作者简介:kevinxiaoyu,高级研究员,隶属腾讯TEG-架构平台部,主要研究方向为深度学习异构计算与硬件加速、FPGA云、高速视觉感知等方向的构架设计和优化。“深度学习的异构加速技术”系列共有三篇文章,主要在技术层面,对学术界和工业界异构加速的构架演进进行分析。
在前面的论述中,主要在解决带宽这一核心问题的层面,对学术界涌现的典型架构进行讨论。在本篇中,将走进工业界,看一看半导体厂商和互联网巨头在AI计算中的不同选择。
一、半导体厂商的抉择
不同厂商有不同的应用场景,而适合构架和解决方案也各不相同,如云侧和端侧处理构架的设计导向差别较大。对于半导体领域,只要市场规模足够大,有足够多的客户买单,那么就有足够的动力去做相应的硬件定制。下面对以Nvidia和Intel为代表的半导体厂商方案进行论述。
1.1、NVIDIA
NVIDIA的应用场景是图像计算和海量数据并行计算。GPU是异构计算的主力,AI的兴起之源,生态发展得非常成熟,从开发流程到各种库的支持都非常完善。针对深度学习,NVIDIA的思路是延续其一直以来的GPU构架,并在两个方向发力,即丰富生态,和提升深度学习领域的定制性。对于前者,推出cuDNN等针对神经网络的优化库,提升易用性并针对GPU的底层结构进行优化;对于后者,一方面不再坚持32位浮点运算,增加对更多数据类型的支持,如16位浮点和8位定点等;另一方面通过添加深度学习专用模块(如V100中的TensorCore)强化定制性,来大幅提升在深度学习应用中的性能。其2017年5月发布的Volta V100在深度学习的应用中可达120TFlops的强悍算力,参数和构架分别如图3.1、图3.2所示。
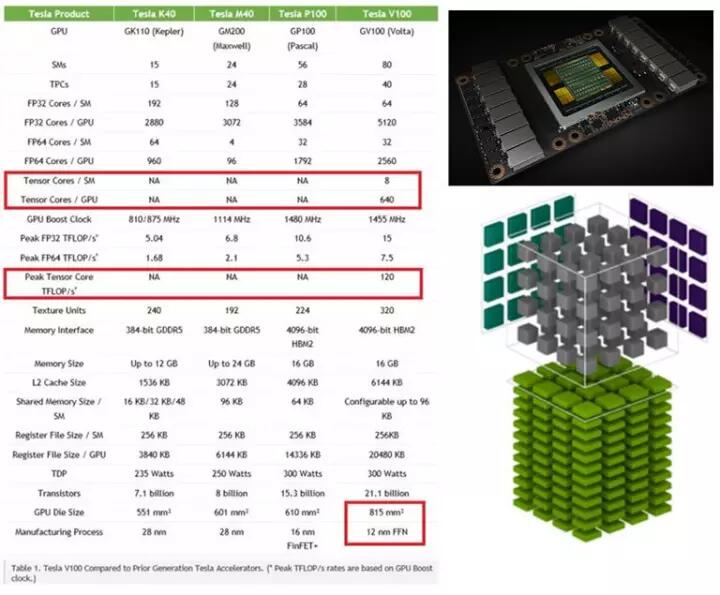
图3.1 Volta GPU参数对比,与TensorCore的计算结构
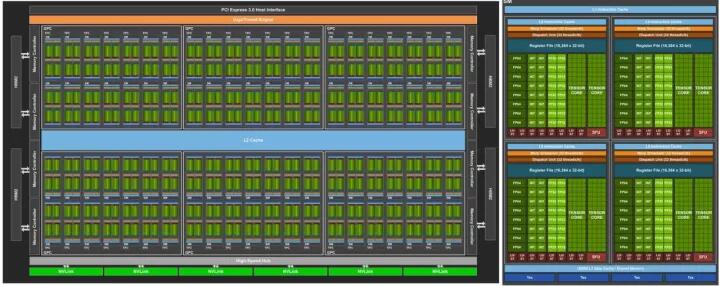
图3.2 Volta GPU构架
GPU的问题在于:延迟大、能耗比低、成本较高。
为了解决大量内核同时运行导致的带宽问题,一方面GPU采用类似CPU片内多级缓存的方案,构成临近存储;另一方面,采用最先进的存储器技术,从而在计算时可以跑满更多的Core。当众多Core同时访问显存时,队列机制导致对每个Core的请求无法第一时间响应,从而增大了任务处理的延迟。
从定制性和计算粒度上看,GPU的应用对象为通用并行计算,为了兼容前期构架和更多应用,在设计上存在一定的平衡和冗余。例如在图3.1图3.2中,Tensor Core专为AI计算而设计,其他的5120个计算内核更多是为了兼容通用并行计算。因此在同等芯片面积和晶体管数量下,其性能功耗比AI专用处理器并不占优势。
从成本上看,目前Tesla V100的单卡成本估计为10万以上,其他型号也在几千到数万,在云端大规模部署时成本过于昂贵。
由于历史设计的延续性,NVIDIA的GPU主要针对服务器和桌面机,即使推出了低功耗的TX、TK系列,也是主要针对功耗不太敏感的高性能终端应用,如无人驾驶等。当新兴领域出现,为了保证在计算平台领域产品线的完整,嵌入式市场的竞争力不可或缺。对此,NVIDIA的做法让人眼前一亮——开源了一套全新的算力可伸缩的深度学习处理器构架:DLA(Deep Learning Accelerator)。通常,开源的方式在轻量级开发的软件层面比较普遍。由于投入大、门槛高、容错性差等原因,硬件架构的开源还处于起步阶段。DLA成为NVIDIA将生态扩展到嵌入式端的有力武器,避开了和AI计算众多创业公司的正面对抗,老黄的魄力和想象空间令人赞叹。DLA的RTL构架详见https://github.com/nvdla/
1.2、Intel
作为通用计算平台供应商,Intel更不会放弃任何一个大规模的计算平台市场。在第一篇中提到,用CPU来做进行大规模深度学习计算是低效的。面对GPU可兼容深度学习,可轻量级切入的优势,Intel开始了“买买买”的战略。在异构计算方面,收购了第二大FPGA公司Altera;在云端深度学习的应用场景,收购了Nervana;在低功耗嵌入式前端的深度学习应用场景,收购了Movidius;在无人/辅助驾驶的终端应用,收购了Mobileye。
在Intel的预期中,FPGA/AI ASIC可通过QPI接口与至强处理器进行芯片级互联(带宽可达PCIE4.0的2倍),甚至集成在同一芯片上。尽管目前合封难度较大而延期,但并不妨碍评估其设计的收益:对于云端和桌面机这种计算类型不断变化的场景,一个高带宽、低延迟、可重构的协处理器总是令人期待的,如图3.3所示:


图3.3 Intel在Datacenter中的异构计算布局
Intel-Lake Crest:Intel在2017年10月推出的Lake Crest深度学习芯片,同样属于第二阶段,算力可伸缩的AI处理器。具备32GB的片上HBM2,同时具备DNN加速和芯片级互联能力。由于HBM2取代了片外DDR,极大提升了板级的集成度,同时降低了功耗,可适用单卡多片、一机多卡、芯片池化的系统构架。Lake Crest的内部构架如图3.4所示。

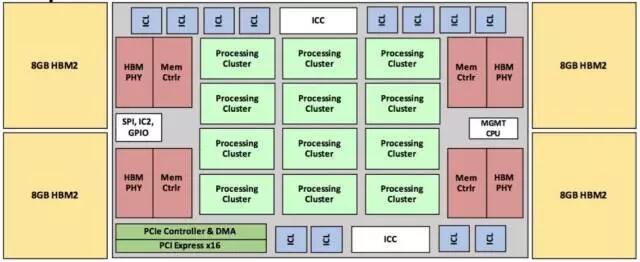
图3.4 Intel ASIC Lake Crest 内部结构
Movidius:针对低功耗的嵌入式前端应用。这部分市场规模相当大,包括机器人、无人机/车、安防,甚至个人便携式加速设备。例如,Movidius已推出神经计算棒,针对便携个人深度学习开发,实现1W功耗下100GFlops的性能。这里注意一下,这里的能耗是指便携式设备的整体能耗。在深度学习定制芯片本身实现100GFlops/W相对容易,但算上供电、控制、片外存储等芯片后,这个性能就相当不易了,如图3.5所示。

图3.5Movidius 的神经计算棒
二、互联网巨头的抉择
2.1、Google
Google非常重视对前沿领域的探索和布局。早在2013年即意识到AI在业务上将有爆发式增长,不仅内部业务开发需要大量计算资源,对外也需要提供多种AI场景的服务,若使用GPU则成本过高,也不利于丰富AI生态的上下游。完整的从深度学习框架到计算平台的产品线,更有利于掌握主动权,并实现端到端的应用模式。因此,一方面开始TPU的研制,以其实现与GPU相同性能下成本降低10倍;另一方面开发TensorFlow以及TensorFlow到TPU的编译环境,借助TF和深度学习云服务的推行而推动TPU的应用,从而进一步提升TPU的使用量来均摊设计成本。目前,TPU已推出第二代(后文中称为TPU2),对内应用于搜索、地图、语音等业务;对外向研究机构开放TPU2的使用申请,营造深度学习端到端的生态链。在深度学习领域,如何将抢到并利用先机,完善生态,快速产品化,是Google关注的核心。因此,AI+硬件,或者说应用+硬件的深度结合成为Google IO大会主题“AI First”走向落地,从生态走向应用的关键。如云端的TPU,嵌入式应用端的智能音箱Google Home、Pixel2手机中的IPU等,都是贯穿这一思路的具体体现。
2.1.1 计算特性与构架变迁——TPU1[1]
Google的TPU经过了TPU1、TPU2两代,属于典型的AI芯片从第一阶段解决带宽到第二阶段算力伸缩的过度,从松散分布走向算力密集的集群,从传统网络的数据交互走向超低延迟的芯片级互联。
TPU1的构架和板级结构分别如图3.6、图3.7所示。TPU1仅实现Inference功能,可支持16bit/8bit运算,主要完成矩阵-矩阵乘、矩阵-向量乘、向量-向量乘等功能,来支持MLP(多层感知机)、LSTM和CNN等深度学习算法。为了快速部署减少数据中心的构架变动,TPU1的硬件以PCIE卡的方式与服务器通信,板卡上配置了两组DDR3存储器。
从内部来看,其构架特点是超大规模的脉动阵列(65536个8bit DSP,对应FPGA VU9P DSP数量为68402,Tesla P40 为38404)和24MB片上缓存-片外DDR的存储构架,工作频率为700MHz,峰值计算能力为655360.7Ghz2/1000=91.75Tops,功耗仅40W。之所以能达到如此高的性能而避免了带宽瓶颈,关键在于脉动阵列的计算过程具有极高的数据复用特性,详见第二篇的2.1节。
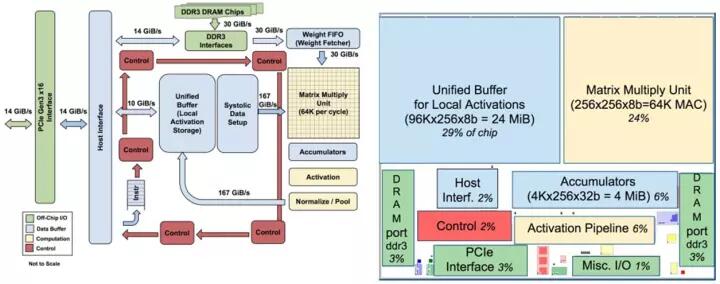
图3.6 TPU1内部结构和片内布局

图3.7 TPU1的板级结构和部署
TPU1具有相当强悍的峰值计算能力,然而在实际应用中却出现了问题:
1 TPU1论文中提到,经统计,Datacenter上更多的客户关注的是处理延迟 (Latency),而不是更大的吞吐量 (Throughput)。TPU推出后,客户在使用中常常将延迟选项设为最高优先级。
2 CNN、LSTM和MLP在应用中,对应的计算效率分别为78.2%,8.2%和12.7%,这得益于CNN可以在片上实现较高的数据复用率。Google给出其数据中心上述三者的应用比例分别为5%,29%,61%。尽管TPU高达65536个DSP单元可以在CNN应用中获得很高的计算效率,然而CNN在Google数据中心的应用比例只有5%,大规模的DSP单元占用了较大的硅片面积,降低了良品率,增加了成本,仅对5%的应用有较高收益,其性价比值得商榷。
3 PCIE卡的方式使TPU的调用依赖于服务器,在机架上算力的部署密度也相对较低。
上述问题的核心是计算粒度的问题,脉动矩阵的规模太大了,一方面在LSTM和MLP这种较低数据复用率的场景,带宽依然是瓶颈;另一方面在延迟优先于吞吐,batchsize较小时,很难跑满性能,相对较小的计算粒度更适合。因此Google开始了TPU2的开发。
2.1.2 计算特性与构架变迁——TPU2[2]
TPU2为典型的第二阶段的AI芯片,应用了16GB的HBM从而获得600GB/s的片上带宽,主要解决两个问题:计算粒度问题和算力伸缩问题。
1 计算粒度:将脉动矩阵规模从256256缩减至双128128,如图3.8所示,这样每次控制和调度单位为原来的四分之一,减少数据导入导出延迟的同时,更有利于提升单片的计算效率;
2 算力伸缩:将TPU1的PCIE通信模式转变为板级通信模式,实现多板互联和高密度算力集群,采用类似芯片级分布式的方式实现算力扩展,降低任务分配、同步的难度和通信成本。例如目前TensorFlow Research Cloud由1024片TUP2构成,估计每个任务至多可以调用256片TPU2。板级互联避开了传统服务器低效的PCIE-以太网通路,直接在板间实现200GB的通信带宽,大大降低了板间的通信延迟,有利于跨芯片模型的高效计算,和数据中心7ms的响应速度。
其他改进:
1 片上HBM的应用取代了片外DDR3,减少了板上面积,从而可以在单板上部署4片TPU2;
2 单片性能为45Tops,单板180Tops;
3 支持32bit浮点运算;
4 同时支持training和inference。

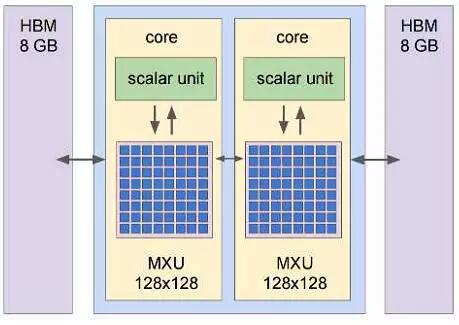
图3.8 TPU2的板级部署和内部结构,包括:单板4芯片(图中A),2组25GB/s专用网络(图中B),2个OPA(Omni-Path Architecture)接口(图中C),电源接口(图中D)。

图3.9 TPU2在数据中心的部署,其中A、D为CPU机架,B、C为TPU2机架;其中蓝线为UPS,红色虚线为供电电源,绿色虚线为机架的网络切换配置。
2.2、Microsoft
相比于Google选择自己研制ASIC,微软的BrainWave计划[3]则采用可重构的FPGA,推测原因在于:
1 应用场景决定架构。相比于TensorFlow,CNTK的影响力和对硬件的反哺能力较弱;
2 微软更侧重一个可编程的异构分布式平台,以适用于云端服务类型和规模的多变,以及对延迟敏感的计算密集型应用,而不局限于深度学习。异构分布式平台成型后,可在FPGA内部划分固定逻辑(静态区域)和针对任务的可配置逻辑(动态区域)。其中静态区域配置为分布式节点框架和数据接口,动态区域可按需更换,如图3.10、3.11所示。
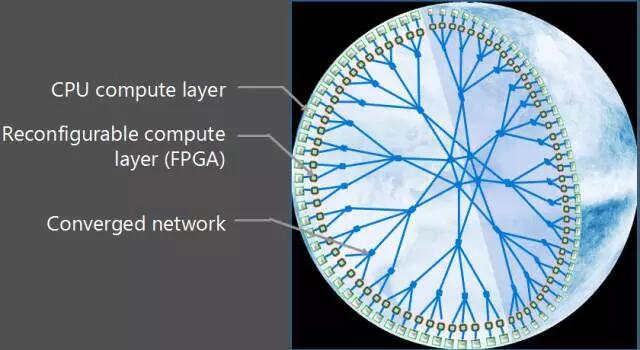
图3.10BrainWave计划的大规模可重构云构架
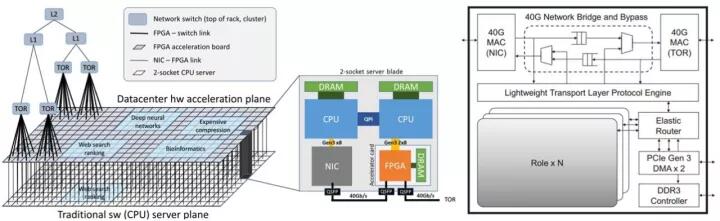
图3.11 Microsoft服务器端的FPGA池及其智能网卡结构(第三代)
图3.11中,FPGA以智能网卡的方式,与服务器通过PCIE接口通信。FPGA与FPGA之间采用芯片级互联方式,具有40Gb的带宽和超低的通信延迟,且通信过程无需CPU参与。该结构不仅可通过多片FPGA联合将DNN计算模型完全加载到片上缓存进行超低延迟的计算,也可兼容多种加速场景的超低延迟处理,如搜索、视频、传感器数据流等[4]。其应用可归纳为以下两种:
A、规模可伸缩的低延迟任务:当芯片级互联的FPGA数量成千上万后,可构成FPGA池,其间的通信和数据交互摆脱PCIE-服务器的交互方式,直接在芯片级进行任务分派和交互,可构成具备最高1Exa-ops/s的性能,如以78,120,000页/秒的速度进行机器翻译;对于LSTM这类带宽为瓶颈的场景,则通过将模型拆分,并部署到多片上,使计算时权值无需从片外DDR导入,规避了带宽的限制,实现算力的释放;
B、本地加速器:类似TPU1的加速方式,作为服务器本地加速器,通过PCIE进行数据交互和任务分配。不仅可用于DNN的主要计算单元,也可作为专注预处理的协处理器,以智能网卡的方式置于服务器网络接口与交换机之间,降低高吞吐下CPU的载荷,使CPU专注于更擅长的任务环节,例如云服务的数据流实时编解码、加密、解密等。
图3.11是微软的第三代FPGA池化的构架。第一代为单卡多片,一机四卡为一个计算粒度,如图3.12所示。第二代为单机单卡,保证服务器的同构性。

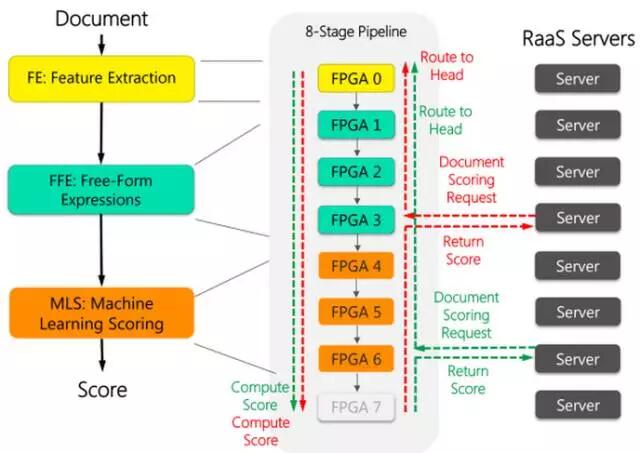
图3.12 Microsoft服务器端的FPGA加速卡与任务分配(第一代)
2.3、IBM
IBM也有推出类脑ASIC TrueNorth[5],早在2006年即开始立项,将时钟频率降低至1KHz,以注重低功耗应用。其芯片内节点的互联方式可编程实现,在学术界和国防项目的嵌入式前端的视觉识别上有相关应用,且可以海量芯片互联以实现更大规模的任务,如图3.13所示。
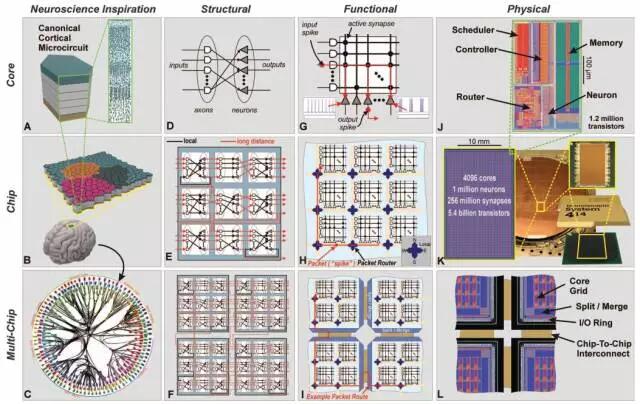
图3.13 TrueNorth芯片构架与互联
2.4、数据中心的应用综述小结与对比
在Datacenter端,FPGA与ASIC的对比可归纳为以下几个方面:
A、业务范围与灵活性:相比于TPU等云端加速ASIC,FPGA的单卡性能有限,基于FPGA构架是否具有优势取决于DataCenter加速业务的覆盖范围。当以云服务为代表的主流加速业务并不局限于DNN等矩阵运算,而需要应对不同客户的多种加速或大数据处理应用时,具备可重构、深度定制能力的FPGA将是一个不错的选择。ASIC主要针对某一特定领域或特定应用。针对应用越具体,构架越有针对性,其计算效率越高,覆盖的业务范围也越窄。
B、峰值计算能力:峰值计算能力取决于两个方面,运算单元数量和工作频率。对于前者,在不考虑带宽和功耗的约束下,ASIC可按需定制运算单元数量和物理上的空间分布,理论上没有上限,从而达到更高的计算性能和能耗效率,如TPU高达92Tops/s;FPGA为了保持一定通用性和可编程能力,只能通过型号区分DSP数量,且DSP上限由FPGA厂商决定。FPGA的工作频率并不固定,取决于制造工艺(如TPU@28nm,寒武纪DianNao@65nm)和设计的逻辑延迟。为了兼容多种设计,FPGA的逻辑单元、DSP(FPGA内部的乘加运算单元)、RAM等资源在物理层面的空间分布近似均匀分布,DSP与DSP、RAM与RAM之间的整合存在固有的路径延迟,大规模逻辑的频率上限通常在500M以下,DSP等硬核在1GHz以下。ASIC可定制片内的资源分布而不存在固有路径延迟,从而达到更高的频率(如NVIDIA P4@1.5GHz,Intel i7 4790@3.6GHz)。另外,实际运行的性能是否能逼近峰值计算能力,取决于针对性的定制程度。FPGA的深度定制可以保证每个DSP的利用率,在一定程度上弥补DSP数量不如ASIC的劣势。
C、计算效率:取决于计算粒度于构架调度方式的平衡。当计算粒度较大,如TPU1 256*256规模的脉动阵列,要跑满性能需要极大的带宽和高度的数据复用率支持,在多样化的场景下很难保证较高的计算效率。因此更多的构架中,采用中小规模的处理结构(如256个DSP)构成一个PE(Processing Element),多PE构成PE阵列,通过多层结构的任务分配和调度保证计算效率(如寒武纪的DaDianNao)。
D、设计周期与上线时间:FPGA采用可编程方式,将设计与流片过程解耦,大规模逻辑的开发周期通常为半年;ASIC不仅设计过程更复杂,流片、封装等过程的排期也受制于厂商,开发周期通常为18-24个月。即使以Google TPU团队的规模和投入,从设计到部署也经历了15个月。3倍滞后时间使FPGA更适合快速迭代,以快速切入不断更新的算法模型。
E、成本与风险:高性能FPGA的芯片成本取决于购买数量,供货风险和研发风险较低;ASIC的制造需要较高成本,如公式(1),并涉及到良品率等问题。一旦在实际生产中发现错误,则只能再次投资从头开始,风险较高。
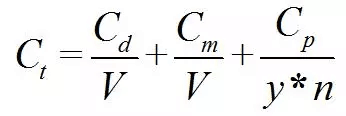
(1)
上式中,Ct为芯片设计和加工的总成本,Cd为设计成本,Cm为加工中的光罩(Mask)成本,Cp为每片晶元(Wafer)的加工成本,V为总产量,y为成品率,n为每个晶元上可切割出的芯片数量。从上式可知,ASIC在确定制造工艺时,ASIC的单位成本取决于部署数量V。当部署万片以上,单价可降至几百元。同时,ASIC的成本与加工工艺的关系密切。采用更高精度的工艺可有效提升芯片的工作频率,并降低功耗,但总成本也大幅度增加。
上述对比仅仅是对芯片本身优劣的分析。有时,在一个完整的产业链条下,ASIC的价值并不限于其本身,而是一个领域扩张之后,走向上下游的必经之路。相比于未来几年整个产业链和生态的繁荣和垄断,ASIC的流片成本就显得微不足道了。可以说,TPU只是Google主导深度学习领域,并向上下游迈进时,在云端的布局。相比于正在逐渐展开的嵌入式端AI硬件的应用,仅仅是一个开局而已。
三、Datacenter与云端低延迟FPGA与ASIC的必经之路
随着深度学习与大数据的结合,和多种应用的落地,计算平台的演进终究还是生态的竞争。性能、延迟、吞吐是关键指标,但有时易用性、普适性和运营方式才是胜负的关键。整体来看,GPU、FPGA和ASIC更擅胜场。GPU生态最好,多年的经营使其在库的完备性、算法与硬件的端到端的易用性、开发群体社区营造都是无可比拟的。FPGA灵活性最好,可在新兴计算初期,ASIC出现之前快速切入应用市场,抢占先机,且不受ASIC应用规模和成本的约束,适合云端这种多变场景下的可重构的异构计算。ASIC的定制性可控,在解决带宽的前提下几乎可以实现于GPU和FPGA 10倍~100倍的物理计算规模,成为数据中心的终极武器。
尽管对于某一个较窄的领域,FPGA和ASIC可以做到比GPU更深入的定制,但在AI模型不断更新的今天,想赶超GPU必须解决两个问题,一是迭代周期,二是端到端的生态营造。
3.1、FPGA与ASIC的问题——迭代周期
FPGA与ASIC的开发周期和门槛一直为人所诟病。即使迭代较快的FPGA,一个Datacenter的项目从立项到上线也要近半年,在新机遇出现时无法迅速占领市场。为此,目前业界有两种解决方案,即高层次综合和AI协处理器。
1)高层次综合,即使用C等高层次语言进行开发,而后通过高层次综合工具直接将其转化为可直接应用于FPGA或ASIC的RTL级结构,将开发效率提升4倍以上。典型的代表如Xilinx主推的HLS和Altera主推的OpenCL等。然而HLS生成的结构相比于直接RTL开发,在执行效率、逻辑规模上有较大差距,会降低约30%的性能。对此,一些厂商在高层次综合中加入针对AI算法的优化,即使用RTL开发常用的AI模块构成硬件IP库,如CNN中的Conv、Pooling、RELU等,取代一部分高层次综合自动生成的模块,寻求定制性和易用性的平衡,来提升最终系统的性能。
2)AI协处理器,即开发具有部分通用性的FPGA或ASIC。为了寻求通用性与定制性之间的平衡,保证协处理器的计算效率,仅将算法模型中耗时最长、计算密度最高的任务放到协处理器中,其他部分由CPU完成,从而降低通用性带来的性能损失。同时,协处理器支持相应的指令集,CPU通过传输指令的方式调用协处理器,以应对不同应用场景。当逻辑结构固化后,将RTL开发的长周期迭代转化为指令序列的开发,甚至不需要FPGA工程的重新编译和布局布线,极大降低了切入时间。不同于DianNao系列和TPU,寒武纪的Cambricon处理器是一种以指令为导向的处理器,指令集最为完备[6],如图3.14所示。当然,FPGA上也可以实现通用AI协处理器,但由于资源受限,在大批量的应用场景出现之后最终也将走向ASIC。
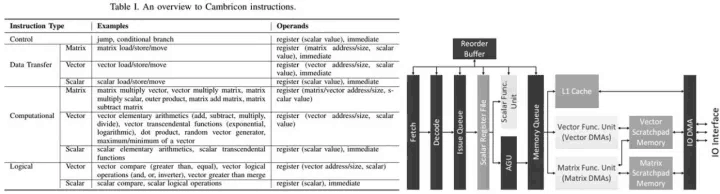
图3.14 寒武纪Cambricon处理器的指令集与芯片整体构架
3.2、FPGA与ASIC的问题——端到端的生态营造
端到端是指,从TensorFlow、Torch、Caffe等深度学习算法框架到硬件的无缝连接,使开发者在不具备硬件知识和优化方法的前提下,完全依靠由编译器来完成计算资源的调用和优化,甚至使用了硬件加速而不自知。在这一点上,GPU走在了异构计算的最前列。当FPGA和ASIC以AI协处理器的方式参与计算时,需要在深度学习框架中提供相应接口,由编译器将框架中的代码转化为符合硬件指令集的指令序列,从而实现FPGA或ASIC的顶层调用。其中,编译器实现指令序列的过程中,要符合硬件资源的最优配置,如支持单卡单片、单卡多片、多卡单片、多卡多片等硬件实际配置模式。另外,用户的侧重点也不同,尤其对Inference服务,用户需求在吞吐、延迟、资源配给等各个方面差异性非常大。动态的协调硬件资源和计算拓扑,甚至从单机、多机走向分布式,编译器的角色至关重要。
四、结语
在FPGA、ASIC甚至量子计算等全新的计算模式的选择中,无论是以应用场景为设计导向,还是把握通用与定制、性能与带宽的平衡,其根本在于对Datacenter业务需求和行业走向的深刻理解,构架和方案的分歧也在于此,而这也是我们对异构计算架构中探索的动力源泉。
参考文献
[1] Jouppi N P, Young C, Patil N, et al. In-datacenter performance analysis of a tensor processing unit[J]. arXiv preprint arXiv:1704.04760, 2017.
[2] Jeff Dean. Recent Advances in Artificial Intelligence and the Implications for Computer System Design[C]. Hot Chips 2017.
[3] Eric Chung, Jeremy Fowers, Kalin Ovtcharov, et al. Accelerating Persistent Neural Networks at Datacenter Scale[C]. Hot Chips 2017.
[4] Caulfield A M, Chung E S, Putnam A, et al. A cloud-scale acceleration architecture[C]//Microarchitecture (MICRO), 2016 49th Annual IEEE/ACM International Symposium on. IEEE, 2016: 1-13.
[5] Merolla P A, Arthur J V, Alvarez-Icaza R, et al. A million spiking-neuron integrated circuit with a scalable communication network and interface[J]. Science, 2014, 345(6197): 668-673.
[6] Liu S, Du Z, Tao J, et al. Cambricon: An Instruction Set Architecture for Neural Networks[C]// International Symposium on Computer Architecture. IEEE Press, 2016:393-405.