# 节点层级
任何 HTML 或 XML 文档都可以用 DOM 表示为一个由节点构成的层级结构。节点分很多类型,每种类型对应着文档中不同的信息和(或)标记,也都有自己不同的特性、数据和方法,而且与其他类型有某种关系。这些关系构成了层级,让标记可以表示为一个以特定节点为根的树形结构。
document 节点是每个文档的根节点。根节点的唯一子节点是< html>元素,称文档元素(documentElement),是文档最外层的元素,所有其他元素都存在于这个元素之内,每个文档只能有一个文档元素。在 HTML 页面中,文档元素始终是< html>元素。在 XML 文档中,则没有这样预定义的元素,任何元素都可能成为文档元素。
# Node类型
DOM Level 1 描述了名为Node的接口,该接口是所有DOM节点类型都必须实现的。Node接口在JavaScript中被实现为Node类型,在除IE之外的所有浏览器中都可以直接访问这个类型。在JavaScript中,所有节点类型都继承Node类型,因此所有类型都共享相同的基本属性和方法。
- 每个节点都有 nodeType 属性,表示该节点的类型
- 节点类型由定义在 Node 类型上的 12 个数值常量表示
- Node.ELEMENT_NODE(1)
- Node.ATTRIBUTE_NODE(2)
- Node.TEXT_NODE(3)
- Node.CDATA_SECTION_NODE(4)
- Node.ENTITY_REFERENCE_NODE(5)
- Node.ENTITY_NODE(6)
- Node.PROCESSING_INSTRUCTION_NODE(7)
- Node.COMMENT_NODE(8)
- Node.DOCUMENT_NODE(9)
- Node.DOCUMENT_TYPE_NODE(10)
- Node.DOCUMENT_FRAGMENT_NODE(11)
- Node.NOTATION_NODE(12)
# nodeName与nodeValue
- 保存有关节点的信息,属性值完全取决于节点类型,在使用属性前最好先检测节点类型
if (someNode.nodeType == 1) {
value = someNode.nodeName; // 会显示元素的标签名
}# 节点关系
- 所有关系指针都是只读的
- 每个节点都有一个 childNodes 属性,其中包含一个 NodeList 的实例
- NodeList 是一个类数组对象,用于存储可以按位置存取的有序节点
- 是对 DOM 结构的查询,因此 DOM 结构的变化会自动地在 NodeList 中反映出来(是实时活动对象而不是首次访问快照)
- 可使用中括号或使用 item()方法访问 NodeList 中的元素
- 使用 Array.prototype.slice()可以把 NodeList 对象转换为数组(或者Array.from())
- 每个节点都有一个 parentNode 属性,指向其 DOM 树中的父元素
- childNodes 列表中的每个节点都是同一列表中其他节点的同胞节点
- 使用 previousSibling 和 nextSibling 可以在这个列表的节点间导航(首或尾节点前或后为null)
- 父节点和它的第一个及最后一个子节点也有专门属性: firstChild 和 lastChild
- hasChildNodes()返回 true 则说明节点有一个或多个子节点
- ownerDocument 属性是一个指向代表整个文档的文档节点的指针,所有节点都被创建它们(或自己所在)的文档所拥有
# 操纵节点
- appendChild():用于在 childNodes 列表末尾添加节点
- 添加新节点会更新相关的关系指针,包括父节点和之前的最后一个子节点
- appendChild()方法返回新添加的节点
- 如果把文档中已经存在的节点传给 appendChild(),则这个节点会从之前的位置被转移到新位置
- 一个节点也不会在文档中同时出现在两个或更多个地方(如果调用 appendChild()传入父元素的第一个子节点,则这个节点会成为父元素的最后一个子节点)
- insertBefore():把节点放到 childNodes 中的特定位置
- 接收两个参数:要插入的节点和参照节点
- 插入的节点会变成参照节点的前一个同胞节点,并被返回
- 如果参照节点是 null,则 insertBefore()与 appendChild()效果相同
- replaceChild()接收两个参数:要插入的节点和要替换的节点
- 要替换的节点会被返回并从文档树中完全移除,要插入的节点会取而代之
- 使用 replaceChild()插入一个节点后,所有关系指针都会从被替换的节点复制过来
- 虽然被替换的节点从技术上说仍然被同一个文档所拥有,但文档中已经没有它的位置
- removeChild():接收一个参数,即要移除的节点,被移除的节点会被返回
- 移除的节点从技术上说仍然被同一个文档所拥有,但文档中已经没有它的位置
- cloneNode():会返回与调用它的节点一模一样的节点
- 接收一个布尔值参数,表示是否深复制
- 传入true参数时,会进行深复制,即复制节点及其整个子DOM树
- 如果传入false,则只会复制调用该方法的节点
- 复制返回的节点属于文档所有,但尚未指定父节点,可称为孤儿节点
- 接收一个布尔值参数,表示是否深复制
- normalize():处理文档子树中的文本节点
# Document类型
Document类型是JS中表示文档节点的类型。在浏览器中,文档对象document是HTMLDocument的实例(HTMLDocument继承Document),表示整个HTML页面。document是window对象的属性,因此是一个全局对象。document 对象可用于获取关于页面的信息以及操纵其外观和底层结构。
- 文档子节点
- documentElement 属性:始终指向 HTML 页面中的< html>元素
- body 属性:直接指向< body>元素
- 文档类型(如果存在)是只读的,而且只能有一个 Element 类型的子节点
- Document节点的子节点可以是 DocumentType、 Element、 ProcessingInstruction 或 Comment
- <!doctype>标签是文档中独立的部分,其信息可以通过 doctype 属性(document.doctype)来访问
- 严格来讲出现在< html>元素外面的注释也是文档的子节点,它们的类型是 Comment
- 文档信息
- title:包含< title>元素中的文本,通常显示在浏览器窗口或标签页的标题栏
- 可以读写页面的标题,修改后的标题也会反映在浏览器标题栏上
- 修改 title 属性并不会改变< title>元素,会修改元素内文本
- URL、 domain 和 referrer
- URL:包含当前页面的完整 URL
- domain: 包含页面的域名
- 可以设置,但不能给这个属性设置 URL 中不包含的值
- 当页面含有来自某个不同子域的窗格(< frame>)或内嵌窗格(< iframe>)时,可以通过设置document.domain为相同的值进行通信
- 该属性一旦放松就不能再收紧(把document.domain 设置为"wrox.com"之后,就不能再将其设置回"p2p.wrox.com")
- referrer:包含链接到当前页面的那个页面的 URL,如果当前页面没有来源,则 referrer 属性包含空字符串
- 些信息都可以在请求的 HTTP 头部信息中获取,只是在 JavaScript 中通过这几个属性暴露出来而已
- 定位元素
- getElementById():接收一个参数,即要获取元素的 ID
- 如果找到了则返回这个元素,如果没找到则返回 null
- ID必须跟元素在页面中的 id 属性值完全匹配,包括大小写
- getElementsByTagName():接收获取元素的标签名,返回包含零个或多个元素的 NodeList
- 在 HTML 文档中,返回一个HTMLCollection 对象(实时对象)
- 要取得文档中的所有元素,可以给 getElementsByTagName()传入*
- getElementsByName():返回具有给定 name 属性的所有元素
- 最常用于单选按钮,同一字段的单选按钮必须具有相同的 name 属性才能确保把正确的值发送给服务器
- 特殊集合
- document.anchors 包含文档中所有带 name 属性的< a>元素
- document.forms 包含文档中所有< form>元素(与 document.getElementsByTagName ("form") 返回的结果相同)
- document.images 包含文档中所有< img>元素(与 document.getElementsByTagName ("img") 返回的结果相同)
- document.links 包含文档中所有带 href 属性的< a>元素
- DOM兼容性检测
document.implementation 属性是一个对象,其中提供了与浏览器 DOM 实现相关的信息和能力。DOM Level 1 在 document.implementation 上只定义了一个方法 hasFeature(),接收两个参数:特性名称和 DOM 版本。由于实现不一致,因此 hasFeature()的返回值并不可靠。
- 文档写入
- write()和 writeln()方法都接收一个字符串参数,可将字符串写入网页中
- write()简单地写入文本
- writeln()还会在字符串末尾追加一个换行符(\n)
- 如果是在页面加载完之后再调用 document.write(),则输出的内容会重写整个页面
- 可以用来在页面加载期间向页面中动态添加内容(常用于动态包含外部资源)
- open()和 close()方法分别用于打开和关闭网页输出流。在调用 write()和 writeln()时,这两个方法都不是必需的
# Element类型
Element 类型就是 Web 开发中最常用的类型了。Element 表示 XML 或 HTML 元素,对外暴露出访问元素标签名、子节点和属性的能力。可以通过 nodeName 或 tagName 属性来获取元素的标签名。在 HTML 中,元素标签名始终以全大写表示;在 XML(包括 XHTML)中,标签名始终与源代码中的大小写一致。
- HTML元素
所有 HTML 元素都通过 HTMLElement 类型表示,包括其直接实例和间接实例(即HTMLElement 或其子类型的实例)。
- 取得属性
每个元素都有零个或多个属性,通常用于为元素或其内容附加更多信息
- getAttribute()
- 传给 getAttribute()的属性名与它们实际的属性名是一样的,因此这里要传"class"而非"className"
- 如果给定的属性不存在, 则 getAttribute() 返回 null
- 能取得不是 HTML 语言正式属性的自定义属性的值
- 属性名不区分大小写,因此"ID"和"id"被认为是同一个属性
- 根据 HTML5 规范的要求,自定义属性名应该前缀 data-以方便验证
- 元素的所有属性也可以通过相应 DOM 元素对象的属性来取得
- 包括 HTMLElement 上定义的直接映射对应属性的 5 个属性,还有所有公认(非自定义)的属性也会被添加为 DOM 对象的属性
- 通过 DOM 对象访问的属性中有两个返回的值跟使用 getAttribute()取得的值不一样
- 使用 getAttribute()访问 style 属性时,返回的是 CSS 字符串。通过 DOM 对象的属性访问时, style 属性返回的是一个(CSSStyleDeclaration)
- 对于事件处理程序(或者事件属性),使用 getAttribute()访问事件属性,则返回的是字符串形式的源代码。而通过 DOM 对象的属性访问事件属性时返回的则是一个JavaScript函数对象
- 进行 DOM 编程时通常会放弃使用 getAttribute()而只使用对象属性
- getAttribute()主要用于取得自定义属性的值
- 设置属性
- setAttribute()
- 接收两个参数:要设置的属性名和属性的值
- 如果属性已经存在,则 setAttribute()会以指定的值替换原来的值;
- 如果属性不存在,则 setAttribute()会以指定的值创建该属性
- setAttribute()适用于 HTML 属性,也适用于自定义属性
- removeAttribute():从元素中删除属性
- 不单单是清除属性的值,而是会把整个属性完全从元素中去掉
- attributes 属性
Element 类型是唯一使用attributes属性的DOM节点类型。attributes属性包含一个NamedNodeMap 实例,是一个类似NodeList的“实时”集合。元素的每个属性都表示为一个Attr节点,并保存在这个NamedNodeMap对象中。
- NamedNodeMap 对象包含下列方法:
- getNamedItem(name),返回 nodeName 属性等于 name 的节点
- removeNamedItem(name),删除 nodeName 属性等于 name 的节点
- setNamedItem(node),向列表中添加 node 节点,以其 nodeName 为索引
- item(pos),返回索引位置 pos 处的节点
- attributes 属性中的每个节点的 nodeName 是对应属性的名字, nodeValue 是属性的值。
- attributes 属性最有用的场景是需要迭代元素上所有属性的时候
- 创建元素
可以使用document.createElement()方法创建新元素。接收一个参数,即要创建元素的标签名。在HTML文档中,标签名是不区分大小写的,而XML文档(包括XHTML)是区分大小写的。
- 使用createElement()方法创建新元素的同时也会将其ownerDocument属性设置为document
- 要把元素添加到文档树,可以使用 appendChild()、 insertBefore()或 replaceChild()
- 元素被添加到文档树之后,浏览器会立即将其渲染出来
- 元素后代
元素可以拥有任意多个子元素和后代元素,因为元素本身也可以是其他元素的子元素。 childNodes属性包含元素所有的子节点,这些子节点可能是其他元素、文本节点、注释或处理指令。
# Text类型
Text节点由Text类型表示,包含按字面解释的纯文本,也可能包含转义后的HTML字符,但不含HTML代码。Text节点中包含的文本可以通过nodeValue属性访问,也可以通过data属性访问。
- 操作文本方法:
- appendData(text),向节点末尾添加文本 text
- deleteData(offset, count),从位置 offset 开始删除 count 个字符
- insertData(offset, text),在位置 offset 插入 text
- replaceData(offset, count, text),用 text 替换从位置 offset 到 offset + count 的文本
- splitText(offset),在位置 offset 将当前文本节点拆分为两个文本节点
- substringData(offset, count),提取从位置 offset 到 offset + count 的文本
- 可以通过 length 属性获取文本节点中包含的字符数量
- HTML 或 XML 代码(取决于文档类型)会被转换成实体编码,即小于号、大于号或引号会被转义
- 创建文本节点
document.createTextNode()可以用来创建新文本节点,它接收一个参数,即要插入节点的文本。一般来说一个元素只包含一个文本子节点。不过,也可以让元素包含多个文本子节点。
- 规范化文本节点 normalize()可以合并相邻的文本节点
- 该方法是在 Node 类型中定义的
- 在包含两个或多个相邻文本节点的父节点上调用时,所有同胞文本节点会被合并为一个文本节点
- 浏览器在解析文档时,永远不会创建同胞文本节点
- 同胞文本节点只会出现在 DOM 脚本生成的文档树中
- 拆分文本节点 splitText()可以在指定的偏移位置拆分 nodeValue,将一个文本节点拆分成两个文本节点
- 该方法返回新的文本节点,具有与原来的文本节点相同的 parentNode
- 拆分文本节点最常用于从文本节点中提取数据的 DOM 解析技术
# Comment类型
DOM 中的注释通过 Comment 类型表示。与 Text 类型继承同一个基类( CharacterData),因此拥有除 splitText()之外Text 节点所有的字符串操作方法。与 Text 类型相似,注释的实际内容可以通过 nodeValue 或 data 属性获得。
- 注释节点可以作为父节点的子节点来访问
- document.createComment()方法创建注释节点,参数为注释文本
- 浏览器不承认结束的</ html>标签之后的注释。
# CDATASection类型
CDATASection 类型表示 XML 中特有的 CDATA 区块。 CDATASection 类型继承 Text 类型,拥有包括 splitText()在内的所有字符串操作方法。
- CDATA 区块只在 XML 文档中有效,因此某些浏览器比较陈旧的版本会错误地将 CDATA 区块解析为 Comment 或 Element
- 在真正的 XML 文档中,可以使用 document.createCDataSection()并传入节点内容来创建 CDATA 区块
# DocumentType类型
DocumentType 类型的节点包含文档的文档类型( doctype)信息
- DocumentType 对象在 DOM Level 1 中不支持动态创建,只能在解析文档代码时创建
- 对于支持这个类型的浏览器, DocumentType 对象保存在 document.doctype 属性中
- DOM Level 1 规定了 DocumentType 对象的 3 个属性: name、 entities 和 notations
- name 是文档类型的名称
- entities 是这个文档类型描述的实体的 NamedNodeMap
- notations 是这个文档类型描述的表示法的 NamedNodeMap
- 浏览器中的文档通常是 HTML 或 XHTML 文档类型,所以 entities 和 notations 列表为空
<!DOCTYPE HTML PUBLIC "-// W3C// DTD HTML 4.01// EN"
"http:// www.w3.org/TR/html4/strict.dtd">
<!-- 对于这个文档类型, name 属性的值是"html" --># DocumentFragment类型
DocumentFragment 类型是唯一一个在标记中没有对应表示的类型。DOM将文档片段定义为“轻量级”文档,能够包含和操作节点,却没有完整文档那样额外的消耗。不能直接把文档片段添加到文档。相反,文档片段的作用是充当其他要被添加到文档的节点的仓库。
- 使用 document.createDocumentFragment()方法创建文档片段
- 文档片段从 Node 类型继承了所有文档类型具备的可以执行 DOM 操作的方法
- 如果文档中的一个节点被添加到一个文档片段,则该节点会从文档树中移除,不会再被浏览器渲染
- 可以通过 appendChild()或 insertBefore()方法将文档片段的内容添加到文档
- 在把文档片段作为参数传给这些方法时,文档片段的所有子节点会被添加到文档中相应的位置
- 文档片段本身永远不会被添加到文档树
// 如果分 3 次给这个元素添加列表项,浏览器就要重新渲染3 次页面,以反映新添加的内容
// 利用文档片段可避免多次渲染
let fragment = document.createDocumentFragment();
let ul = document.getElementById("myList");
for (let i = 0; i < 3; ++i) {
let li = document.createElement("li");
li.appendChild(document.createTextNode(`Item ${i + 1}`));
fragment.appendChild(li);
}
ul.appendChild(fragment);
# Attr类型
元素数据在 DOM 中通过 Attr 类型表示。 Attr 类型构造函数和原型在所有浏览器中都可以直接访问。技术上讲,属性是存在于元素 attributes 属性中的节点。
- 属性节点尽管是节点,却不被认为是 DOM 文档树的一部分
- Attr 节点很少直接被引用,通常开发者更喜欢使用 getAttribute()、 removeAttribute()和 setAttribute()方法操作属性
- Attr 对象上有 3 个属性: name、 value 和 specified
- name 包含属性名
- value 包含属性值
- specified 是一个布尔值,表示属性使用的是默认值还是被指定的值
- 可以使用 document.createAttribute()方法创建新的 Attr 节点,参数为属性名
# DOM编程
# 动态脚本
动态脚本就是在页面初始加载时不存在,之后又通过 DOM 包含的脚本。有两种方式通过< script>动态为网页添加脚本:引入外部文件和直接插入源代码。
通过 innerHTML 属性创建的< script>元素永远不会执行。浏览器会尽责地创建< script>元素,以及其中的脚本文本,但解析器会给这个< script>元素打上永不执行的标签。
# 动态样式
< link>元素用于包含 CSS 外部文件, 而< style>元素用于添加嵌入样式。动态样式也是页面初始加载时并不存在,而是在之后才添加到页面中的。
// 注意应该把<link>元素添加到<head>元素而不是<body>元素,这样才能保证所有浏览器都能正常运行 function loadStyles(url){ let link = document.createElement("link"); link.rel = "stylesheet"; link.type = "text/css"; link.href = url; let head = document.getElementsByTagName("head")[0]; head.appendChild(link); }
// style
let style = document.createElement("style");
style.type = "text/css";
style.appendChild(document.createTextNode("body{background-color:red}"));
let head = document.getElementsByTagName("head")[0];
head.appendChild(style);
# 操作表格
为了方便创建表格, HTML DOM 给< table>、 < tbody>和< tr>元素添加了一些属性和方法
- < table>元素属性和方法
- caption,指向< caption>元素的指针(如果存在)
- tBodies,包含< tbody>元素的 HTMLCollection
- tFoot,指向< tfoot>元素(如果存在)
- tHead,指向< thead>元素(如果存在)
- rows,包含表示所有行的 HTMLCollection
- createTHead(),创建< thead>元素,放到表格中,返回引用
- createTFoot(),创建< tfoot>元素,放到表格中,返回引用
- createCaption(),创建< caption>元素,放到表格中,返回引用
- deleteTHead(),删除< thead>元素
- deleteTFoot(),删除< tfoot>元素
- deleteCaption(),删除< caption>元素
- deleteRow(pos),删除给定位置的行
- insertRow(pos),在行集合中给定位置插入一行
- < tbody>元素属性和方法
- rows,包含< tbody>元素中所有行的 HTMLCollection
- deleteRow(pos),删除给定位置的行
- insertRow(pos),在行集合中给定位置插入一行,返回该行的引用
- < tr>属性和方法
- cells,包含< tr>元素所有表元的 HTMLCollection
- deleteCell(pos),删除给定位置的表元
- insertCell(pos),在表元集合给定位置插入一个表元,返回该表元的引用
# 使用NodeList
NodeList 是基于 DOM 文档的实时查询。
- 任何时候要迭代 NodeList,最好再初始化一个变量保存当时查询时的长度,然后用循环变量与这个变量进行比较
- 最好限制操作 NodeList 的次数。因为每次查询都会搜索整个文档,所以最好把查询到的 NodeList 缓存起来
# MutationObserver接口
MutationObserver 接口,可以在 DOM 被修改时异步执行回调。使用 MutationObserver 可以观察整个文档、 DOM 树的一部分,或某个元素。还可以观察元素属性、子节点、文本,或者前三者任意组合的变化。
# 基本用法
- observe()方法
新创建的 MutationObserver 实例不会关联 DOM 的任何部分。要把这个 observer 与 DOM 关联起来,需要使用 observe()方法。这个方法接收两个必需的参数:要观察其变化的 DOM 节点,以及一个 MutationObserverInit 对象。MutationObserverInit 对象用于控制观察哪些方面的变化, 是一个键/值对形式配置选项的字典。
let observer = new MutationObserver(() => console.log('<body> attributes changed')); observer.observe(document.body, { attributes: true });document.body.className = 'foo';
console.log('Changed body class');
// Changed body class
// <body> attributes changed
- 回调与 MutationRecord
每个回调都会收到一个 MutationRecord 实例的数组。 MutationRecord 实例包含的信息包括发生了什么变化,以及 DOM 的哪一部分受到了影响。因为回调执行之前可能同时发生多个满足观察条件的事件,所以每次执行回调都会传入一个包含按顺序入队的 MutationRecord 实例的数组。连续修改会生成多个 MutationRecord 实例,下次回调执行时就会收到包含所有这些实例的数组,顺序为变化事件发生的顺序。传给回调函数的第二个参数是观察变化的 MutationObserver 的实例。
let observer = new MutationObserver((mutationRecords) => console.log(mutationRecords));
observer.observe(document.body, { attributes: true });
document.body.setAttribute('foo', 'bar');
// [
// {
// addedNodes: NodeList [],
// attributeName: 'foo',
// attributeNamespace: null,
// nextSibling: null,
// oldValue: null,
// previousSibling: null,
// removedNodes: NodeList [],
// target: body,
// type: 'attributes'
// }
// ]
document.body.setAttributeNS('baz', 'foo', 'bar'); // 涉及命名空间的变化
// [
// {
// addedNodes: NodeList [],
// attributeName: "foo",
// attributeNamespace: "baz",
// nextSibling: null,
// oldValue: null,
// previousSibling: null
// removedNodes: NodeList [],
// target: body
// type: "attributes"
// }
// ]
- disconnect()方法
默认情况下,只要被观察的元素不被垃圾回收, MutationObserver 的回调就会响应 DOM 变化事件,从而被执行。要提前终止执行回调,可以调用 disconnect()方法。同步调用disconnect()之后,不仅会停止此后变化事件的回调,也会抛弃已经加入任务队列要异步执行的回调。
let observer = new MutationObserver(() => console.log('<body> attributes changed'));
observer.observe(document.body, { attributes: true });
document.body.className = 'foo';
observer.disconnect();
document.body.className = 'bar';
//(没有日志输出)
要想让已经加入任务队列的回调执行,可以使用setTimeout()让已经入列的回调执行完毕再调用disconnect()
let observer = new MutationObserver(() => console.log('<body> attributes changed'));
observer.observe(document.body, { attributes: true });
document.body.className = 'foo';
setTimeout(() => {
observer.disconnect();
document.body.className = 'bar';
}, 0);
// <body> attributes changed
- 复用 MutationObserver
多次调用observe()方法,可以复用一个MutationObserver对象观察多个不同的目标节点。此时, MutationRecord的target属性可以标识发生变化事件的目标节点。disconnect()方法是一个“一刀切”的方案,调用它会停止观察所有目标。
let observer = new MutationObserver((mutationRecords) => console.log(mutationRecords.map((x) => x.target))); // 向页面主体添加两个子节点 let childA = document.createElement('div'), childB = document.createElement('span'); document.body.appendChild(childA); document.body.appendChild(childB);
// 观察两个子节点
observer.observe(childA, { attributes: true });
observer.observe(childB, { attributes: true });
// 修改两个子节点的属性
childA.setAttribute('foo', 'bar');
childB.setAttribute('foo', 'bar');
// [<div>, <span>]
- 重用 MutationObserver
调用disconnect()并不会结束MutationObserver的生命。还可以重新使用这个观察者,再将它关联到新的目标节点。
# MutationObserverInit 与观察范围
MutationObserverInit对象用于控制对目标节点的观察范围。粗略地讲,观察者可以观察的事件包括属性变化、文本变化和子节点变化。
- 观察属性
MutationObserver可以观察节点属性的添加、移除和修改。要为属性变化注册回调,需要在MutationObserverInit对象中将attributes属性设置为true
- 观察字符数据
MutationObserver可以观察文本节点(如Text、Comment或ProcessingInstruction节点)中字符的添加、删除和修改。要为字符数据注册回调,需要在MutationObserverInit对象中将characterData属性设置为true
- 观察子节点
MutationObserver可以观察目标节点子节点的添加和移除。要观察子节点,需要在MutationObserverInit对象中将childList属性设置为true。对子节点重新排序(尽管调用一个方法即可实现)会报告两次变化事件,因为从技术上会涉及先移除和再添加
- 观察子树
默认情况下, MutationObserver将观察的范围限定为一个元素及其子节点的变化。可以把观察的范围扩展到这个元素的子树(所有后代节点),这需要在 MutationObserverInit对象中将subtree属性设置为true。被观察子树中的节点被移出子树之后仍然能够触发变化事件。
# 异步回调与记录队列
MutationObserver接口是出于性能考虑而设计的,其核心是异步回调与记录队列模型。为了在大量变化事件发生时不影响性能,每次变化的信息(由观察者实例决定)会保存在MutationRecord实例中,然后添加到记录队列。这个队列对每个MutationObserver实例都是唯一的,是所有DOM变化事件的有序列表。
- 记录队列
每次 MutationRecord 被添加到 MutationObserver 的记录队列时,仅当之前没有已排期的微任务回调时(队列中微任务长度为 0),才会将观察者注册的回调(在初始化 MutationObserver 时传入)作为微任务调度到任务队列上。这样可以保证记录队列的内容不会被回调处理两次。
- takeRecords()方法
调用 MutationObserver 实例的 takeRecords()方法可以清空记录队列,取出并返回其中的所有 MutationRecord 实例。
# Selectors API
# querySelector()
接收CSS选择符参数,返回匹配该模式的第一个后代元素,如果没有匹配项则返回null。在 Document上使用 querySelector()方法时,会从文档元素开始搜索;在Element上使用querySelector()方法时,则只会从当前元素的后代中查询。
# querySelectorAll()
接收一个用于查询的参数,返回所有匹配的节点(一个 NodeList 的静态实例,但是是静态的“快照”,而非“实时”的查询)。可以在Document、DocumentFragment和Element类型上使用。
# matches()
接收一个CSS选择符参数,如果元素匹配则该选择符返回true,否则返回false。使用这个方法可以方便地检测某个元素会不会被querySelector()或querySelectorAll()方法返回。
# 元素遍历
IE9之前的版本不会把元素间的空格当成空白节点,而其他浏览器则会。这样就导致了childNodes和firstChild等属性上的差异。为了弥补这个差异,同时不影响DOM规范,W3C通过新的Element Traversal规范定义了一组新属性,为遍历 DOM 元素提供便利。
Element Traversal API 为 DOM 元素添加了 5 个属性:
- childElementCount,返回子元素数量(不包含文本节点和注释);
- firstElementChild,指向第一个 Element 类型的子元素(Element版firstChild);
- lastElementChild,指向最后一个 Element 类型的子元素(Element版lastChild);
- previousElementSibling , 指向前一个Element类型的同胞元素(Element版previousSibling);
- nextElementSibling,指向后一个 Element 类型的同胞元素(Element版nextSibling)。
# HTML5
# CSS类扩展
- getElementsByClassName()
- 暴露在 document 对象和所有 HTML 元素上
- 接收一个参数,即包含一个或多个类名的字符串,返回类名中包含相应类的元素的 NodeList
- 只会返回以调用它的对象为根元素的子树中所有匹配的元素
- 如果要给包含特定类(而不是特定 ID 或标签)的元素添加事件处理程序,使用这个方法会很方便
// 取得所有类名中包含"username"和"current"元素
// 这两个类名的顺序无关紧要
let allCurrentUsernames = document.getElementsByClassName("username current");
// 取得 ID 为"myDiv"的元素子树中所有包含"selected"类的元素
let selected = document.getElementById("myDiv").getElementsByClassName("selected");
- classList属性
要操作类名,可以通过 className 属性实现添加、删除和替换。className 是一个字符串,所以每次操作之后都需要重新设置这个值才能生效,即使只改动了部分字符串也一样。HTML5 通过给所有元素增加 classList 属性为这些操作提供了更简单也更安全的实现方式。
classList 是一个新的集合类型 DOMTokenList 的实例,DOMTokenList有length属性表示自己包含多少项,可以通过 item()或中括号取得个别的元素。
- add(value),向类名列表中添加指定的字符串值 value。如果这个值已经存在,则什么也不做。
- contains(value),返回布尔值,表示给定的 value 是否存在。
- remove(value),从类名列表中删除指定的字符串值 value。
- toggle(value),如果类名列表中已经存在指定的 value,则删除;如果不存在,则添加。
# 焦点管理
HTML5 增加了辅助 DOM 焦点管理的功能。首先是 document.activeElement,始终包含当前拥有焦点的 DOM 元素。
- 页面加载时,可以通过用户输入(按 Tab 键或代码中使用 focus()方法)让某个元素自动获得焦点
- 默认情况下, document.activeElement 在页面刚加载完之后会设置为 document.body。而在页面完全加载之前, document.activeElement 的值为 null
- document.hasFocus()方法,该方法返回布尔值,表示文档是否拥有焦点
# HTMLDocument扩展
- readyState属性
- 实际开发中,最好是把 document.readState 当成一个指示器,以判断文档是否加载完毕
- document.readyState 属性有两个可能的值:
- loading,表示文档正在加载;
- complete,表示文档加载完成。
- compatMode 属性
- document.compatMode 的值指示浏览器当前处于什么渲染模式
- CSS1Compat 标准模式
- BackCompat 混杂模式
- head 属性
作为对 document.body(指向文档的< body>元素)的补充, HTML5 增加了 document.head 属性,指向文档的< head>元素。
# 字符集属性
characterSet 属性表示文档实际使用的字符集,也可以用来指定新字符集。这个属性的默认值是"UTF-16",但可以通过< meta>元素或响应头,以及新增的 characterSeet 属性来修改。
console.log(document.characterSet); // "UTF-16"
document.characterSet = "UTF-8";# 自定义数据属性
HTML5 允许给元素指定非标准的属性,但要使用前缀 data-以便告诉浏览器,这些属性既不包含与渲染有关的信息,也不包含元素的语义信息。
- 自定义数据属性可以通过元素的 dataset 属性来访问
- dataset 属性是一个 DOMStringMap 的实例,包含一组键/值对映射
# 插入标记
- innerHTML 属性
在读取 innerHTML 属性时,会返回元素所有后代的 HTML 字符串,包括元素、注释和文本节点。而在写入 innerHTML 时,则会根据提供的字符串值以新的 DOM 子树替代元素中原来包含的所有节点。如果赋值中不包含任何 HTML 标签,则直接生成一个文本节点。
- 旧 IE 中的 innerHTML
在所有现代浏览器中,通过innerHTML插入的< script>标签是不会执行的。而在IE8及之前的版本中,只要这样插入的< script>元素指定了defer属性,且< script>之前是“受控元素”(scoped element),那就是可以执行的。< script>元素与< style>或注释一样,都是“非受控元素”(NoScope element),也就是在页面上看不到它们。
- outerHTML 属性
读取 outerHTML 属性时,会返回调用它的元素(及所有后代元素)的 HTML 字符串。在写入outerHTML 属性时,调用它的元素会被传入的 HTML 字符串经解释之后生成的 DOM 子树取代。
- insertAdjacentHTML()与 insertAdjacentText() 接收两个参数:要插入标记的位置和要插入的 HTML 或文本。
- 第一个参数必须是下列值中的一个
- "beforebegin",插入当前元素前面,作为前一个同胞节点
- "afterbegin",插入当前元素内部,作为新的子节点或放在第一个子节点前面
- "beforeend",插入当前元素内部,作为新的子节点或放在最后一个子节点后面
- "afterend",插入当前元素后面,作为下一个同胞节点
- 第二个参数会作为 HTML 字符串解析或者作为纯文本解析
- 内存与性能问题
替换子节点可能在浏览器(特别是 IE)中导致内存问题。如果这种替换操作频繁发生,页面的内存占用就会持续攀升。在使用 innerHTML、outerHTML 和 insertAdjacentHTML()之前,最好手动删除要被替换的元素上关联的事件处理程序和 JavaScript 对象。
一般来讲,插入大量的新HTML使用innerHTML比使用多次DOM操作创建节点再插入来得更便捷。因为HTML解析器会解析设置给 innerHTML(或 outerHTML)的值。解析器在浏览器中是底层代码(通常是 C++代码),比JavaScript快得多。
- 跨站点脚本
如果页面中要使用用户提供的信息,则不建议使用innerHTML。与使用innerHTML获得的方便相比,防止XSS攻击更让人头疼。此时一定要隔离要插入的数据,在插入页面前必须毫不犹豫地使用相关的库对它们进行转义。
# scrollIntoView()
scrollIntoView()方法存在于所有HTML元素上,可以滚动浏览器窗口或容器元素以便包含元素进入视口。参数如下:
- alignToTop 是一个布尔值
- true:窗口滚动后元素的顶部与视口顶部对齐
- false:窗口滚动后元素的底部与视口底部对齐
- scrollIntoViewOptions 是一个选项对象
- behavior:定义过渡动画,可取的值为"smooth"和"auto",默认为"auto"
- block:定义垂直方向的对齐,可取的值为"start"、 "center"、 "end"和"nearest",默认为 "start"
- inline:定义水平方向的对齐,可取的值为"start"、 "center"、 "end"和"nearest",默认为 "nearest"
- 不传参数等同于 alignToTop 为 true
# 专有扩展
# children属性
children 属性是一个 HTMLCollection,只包含元素的 Element 类型的子节点。如果元素的子节点类型全部是元素类型,那 children 和 childNodes 中包含的节点应该是一样的。
# contains()方法
contains()方法应该在要搜索的祖先元素上调用,参数是待确定的目标节点。如果目标节点是被搜索节点的后代, contains()返回 true,否则返回 false。
使用 DOM Level 3 的 compareDocumentPosition()方法也可以确定节点间的关系。该方法会返回表示两个节点关系的位掩码。
# 插入标记
- innerText 属性
innerText 属性对应元素中包含的所有文本内容,无论文本在子树中哪个层级。在用于读取值时,innerText 会按照深度优先的顺序将子树中所有文本节点的值拼接起来。在用于写入值时,innerText会移除元素的所有后代并插入一个包含该值的文本节点。
- 因为设置 innerText 只能在容器元素中生成一个文本节点,所以为了保证一定是文本节点,就必须进行 HTML 编码
- innerText 属性可以用于去除 HTML 标签
- outerText 属性
outerText 与 innerText 是类似的,只不过作用范围包含调用它的节点。要读取文本值时,outerText 与 innerText 实际上会返回同样的内容。但在写入文本值时, outerText 就大不相同了。写入文本值时, outerText 不止会移除所有后代节点,而是会替换整个元素。
# 滚动
虽然 HTML5 把scrollIntoView()标准化了,但不同浏览器中仍然有其他专有方法。比如, scrollIntoViewIfNeeded()作为HTMLElement 类型的扩展可以在所有元素上调用。 scrollIntoViewIfNeeded(alingCenter)会在元素不可见的情况下,将其滚动到窗口或包含窗口中,使其可见;如果已经在视口中可见,则这个方法什么也不做。如果将可选的参数 alingCenter 设置为 true,则浏览器会尝试将其放在视口中央。
# DOM的演进
# XML命名空间
XML命名空间可以实现在一个格式规范的文档中混用不同的XML语言,而不必担心元素命名冲突。严格来讲,XML命名空间在XHTML中才支持,HTML并不支持。
命名空间是使用 xmlns 指定的。 XHTML 的命名空间是"http://www.w3.org/1999/xhtml",应该包含在任何格式规范的 XHTML 页面的< html>元素中,可以使用 xmlns 给命名空间创建一个前缀,格式为“xmlns: 前缀”,为避免混淆,属性也可以加上命名空间前缀。
如果文档中只使用一种 XML 语言,那么命名空间前缀其实是多余的,只有一个文档混合使用多种 XML 语言时才有必要。
- Node的变化 在 DOM2 中, Node 类型包含以下特定于命名空间的属性:
- localName,不包含命名空间前缀的节点名;
- namespaceURI,节点的命名空间 URL,如果未指定则为 null;
- prefix,命名空间前缀,如果未指定则为 null。
在节点使用命名空间前缀的情况下, nodeName 等于 prefix + ":" + localName。 DOM3 进一步增加了如下与命名空间相关的方法:
- isDefaultNamespace(namespaceURI),返回布尔值,表示 namespaceURI 是否为节点的默认命名空间;
- lookupNamespaceURI(prefix),返回给定 prefix 的命名空间 URI;
- lookupPrefix(namespaceURI),返回给定 namespaceURI 的前缀。
- Document的变化 DOM2 在 Document 类型上新增了如下命名空间特定的方法:
- createElementNS(namespaceURI, tagName),以给定的标签名 tagName 创建指定命名空间 namespaceURI 的一个新元素;
- createAttributeNS(namespaceURI, attributeName),以给定的属性名 attributeName 创建指定命名空间 namespaceURI 的一个新属性;
- getElementsByTagNameNS(namespaceURI, tagName),返回指定命名空间 namespaceURI 中所有标签名为 tagName 的元素的 NodeList。
- Element 的变化 DOM2 Core 对 Element 类型的更新主要集中在对属性的操作上。
- getAttributeNS(namespaceURI, localName),取得指定命名空间 namespaceURI 中名为 localName 的属性;
- getAttributeNodeNS(namespaceURI, localName),取得指定命名空间 namespaceURI 中名为 localName 的属性节点;
- getElementsByTagNameNS(namespaceURI, tagName),取得指定命名空间 namespaceURI 中标签名为 tagName 的元素的 NodeList;
- hasAttributeNS(namespaceURI, localName),返回布尔值,表示元素中是否有命名空间 namespaceURI 下名为 localName 的属性(注意, DOM2 Core 也添加不带命名空间的 hasAttribute()方法);
- removeAttributeNS(namespaceURI, localName),删除指定命名空间 namespaceURI 中名为 localName 的属性;
- setAttributeNS(namespaceURI, qualifiedName, value), 设置指定命名空间 namespaceURI 中名为 qualifiedName 的属性为 value;
- setAttributeNodeNS(attNode),为元素设置(添加)包含命名空间信息的属性节点 attNode。
- NamedNodeMap 的变化 NamedNodeMap 也增加了以下处理命名空间的方法。因为 NamedNodeMap 主要表示属性,所以这些方法大都适用于属性:
- getNamedItemNS(namespaceURI, localName),取得指定命名空间 namespaceURI 中名为 localName 的项;
- removeNamedItemNS(namespaceURI, localName),删除指定命名空间 namespaceURI 中名为 localName 的项;
- setNamedItemNS(node),为元素设置(添加)包含命名空间信息的节点。
# 其他变化
- DocumentType 的变化 DocumentType 新增了 3 个属性: publicId、 systemId 和 internalSubset。
- publicId、systemId 属性表示文档类型声明中有效但无法使用 DOM1 API 访问的数据
- internalSubset 用于访问文档类型声明中可能包含的额外定义
- Document 的变化
Document 类型的更新中唯一跟命名空间无关的方法是 importNode()。这个方法的目的是从其他文档获取一个节点并导入到新文档,以便将其插入新文档。每个节点都有一个 ownerDocument 属性,表示所属文档。如果调用 appendChild()方法时传入节点的 ownerDocument 不是指向当前文档,则会发生错误。而调用importNode()导入其他文档的节点会返回一个新节点,这个新节点的 ownerDocument 属性是正确的。
importNode()方法跟 cloneNode()方法类似,同样接收两个参数:要复制的节点和表示是否同时复制子树的布尔值,返回结果是适合在当前文档中使用的新节点。
- Node 的变化
DOM3 新增了两个用于比较节点的方法: isSameNode()和 isEqualNode()。两个方法都接收一个节点参数,如果这个节点与参考节点相同或相等,则返回 true。节点相同,意味着引用同一个对象;节点相等,意味着节点类型相同,拥有相等的属性( nodeName、 nodeValue 等),而且 attributes 和 childNodes 也相等(即同样的位置包含相等的值)。
DOM3 也增加了给 DOM 节点附加额外数据的方法。 setUserData()方法接收 3 个参数:键、值、处理函数,用于给节点追加数据。处理函数会在包含数据的节点被复制、删除、重命名或导入其他文档的时候执行,可以在这时候决定如何处理用户数据。
- 内嵌窗格的变化
DOM2 HTML 给 HTMLIFrameElement(即< iframe>,内嵌窗格)类型新增了一个属性,叫 contentDocument。这个属性包含代表子内嵌窗格中内容的 document 对象的指针。contentDocument 属性是 Document 的实例,拥有所有文档属性和方法,因此可以像使用其他 HTML 文档一样使用它。还有一个属性 contentWindow,返回相应窗格的 window 对象,这个对象上有一个 document 属性。
# 样式
HTML 中的样式有 3 种定义方式:外部样式表(通过< link>元素)、文档样式表(使用< style>元素)和元素特定样式(使用 style 属性)。
# 存取元素样式
任何支持 style 属性的 HTML 元素在 JavaScript 中都会有一个对应的 style 属性。这个 style 属性是CSSStyleDeclaration 类型的实例,其中包含通过 HTML style 属性为元素设置的所有样式信息,但不包含通过层叠机制从文档样式和外部样式中继承来的样式。HTML style 属性中的 CSS 属性在 JavaScript style 对象中都有对应的属性。因为 CSS 属性名使用连字符表示法(用连字符分隔两个单词 , 如 background-image),所以在JavaScript 中这些属性必须转换为驼峰大小写形式(如backgroundImage)。
大多数属性名会这样直接转换过来。但有一个 CSS 属性名不能直接转换, 因为float 是 JavaScript 的保留字,所以不能用作属性名。DOM2 Style 规定它在 style 对象中对应的属性应该是 cssFloat。
- DOM 样式属性和方法 DOM2 Style 规范也在 style 对象上定义了一些属性和方法。这些属性和方法提供了元素 style 属性的信息并支持修改
- cssText,包含 style 属性中的 CSS 代码,设置 cssText 是一次性修改元素多个样式最快捷的方式,因为所有变化会同时生效
- length,应用给元素的 CSS 属性数量,length 属性是跟 item()方法一起配套迭代 CSS 属性用的
- parentRule,表示 CSS 信息的 CSSRule 对象
- getPropertyPriority(propertyName),如果 CSS 属性 propertyName 使用了!important 则返回"important",否则返回空字符串
- getPropertyValue(propertyName),返回属性 propertyName 的字符串值
- item(index),返回索引为 index 的 CSS 属性名
- removeProperty(propertyName),从样式中删除 CSS 属性 propertyName,使用这个方法删除属性意味着会应用该属性的默认(从其他样式表层叠继承的)样式
- setProperty(propertyName, value, priority),设置 CSS 属性 propertyName 的值为 value, priority 是"important"或空字符串
- 计算样式
style 对象中包含支持 style 属性的元素为这个属性设置的样式信息,但不包含从其他样式表层叠继承的同样影响该元素的样式信息。DOM2 Style在 document.defaultView 上增加了 getComputedStyle()方法。这个方法接收两个参数:要取得计算样式的元素和伪元素字符串(如":after")。如果不需要查询伪元素,则第二个参数可以传 null。 getComputedStyle()方法返回一个 CSSStyleDeclaration 对象(与 style 属性的类型一样),包含元素的计算样式。
# 操作样式表
CSSStyleSheet 类型表示 CSS 样式表,包括使用< link>(HTMLLinkElement)元素和通过< style>(HTMLStyleElement)元素定义的样式表。CSSStyleSheet 类型是一个通用样式表类型,可以表示以任何方式在 HTML 中定义的样式表。另外,元素特定的类型允许修改 HTML 属性,而 CSSStyleSheet 类型的实例则是一个只读对象(只有一个属性例外,disabled)。通过< link>或< style>元素也可以直接获取 CSSStyleSheet 对象。 DOM 在这两个元素上暴露了 sheet 属性,其中包含对应的 CSSStyleSheet 对象。 CSSStyleSheet类型继承StyleSheet,后者可用作非 CSS样式表的基类。以下是CSSStyleSheet从 StyleSheet 继承的属性:
- disabled,布尔值,表示样式表是否被禁用了(可写)
- href,如果是使用< link>包含的样式表,则返回样式表的 URL,否则返回 null
- media,样式表支持的媒体类型集合
- ownerNode,指向拥有当前样式表的节点,在 HTML 中要么是< link>元素要么是< style>元素,如果当前样式表是通过@import 被包含在另一个样式表中,则这个属性值为 null
- parentStyleSheet,如果当前样式表是通过@import 被包含在另一个样式表中,则这个属性指向导入它的样式表
- title,ownerNode 的 title 属性
- type,字符串,表示样式表的类型。对 CSS 样式表来说,就是"text/css" 除了上面继承的属性, CSSStyleSheet 类型还支持以下属性和方法
- cssRules,当前样式表包含的样式规则的集合
- ownerRule,如果样式表是使用@import 导入的,则指向导入规则;否则为 null
- deleteRule(index),在指定位置删除 cssRules 中的规则
- insertRule(rule, index),在指定位置向 cssRules 中插入规则
- CSS规则 CSSRule 类型表示样式表中的一条规则。该类型也是一个通用基类,很多类型都继承它,但其中最常用的是表示样式信息的 CSSStyleRule。CSSStyleRule 对象上可用的属性:
- cssText,返回整条规则的文本。
- parentRule,如果这条规则被其他规则(如@media)包含,则指向包含规则,否则就是 null
- parentStyleSheet,包含当前规则的样式表
- selectorText,返回规则的选择符文本
- style,返回 CSSStyleDeclaration 对象,可以设置和获取当前规则中的样式
- type,数值常量,表示规则类型。对于样式规则,它始终为 1
- 创建规则 DOM 规定,可以使用 insertRule()方法向样式表中添加新规则。这个方法接收两个参数:规则的文本和表示插入位置的索引值。
sheet.insertRule("body { background-color: silver }", 0); // 使用 DOM 方法
- 删除规则 支持从样式表中删除规则的 DOM 方法是 deleteRule(),它接收一个参数:要删除规则的索引。
sheet.deleteRule(0); // 使用 DOM 方法# 元素尺寸
- 偏移尺寸 偏移尺寸( offset dimensions),包含元素在屏幕上占用的所有视觉空间。元素在页面上的视觉空间由其高度和宽度决定,包括所有内边距、滚动条和边框(但不包含外边距)。
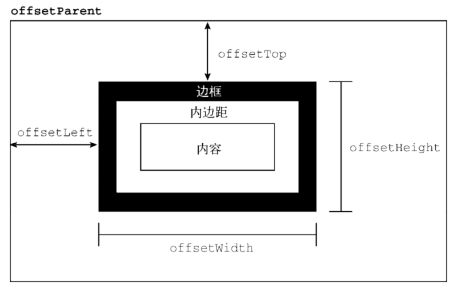
要确定一个元素在页面中的偏移量,可以把它的 offsetLeft 和 offsetTop 属性分别与 offsetParent 的相同属性相加,一直加到根元素。
- 客户端尺寸 元素的客户端尺寸(client dimensions)包含元素内容及其内边距所占用的空间。客户端尺寸只有两个相关属性: clientWidth 和 clientHeight。其中,clientWidth 是内容区宽度加左、右内边距宽度, clientHeight 是内容区高度加上、下内边距高度。
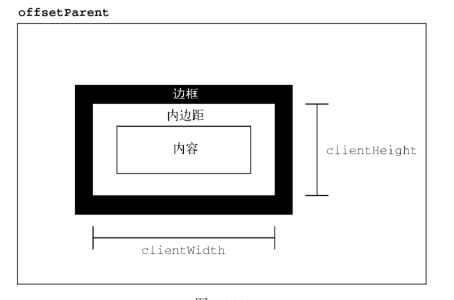
客户端尺寸实际上就是元素内部的空间,因此不包含滚动条占用的空间。这两个属性最常用于确定浏览器视口尺寸,即检测 document.documentElement 的 clientWidth 和 clientHeight。这两个属性表示视口(< html>或< body>元素)的尺寸。
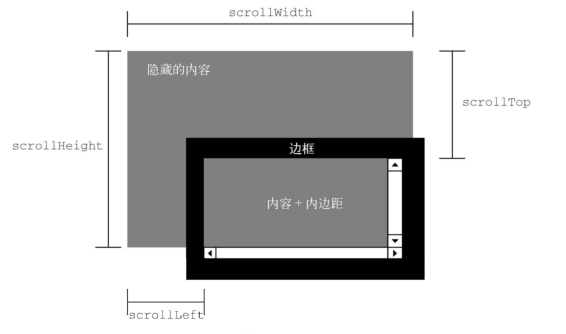
- 滚动尺寸 提供元素内容滚动距离的信息。有些元素,比如< html>无须任何代码就可以自动滚动,而其他元素则需要使用 CSS 的 overflow 属性令其滚动。
- scrollHeight,没有滚动条出现时,元素内容的总高度
- scrollLeft,内容区左侧隐藏的像素数,设置这个属性可以改变元素的滚动位置
- scrollTop,内容区顶部隐藏的像素数,设置这个属性可以改变元素的滚动位置
- scrollWidth,没有滚动条出现时,元素内容的总宽度
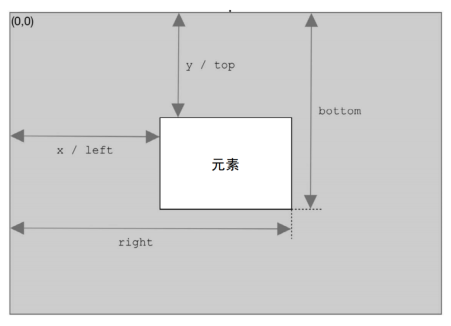
- 确定元素尺寸 getBoundingClientRect()方法,返回一个 DOMRect 对象,包含6个属性: left、 top、 right、 bottom、 height 和 width。这些属性给出了元素在页面中相对于视口的位置。
# 遍历
DOM2 Traversal and Range 模块定义了两个类型用于辅助顺序遍历 DOM 结构。这两个类型—— NodeIterator 和 TreeWalker——从某个起点开始执行对 DOM 结构的深度优先遍历。
# NodeIterator
通过 document.createNodeIterator()方法创建其实例,收4个参数
- root,作为遍历根节点的节点
- whatToShow,数值代码,表示应该访问哪些节点(一个位掩码,通过应用一个或多个过滤器来指定访问哪些节点)
- filter, NodeFilter 对象或函数,表示是否接收或跳过特定节点
- NodeFilter 对象只有一个方法 acceptNode(),如果给定节点应该访问就返回 NodeFilter.FILTER_ACCEPT,否则返回 NodeFilter.FILTER_SKIP
- filter 参数还可以是一个函数,与 acceptNode()的形式一样
- entityReferenceExpansion,布尔值,表示是否扩展实体引用 NodeIterator 的两个主要方法是 nextNode()和 previousNode()
- nextNode()方法在 DOM 子树中以深度优先方式进前一步,而 previousNode()则是在遍历中后退一步
- nextNode()和 previousNode()方法共同维护 NodeIterator 对 DOM 结构的内部指针,因此修改 DOM 结构也会体现在遍历中
# TreeWalker
TreeWalker 是 NodeIterator 的高级版,添加了如下在 DOM 结构中向不同方向遍历的方法
- parentNode(),遍历到当前节点的父节点
- firstChild(),遍历到当前节点的第一个子节点
- lastChild(),遍历到当前节点的最后一个子节点
- nextSibling(),遍历到当前节点的下一个同胞节点
- previousSibling(),遍历到当前节点的上一个同胞节点
TreeWalker 真正的威力是可以在 DOM 结构中四处游走。TreeWalker 类型也有一个名为 currentNode 的属性,表示遍历过程中上一次返回的节点(无论使用的是哪个遍历方法)。可以通过修改这个属性来影响接下来遍历的起点。
# 范围
# DOM范围
DOM2 在 Document 类型上定义了一个 createRange()方法,暴露在 document 对象上。使用这个方法可以创建一个 DOM 范围对象。与节点类似,这个新创建的范围对象是与创建它的文档关联的,不能在其他文档中使用。然后可以使用这个范围在后台选择文档特定的部分。创建范围并指定它的位置之后,可以对范围的内容执行一些操作,从而实现对底层 DOM 树更精细的控制。 每个范围都是 Range 类型的实例,拥有相应的属性和方法。
- startContainer,范围起点所在的节点(选区中第一个子节点的父节点)
- startOffset,范围起点在 startContainer 中的偏移量
- 如果 startContainer 是文本节点、注释节点或 CData 区块节点,则 startOffset 指范围起点之前跳过的字符数;否则,表示范围中第一个节点的索引
- endContainer,范围终点所在的节点(选区中最后一个子节点的父节点)
- endOffset,范围起点在 startContainer 中的偏移量
- commonAncestorContainer, 文档中以startContainer和endContainer为后代的最深的节点
# 简单选择
通过范围选择文档中某个部分最简单的方式,就是使用 selectNode()或 selectNodeContents()方法。这两个方法都接收一个节点作为参数,并将该节点的信息添加到调用它的范围。
- selectNode()方法选择整个节点,包括其后代节点
- selectNodeContents()只选择节点的后代
let range1 = document.createRange(),
range2 = document.createRange(),
p1 = document.getElementById("p1");
range1.selectNode(p1);
range2.selectNodeContents(p1);
选定节点或节点后代之后,还可以在范围上调用相应的方法,实现对范围中选区的更精细控制
- setStartBefore(refNode),把范围的起点设置到 refNode 之前,从而让 refNode 成为选区的第一个子节点
- setStartAfter(refNode),把范围的起点设置到 refNode 之后,从而将 refNode 排除在选区之外,让其下一个同胞节点成为选区的第一个子节点
- setEndBefore(refNode),把范围的终点设置到 refNode 之前,从而将 refNode 排除在选区之外、让其上一个同胞节点成为选区的最后一个子节点
- setEndAfter(refNode),把范围的终点设置到 refNode 之后,从而让 refNode 成为选区的最后一个子节点
# 复杂选择
要创建复杂的范围,需要使用 setStart()和 setEnd()方法。两个方法都接收两个参数:参照节点和偏移量。对 setStart()来说,参照节点会成为 startContainer,而偏移量会赋值给 startOffset。对 setEnd()而言,参照节点会成为 endContainer,而偏移量会赋值给 endOffset。
# 操作范围
创建范围之后,浏览器会在内部创建一个文档片段节点,用于包含范围选区中的节点。为操作范围的内容,选区中的内容必须格式完好。不过,范围能够确定缺失的开始和结束标签,从而可以重构出有效的 DOM 结构,以便后续操作。
- deleteContents():从文档中删除范围包含的节点
- extractContents(): 从文档中移除范围选区,返回范围对应的文档片段。(这样可以把范围选中的内容插入文档中其他地方)
- cloneContents():创建一个副本,返回的文档片段包含范围中节点的副本,而非实际的节点
# 范围插入
- insertNode():可以在范围选区的开始位置插入一个节点
- surroundContents():插入包含范围的内容
# 范围折叠
如果范围并没有选择文档的任何部分,则称为折叠(collapsed)。
- collapse():接收一个参数:布尔值,表示折叠到范围哪一端
- true 表示折叠到起点, false 表示折叠到终点
- 要确定范围是否已经被折叠,可以检测范围的 collapsed 属性
- 测试范围是否被折叠,能够帮助确定范围中的两个节点是否相邻
# 范围比较
如果有多个范围,则可以使用 compareBoundaryPoints()方法确定范围之间是否存在公共的边界(起点或终点)。这个方法接收两个参数:要比较的范围和一个常量值,表示比较的方式。
- 在第一个范围的边界点位于第二个范围的边界点之前时返回-1
- 在两个范围的边界点相等时返回 0
- 在第一个范围的边界点位于第二个范围的边界点之后时返回 1
# 复制范围
调用范围的cloneRange()方法可以复制范围。这个方法会创建调用它的范围的副本
# 清理
在使用完范围之后,最好调用detach()方法把范围从创建它的文档中剥离。调用detach()之后,就可以放心解除对范围的引用,以便垃圾回收程序释放它所占用的内存。