好的办法了。
参考文献:How-to go parallel in R – basics + tips
——————————————————————————————————
参考文献
1、R语言并行化基础与提高
2、R与并行计算
3、sparklyr包:实现Spark与R的接口,会用dplyr就能玩Spark
4、Sparklyr与Docker的推荐系统实战
5、R语言︱H2o深度学习的一些R语言实践——H2o包
6、R用户的福音︱TensorFlow:TensorFlow的R接口
7、mxnet:结合R与GPU加速深度学习
8、碎片︱R语言与深度学习