编者按
北京时间,9月21凌晨,NVIDIA GTC 2022秋季发布会上,CEO黄仁勋发布了其2024年将推出的自动驾驶芯片。因为其2000TFLOPS的性能过于强大,英伟达索性直接把它全新命名为Thor,代替了之前1000TOPS的Altan。
Thor的发布,代表着在汽车领域,已经由分布式的ECU、DCU转向了完全集中的功能融合型的单芯片。也预示着一个残酷的现实:“许多做DCU级别的ADAS芯片公司,产品还在设计,就已经落后”。
云和边缘计算的数据中心,以及自动驾驶等超级终端领域,都是典型的复杂计算场景,这类场景的计算平台都是典型的大算力芯片。
大芯片的发展趋势已经越来越明显的从GPU、DSA的分离趋势走向DPU、超级终端的再融合,未来会进一步融合成超异构计算宏系统芯片(Macro-SOC)。
1 NVIDIA自动驾驶芯片Thor
1.1 自动驾驶汽车芯片的发展趋势

上图是BOSCH给出的汽车电气架构演进示意图。从模块级的ECU到集中相关功能的域控制器,再到完全集中的车载计算机。每个阶段还分了两个子阶段,例如完全集中的车载计算机还包括了本地计算和云端协同两种方式。

上图是NVIDIA Altan的芯片架构示意图(Thor刚出来,没有找类似的图),从此图可以看出:Altan&Thor的设计思路是完全的“终局思维”,相比BOSCH给出的一步步的演进还要更近一层,跨越集中式的车载计算机和云端协同的车载计算机,直接到云端融合的车载计算机。云端融合的意思是服务可以动态的、自适应的运行在云或端,方便云端的资源动态调节。Altan&Thor采用的是跟云端完全一致的计算架构:Grace-next CPU、Ampere-next GPU以及Bluefield DPU,硬件上可以做到云端融合。
1.2 Intel Mobileye、高通和NVIDIA芯片算力比较

我们可以看到,Mobileye计划2023年发布的用于L4/L5的最高算力的EyeQ Ultra芯片只有176 TOPS。
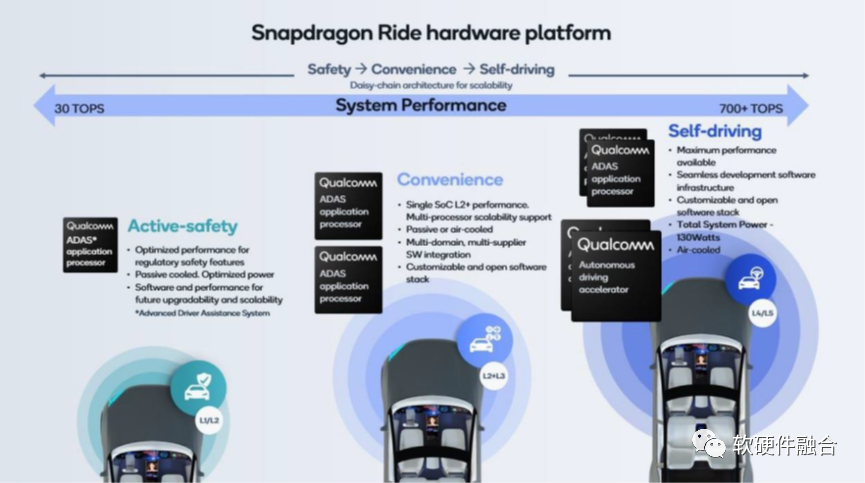
从上图我们可以看到,高通计划的L4/L5自动驾驶芯片是700+TOPS,并且是通过两颗AP和两个专用加速器共四颗芯片组成。
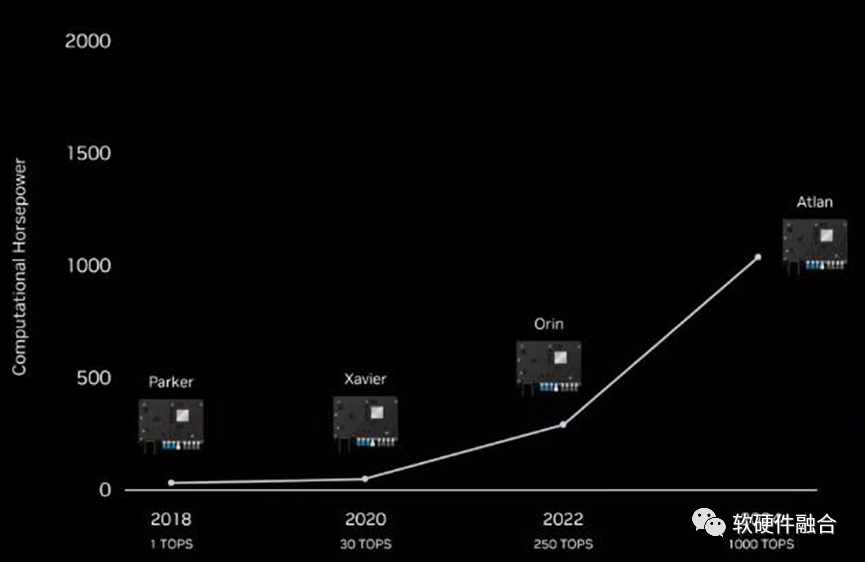
再对照NVIDIA Altan,之前计划的用于L4/L5自动驾驶芯片Altan是1000TOPS算力。

NVIDIA的王炸!推翻了之前的Altan,直接给了一个全新的命名Thor(雷神索尔),其算力达到了惊人的2000TOPS。

NVIDIA Thor发布之后,高通“快速”的发布了自己的4芯片2000TOPS算力的解决方案。
1.3 单芯片实现通常5颗以上芯片的多域计算

NVIDIA Thor提供2000TFLOPS的算力(相比较Atlan提供的2000TOPS)。

Thor SoC能够实现多域计算,它可以为自动驾驶和车载娱乐划分任务。通常,这些各种类型的功能由分布在车辆各处的数十个控制单元控制。制造商可以利用Thor实现所有功能的融合,来整合整个车辆,而不是依赖这些分布式的ECU/DCU。

这种多计算域隔离使得并发的时间敏感的进程可以不间断地运行。通过虚拟化机制,在一台计算机上,可以同时运行Linux、QNX和Android等。
参考文献
https://mp.weixin.qq.com/s/KKJ0hsxvOoIhBgMPMgcEgQ,英伟达发布最强汽车芯!算力2000TOPS,车内计算全包了,车东西
https://mp.weixin.qq.com/s/lA8h9jTtgsPIjYAX3p5cvg,英伟达「史诗级」自动驾驶芯片亮相!算力2000TOPS,兼容座舱娱乐功能,新智驾
2 自动驾驶SOC和手机SOC的本质区别
这里我们给出一个概念:复杂计算。复杂计算指的是,在传统AP/OS系统之上,还需要支持虚拟化、服务化,实现单设备多系统共存和跨设备多系统协同。因此,如果把AP级别的系统看做一个系统的话,那么复杂计算是很多个系统组成的宏系统。
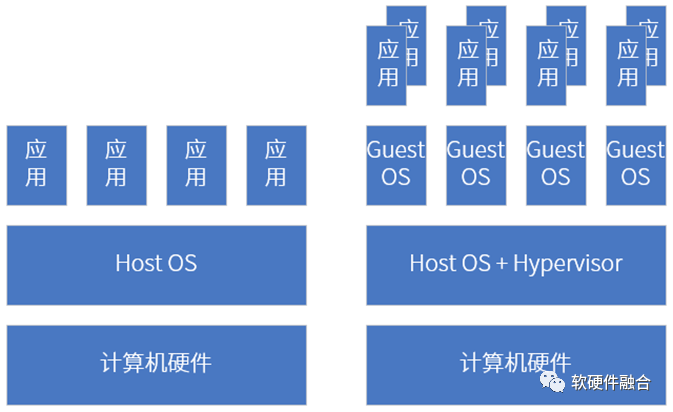
手机、平板、个人电脑等传统AP上部署好操作系统之后,我们在上面运行各种应用软件。整个系统是一个整体,各个具体的进程/线程会存在性能干扰的问题。
但在支持完全硬件虚拟化(包括CPU、内存、I/O、各种加速器等的完全硬件虚拟化)的平台下,不仅仅是要把宏系统切分成多个独立的系统,并且各个系统之间是需要做到应用、数据、性能等方面的物理隔离。
自动驾驶汽车,通常需要支持五个主要的功能域,包括动力域、车身域、自动驾驶域、底盘域、信息娱乐域。因此,集中式的自动驾驶汽车超级终端芯片,必须要实现完全的硬件虚拟化,必须要支持各个功能域的完全隔离(相互不干扰)。
我们把这一类虚拟化和多系统的计算场景称为复杂计算,支持复杂计算的芯片才能算是“大”芯片。这类场景目前主要包括:云计算、超算、边缘计算、5G/6G核心网的数据中心,以及自动驾驶、元宇宙等场景的超级终端。
3 绝对的算力优势面前,定制ASIC/SOC没有意义
随着云计算的发展,随着云网边端不断的协同甚至融合,随着系统的规模越来越庞大,ASIC和传统基于ASIC的SOC的发展道路越来越走向了“死胡同”。越简单的系统,变化越少;越复杂的系统,变化越多。复杂宏系统,必然是快速迭代,并且各个不同的用户有非常多差异性的,传统ASIC的方式在复杂计算场景,必然遇到非常大的困境。
在自动驾驶领域,在不采用加速引擎的情况下,传统的SOC可以把AI算力做到10 TOPS左右;很多公司通过定制加速引擎的方式,快速的提升算力,可以把AI算力提升到100甚至200 TOPS。然而,传统SOC的实现方式有很多问题:
- 自动驾驶的智能算法以及各类上层应用,一直在快速的演进升级中。定制ASIC的生命周期会很短,因为功能确定,车辆难以更新更先进的系统升级包,这样导致ASIC无法很好的支持车辆全生命周期的功能升级。
- 整个行业在快速演进,如果未来发展到L4/L5阶段,目前的所有工作就都没有了意义:包括芯片架构、定制ASIC引擎,以及基于此的整个软件堆栈及框架等,都需要推倒重来。
越来越体会到,在大芯片上,做定制ASIC是噩梦;现实的情况,需要是某种程度上软硬件解耦之后的实现通用芯片。只有软硬件解耦之后:硬件人员才能放开手脚,拼命的堆算力;软件人员才能更加专心于自己的算法优化和业务创新,而不需要关心底层硬件细节。
在同样的资源代价下,通用芯片为了实现通用,在性能上存在一定程度的损失。因此,做通用大芯片,也需要创新:
- 需要创新的架构,实现足够通用的同时,最极致的性能以及性能数量级的提升;
- 需要实现架构的向前兼容,支持平台化和生态化设计;
- 需要站在更宏观的视角,实现云网边端架构的统一,才能更好的构建云网边端融合和算力等资源的充分利用。
在绝对的算力优势面前,一切定制芯片方案都没有意义。
4 大芯片的发展趋势:从分离到融合

计算机体系结构在从GPU和DSA的分离向融合转变:
- 第一阶段,CPU单一通用计算平台;
- 第二阶段,从合到分,CPU+GPU/DSA的异构计算平台;
- 第三阶段,从分到合的起点,以DPU为中心的异构计算平台;
- 第四阶段,从分到合,众多异构整合重构的、更高效的超异构融合计算平台。

自动驾驶领域已经是Thor这样的功能融合的独立单芯片了,在边缘计算和云计算场景,独立单芯片还会远吗?
在边缘计算等轻量级场景,可以通过功能融合的独立单芯片覆盖;在云计算业务主机等重量级场景,可以通过Chiplet的方式实现功能融合的单芯片。
5 各领域大芯片发展趋势
开门见山,简而言之。大芯片的发展趋势就是:功能融合的、超异构计算架构的单芯片MSoC。

上图为基于CPU+GPU的异构计算节点的天河1A超级计算机架构图。

E级的天河三依然是异构计算架构。

最新TOP500第一名的Frontier,也选择的是基于AMD处理器的异构计算架构(每个节点配备一个 AMD Milan “Trento” 7A53 Epyc CPU 和 四个AMD Instinct MI250X GPU,GPU核心总数达到了37,632)。

日本的富岳超算所采用的ARM A64FX处理器,是在常规的ARMv8.2-A指令集的基础上扩展了512Bit的SIMD指令,也可以看做是某种形态上的异构计算。
总结一下,在超算领域,千万亿次、百亿亿次(E级)超算使得异构计算成为主流。下一代超算,是十万亿亿次(Z级),几乎所有的目光都投向了超异构计算。
自动驾驶领域,NVIDIA Drive Thor提供2000TOPS的算力(目前,主流自动驾驶芯片AI算力为100TOPS),Thor之所以能有如此高的算力,跟其内部GPU集成的Tensor Core有很大的关系。Thor是功能融合的单芯片,其架构由集成的CPU、GPU和DPU组成,可以看做是超异构SOC。
在云和边缘服务器侧,CPU、GPU和DSAs融合的趋势也越来越明显,预计未来3年左右,服务器端独立单MSoC芯片(或者说超异构计算芯片)会出现。
6 大芯片需要考虑计算资源的协同和融合
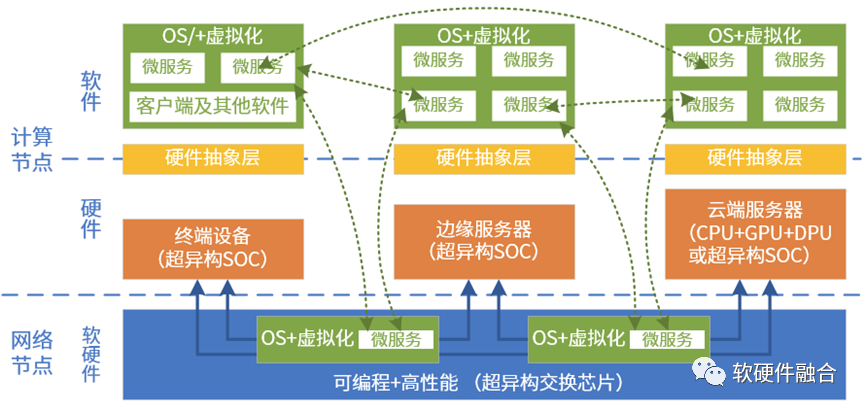
大芯片,担负着宏观算力提升的“重任”。
如果计算资源是一个个孤岛,那就没有宏观算力的说法。宏观算力势必需要各个计算节点芯片的协同甚至融合。这就需要考虑计算的跨云网边端。
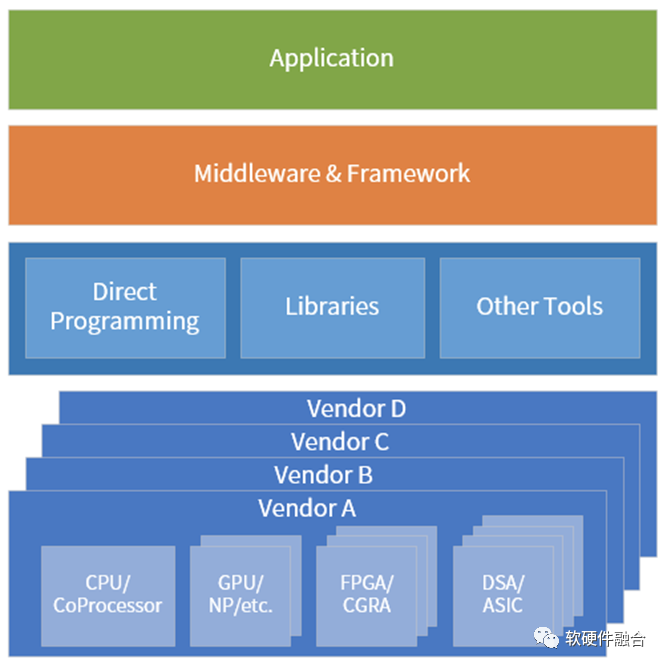
异质的引擎架构越来越多,计算资源池化的难度也越来越高。在超异构计算时代,要想把异质的资源池化,计算需要做到:
- 维度一:跨同类型处理器架构。如软件可以跨x86、ARM和RISC-v CPU运行。
- 维度二:跨不同类型处理器架构。软件需要跨CPU、GPU、FPGA和DSA等处理器运行。
- 维度三:跨不同的芯片平台。如软件可以在Intel、AMD和NVIDIA等不同公司的芯片上运行。
- 维度四:跨云网边端不同的位置。计算可以根据各种因素的变化,自适应的运行在云网边端最合适的位置。
- 维度五:跨不同的云网边服务供应商、不同的终端用户、不同的终端设备类型。
(全文完)