前言
在毕业设计中,用Java写下了第一个爬虫。2019年工作之后,从Python的requests原生爬虫库,学到分布式爬虫框架Scrapy,写了60个左右爬虫。然后写了十几篇有关于爬虫的文章。但大多都是围绕着程序设计、功能模块的角度写的,今天就从数据的角度出发,来看看爬虫程序是如何开发的。
数据
爬虫的目的就是获取数据,我总结了一下采集数据的步骤:
- 明确自己想要什么数据,这些数据有什么内容
- 去找有这些数据的网站
- 分析带有目标数据的网页,分析渲染数据的请求方式,是静态网页还是XHR异步
- 分析数据网页的层级。即从网站首页开始,如何层层递进到目标数据网页
- 程序开发(反爬验证、数据采集、数据清洗、数据入库)
所以说大多时候,爬虫程序的开发是以数据为驱动的。在开发程序前明确目标数据,在程序开发过程中清洗数据。
数据清洗其实是对每个数据中的字段进行处理。我在开发爬虫的过程中,常用的数据清洗方法有:字段缺失处理、数据转换、数据去重、异常值处理。 下面就使用Python的requests来开发实际操作一下,在数据去重等部分时,我也会使用Scrapy来实现,来展现一下Scrapy的优势所在。
关于Scrapy
大家可能对requets用的比较多,所以这里也简单得介绍一下Scrapy。
Scrapy是一个分布式爬虫框架,我把它比作成爬虫界的Spring。reqeusts就像是servlet一样,各种功能逻辑都需要自己去实现,而Spring做了集成,底层对用户透明。
就像我们知道,Spring是在application配置文件中初始化bean,在mapper中定义数据库操作一样,而使用者无需关心Spring是如何读取这些配置文件进行各种操作的。同样,Scrapy也提供了这样的功能配置。
所以说,Scrapy是一个爬虫框架,requests是一个爬虫模块,这就是两者区别的根本所在。下面是我画的Scrapy的架构图。
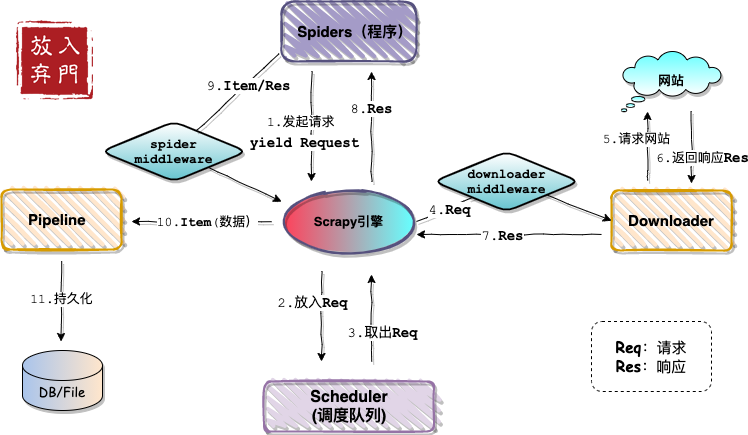
爬虫开发问题
无论使用Java的Jsoup也好,python的requests也罢,开发爬虫除了要解决网站反爬限制之外,还会面临下面几个问题:
1.分布式
爬虫程序一般只运行在一台主机上,如果是一模一样的爬虫程序部署在不同的主机上,那都是独立爬虫程序。如果想要弄一个分布式的爬虫,通常的思路是将爬虫程序分为url采集和数据采集两个部分。
现将url爬取下来放入到数据库中,然后通过where条件限制,或者直接使用redis的list结构,让不同主机上的爬虫程序读取到不同的url,然后进行数据爬取。
2.url去重
爬取数据的时候会经常遇到重复的url,如果重复爬取是不是浪费时间。通过url去重的思路就是:将爬取的url放入到集合中,每次爬取都去判断url是否存在于集合中。那么,如果程序中途停止了,这个内存中集合也将不复存在,再次启动程序,将无法判断哪些是已经爬取过的。
那么就用数据库,将已经爬取过的url插入到数据库中,这样就算重启程序,爬取过的url也不会丢失了。可是如果我就是想重新开始爬取,是不是还得手动清空数据库中的url表。每次查询数据库耗费的时间,这都是需要考虑的。
3.断点续爬
假如有1000个页面需要爬取,爬到第999个页面,进度条马上满格的时候,程序咯噔一下挂了,就差一个,但是还是没爬完啊,咋整?我选择重新启动程序,那么你说我怎么样才能直接从第999个开始爬取呢?
这里先讲讲我写的第一个爬虫:爬取10+个地市的poi信息。
实习,第一次开发爬虫,也不知道有高德poi接口啥的,于是就找了个网站来爬取poi信息。当时那个网站估计还在起步阶段,服务器带宽应该不高,访问速度是真的慢,而且动不动维护停站,所以我的程序也得跟着停止。如果每次启动都重新爬取,估计几年也爬不完,于是我想了个办法。
我先将所有地市下所有区县数据的条数(网站上有)先手动录入到数据库表中,每次重新启动爬虫程序的时候,先统计结果数据表中各个区县已经爬取的条数,与总条数进行对比。如果小于的话,说明还没有爬取完,然后通过某区县已爬取条数 / 网站每页展示条数计算出我已经爬取到此区县的页数,再通过余数定位到我爬到了此页面的第几个。通过这种方法,最后无丢失爬取了163w条数据。
换种思路,将爬取的url放到表中,重启程序开始爬取url的时候,先去判断url是否存在于数据表中,如果存在就不进行爬取,这样也能实现断点续爬。也是沿用了原始的url的去重的思路。
4.动态加载
在爬虫教程第六篇基金篇写了一个jsonp的动态加载,算是比较简单的一种,只要找到请求接口获取数据进行处理即可。爬虫教程第七篇写了电视猫的eval()的js加密,这算是很复杂的一种动态加载。请求接口的参数是加密的,需要耗费大量时间来分析密密麻麻的js,来计算出这个186位的参数。
so,有没有一种方式让我既能脱离阅读分析js,还能绕过动态加载?
sure!!首先关于动态加载,可以理解为浏览器内核通过执行js在前端渲染数据。那么我们在程序中搞个浏览器内核,我们直接获取js渲染后的页面数据不就可以了么?
通常使用selenium + chrome、phantomjs、pyvirtualdisplay来处理动态加载,但是或多或少都会有性能问题。
如果手动实现这些功能,费时费力。所以,如果我说关于上述问题,Scrapy都提供了现成的解决方案(开箱即用的插件),那么你会心动吗?
插件的介绍我就不多说了,在我的Scrapy爬虫文章里都有,如果有兴趣可以自行学习。言归正传,继续探讨数据清洗的问题。
采集数据
数据采集其实也属于数据清洗,同时也是数据清洗的前提。因为要将从获取的html或者json使用selector转换成csv格式的数据。所以在从网页获取数据时,需要先判断数据是静态网页渲染还是XHR异步请求。
1. 静态和XHR
静态网页渲染,就是用户访问网站发起请求时,是网站后台将数据渲染(填写)到html上,返回给浏览器展示,这里的数据渲染是后台来做。爬虫使用css或者Xpath选择器处理数据,对应Python的BS4或者Slector模块。
而XHR异步请求,是网站先将空的html返回给浏览器,然后浏览器再发起XHR(Ajax)来请求数据(大部分是Json),最后浏览器将数据渲染到空html上进行展示,所以这里的数据渲染是浏览器(前端)去做。所以Python使用json模块来处理数据。
2. 区分方法
这里就拿腾讯视频来简单介绍一下:
我们在F12进入开发者控制台时,可以看到动漫列表和热搜榜的数据。
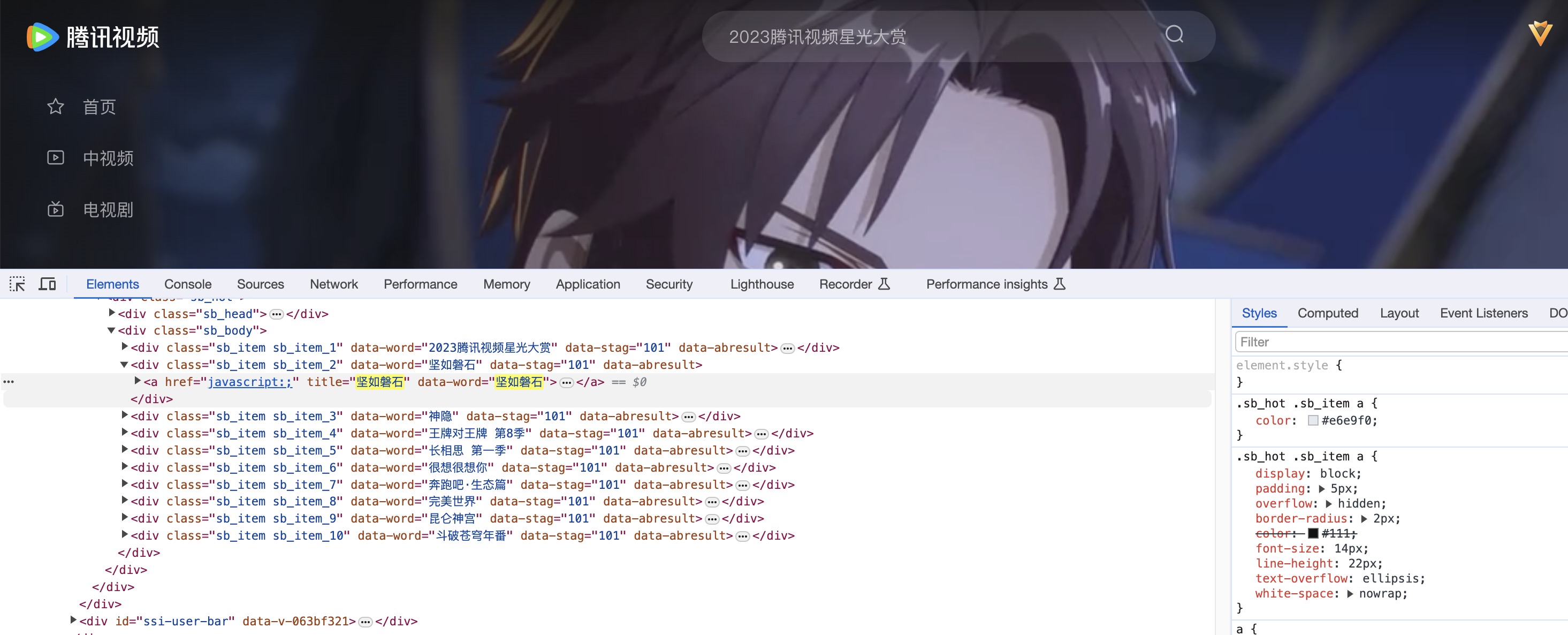
当我们点击热搜搜索框是时,热搜榜的div就会修改,这就是局部刷新的XHR异步加载。

我们在控制台看一下Network中的XHR信息。
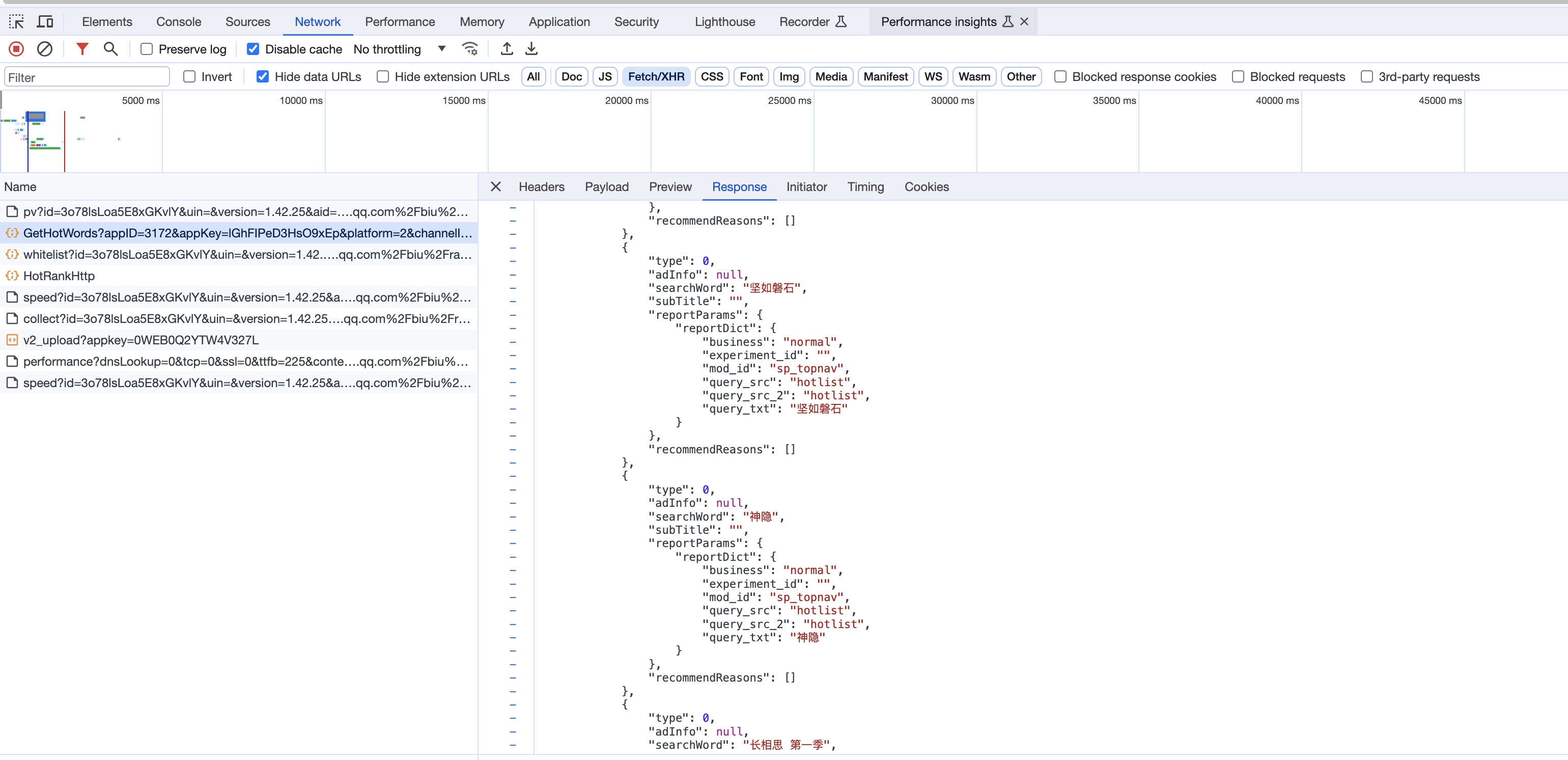
所以,判断是静态网页渲染还是XHR,有很多种方法。
- 可以根据自己的经验。例如热搜榜肯定是实时更新的,所以每次点击搜索框都是最新的,所以需要异步XHR
- 也可以在观察控制台的变化。当我点击搜索框时,代表热搜榜的div就会刷新,这就是XHR的表现
- 查看网页源码。网页源码表示后台返回的html原始网页。源码里面的数据就是静态网页渲染,源码里没有而网站页面上有的数据就是XHR

- 程序开发过程中去发现。
数据清洗
数据清洗可以发生在数据采集阶段,也可以发生在数据存储阶段,数据大都存储在数据库中,然后使用SQL进行数据清洗。但是我更偏向于前者,在源头制定好数据规范,这也是数据治理的一部分。所以,能在程序中处理,就不要把数据问题丢给使用者,
1. 数据去重
用SQL处理重复数据,使用distinct() 方法,传入的字段来确定数据的唯一性,例如一个视频的id。这个唯一字段需要自己在开发过程中去确定。
在原生爬虫requets中,我给出两种数据去重的方案:
- 依靠程序内部设计,使用set/list/map集合来判断数据是否唯一
- 依靠外部数据库,每次爬取都去数据库查询数据是否已存在
方案一优点是不需要与外部系统频繁交互,缺点就是程序重启集合数据就会清空,而且多线程情况下还要考虑线程安全。方案二稳定,但是需要依赖数据库,数据库的响应速度会影响程序的性能。在上面讲的poi爬虫就使用了方案二。
以上两种情况,都需要自己实现代码,各有利弊。而Scrapy使用的是scrapy-deltafetch插件实现的,里面使用了内嵌数据库BerkerlyDB,即不需要与外部系统交互,重启也不会丢失数据,只需要安装之后添加几行配置就能使用。感兴趣的话:可以跳转到scrapy-deltafetch文章连接进行学习:https://cloud.tencent.com/developer/article/2194956
这里先启动程序,爬取一个指定的url。
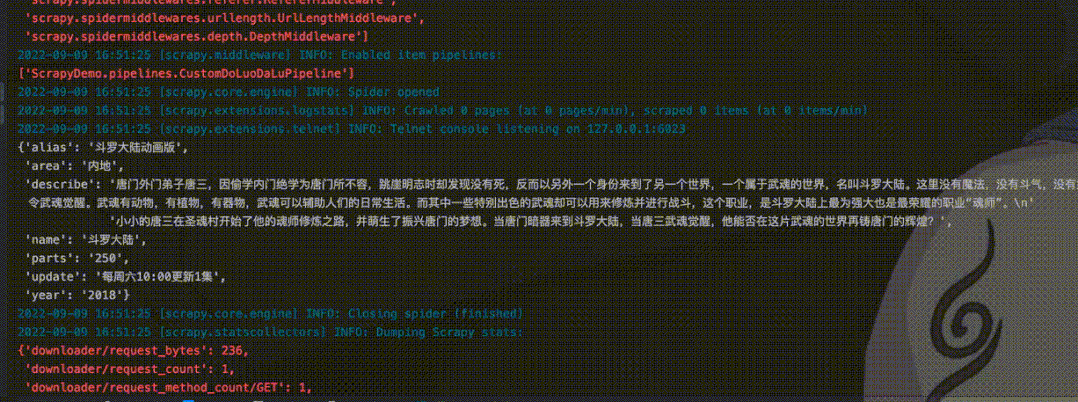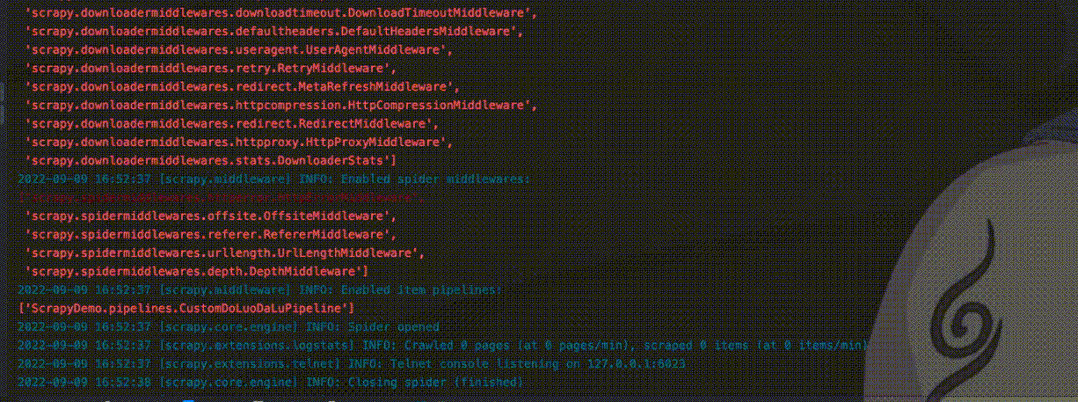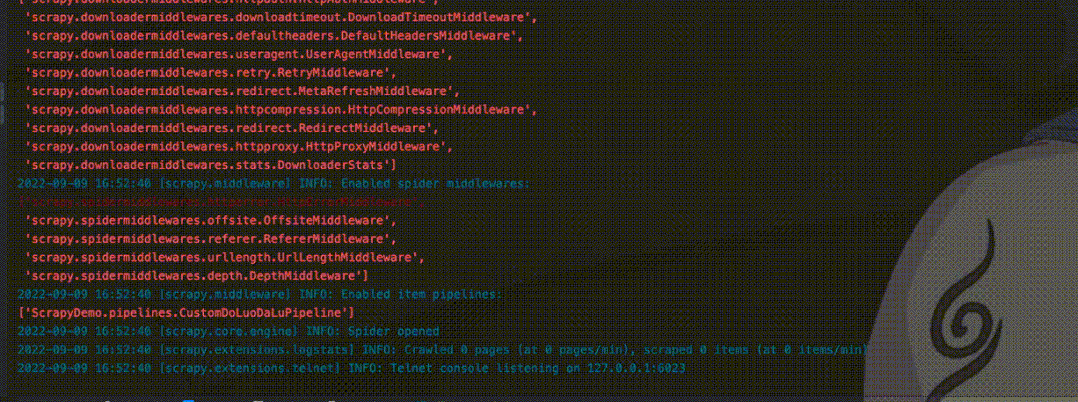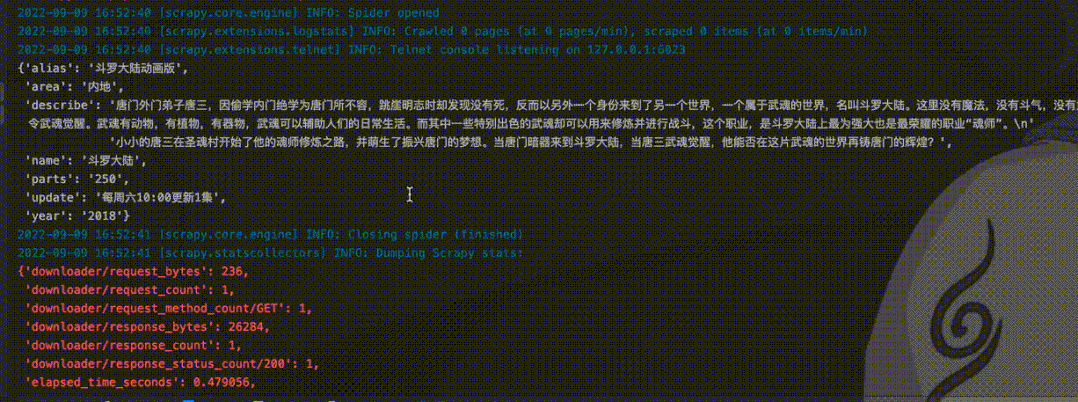
当爬取完上面url之后,第二次启动再遇到这个url时,就会看到Ignoring关键字,提示忽略已经爬取的url,不再进行爬取。

这里的用url作为数据去重的标准,如果想要重新爬取之前爬取过的url,启动前添加deltafetch_reset=1参数即可。
同时,这个插件也解决了爬虫问题中的断点续爬的问题。
2. 字段缺失处理
在爬取某些网页时,爬取的都是字段的并集。所以某些字段在某个网页并不存在,当使用选择器获取这些字段时,就会出现空指针或者数据越界的异常。
数据字段缺失还是比较好处理的。通常是使用if进行判断,然后设置缺省值。下面是scrapy处理字段缺失的代码:
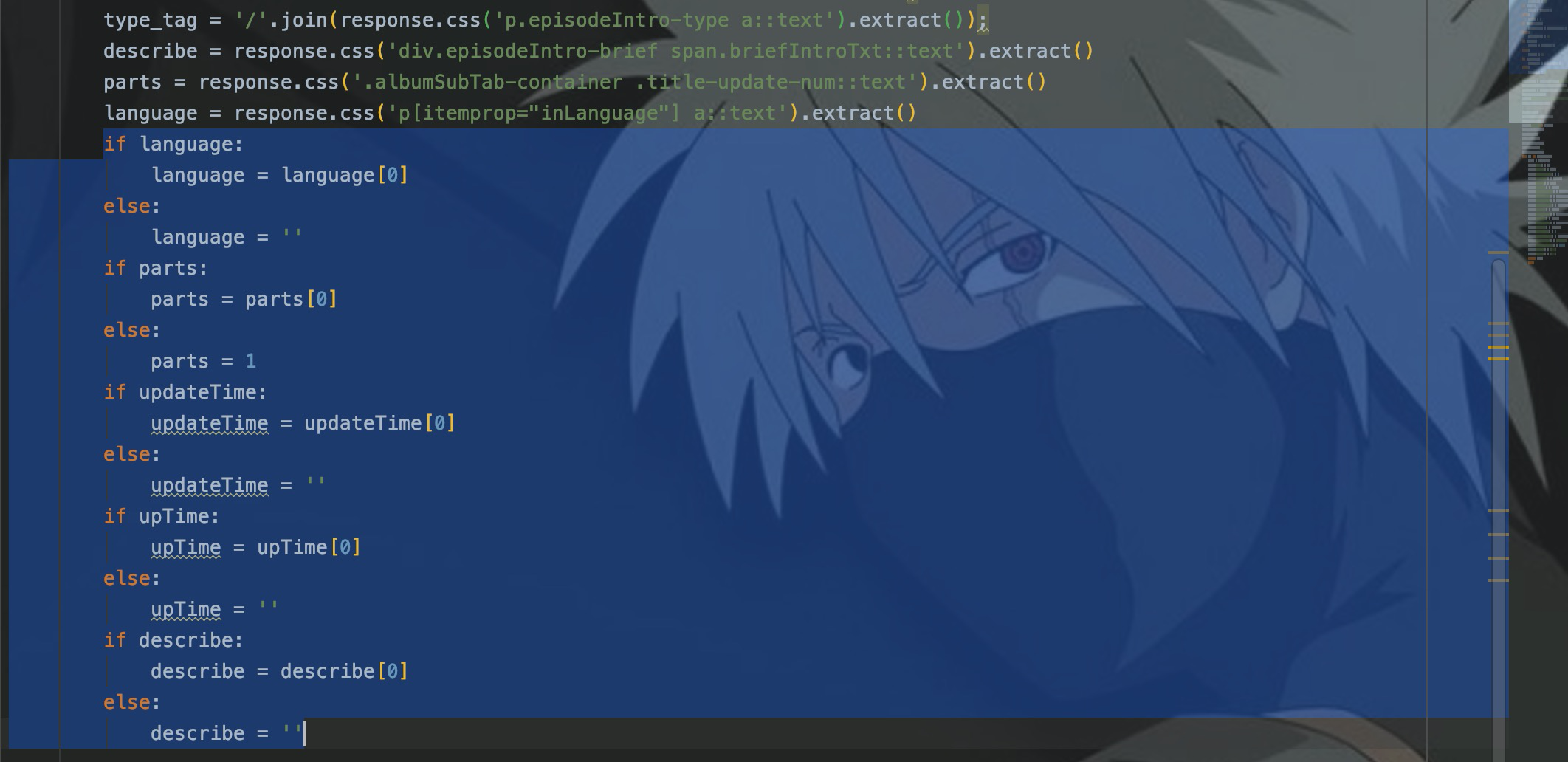
3. 数据转换
时间戳转换成日期、日期格式转换、字符串替换都算是数据转换。下面是Python实现日期格式转化的代码:
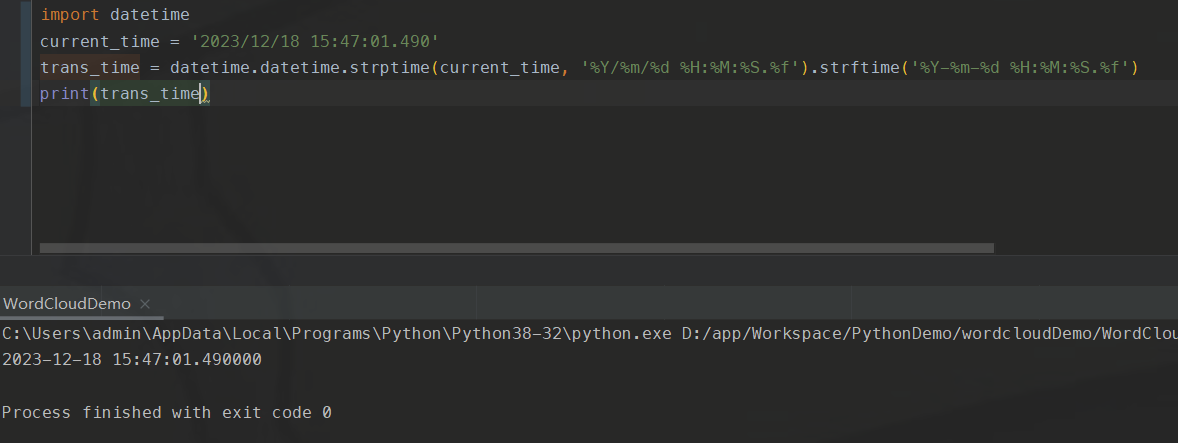
代码很简单,主要用到了datetime模块。
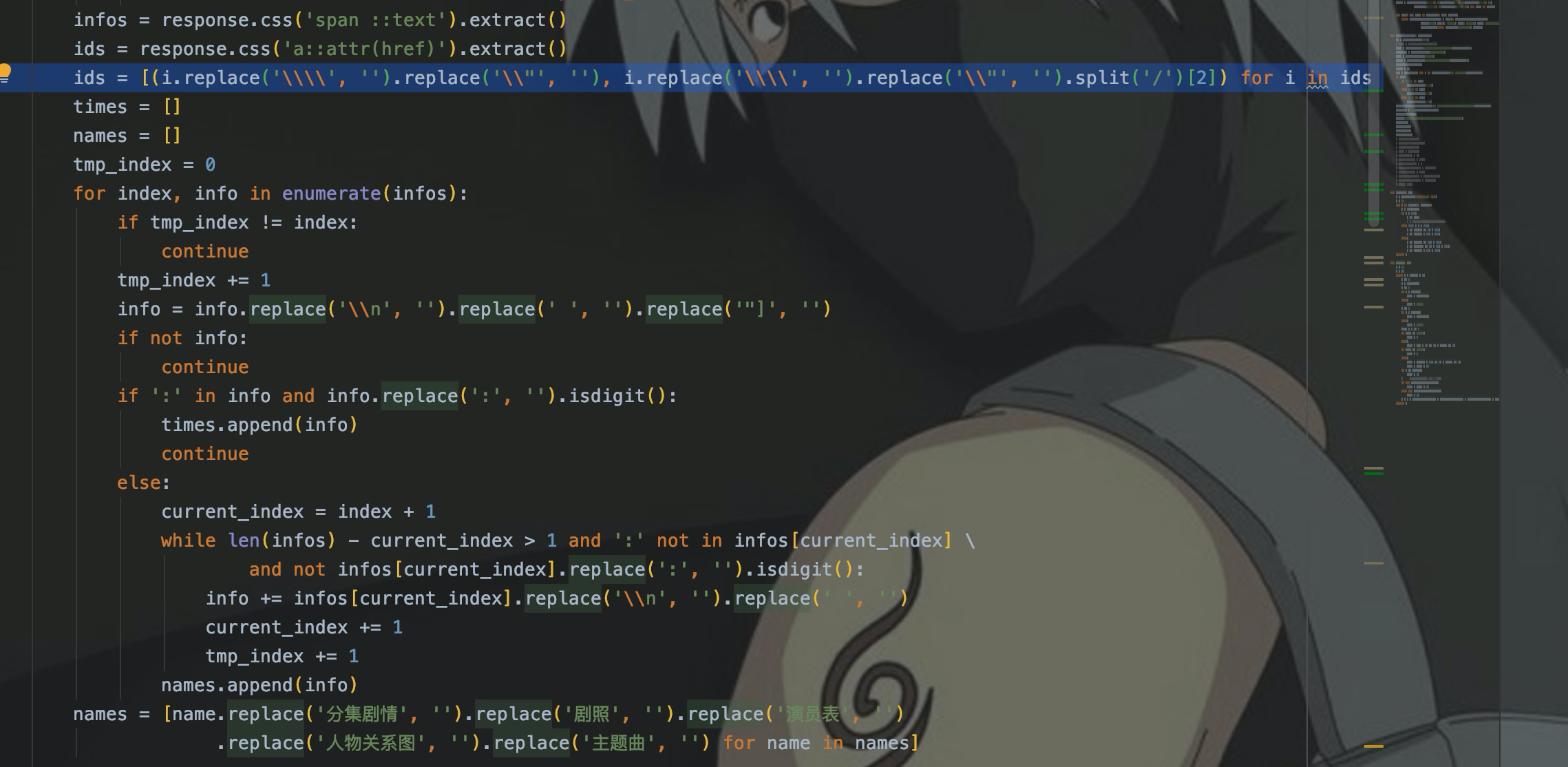
在上面的代码中,使用replace()进行了字符串的替换,其中包括将空格、换行等字符替换成空字符。
4. 异常值处理
异常值在爬虫开发中还是比较少见的,常见的有网页编码问题导致数据的乱码,还有一些数据填充的错误。这两个问题我记得遇到过,找了好久代码没有找到,这里就简单的说一下思路。
乱码就通过chardet.detect(str) 来检测一下字符串的编码格式,或者直接去看一下网页信息。使用charset关键字进行搜索:
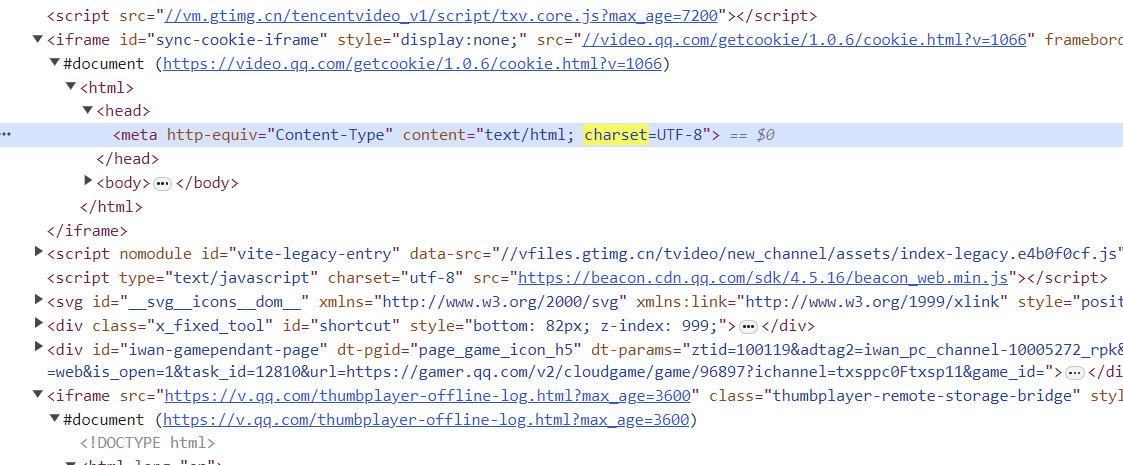
通过meta可以看到字符集是UTF-8。至于数据填充错误,只能具体情况具体分析,通过错误数据来反推,然后在程序中进行改进。
思考
看到这里可能会有人问:前面写的分布式、断点续爬、url去重以及动态加载和数据清洗有什么关系呢?
站在我个人的角度,我觉得是紧密联系的。我在上面谈及数据去重的时候,说了有两种方案:集合和数据库。如果在多台机器上使用分布式,集合去重这一个方案绝对是被pass了,因为你没法在多个进程共用一个集合对象。至于数据库,就要考虑如何设计才能保证数据的一致性了。
至于断点续爬、url去重就是数据去重的一个思路介绍。动态加载就是对数据采集中XHR的一个介绍。所以,爬虫也有很多东西可以学,学会requets ≠ 精通爬虫。
结语
上面就是个人在爬虫开发过程中,对常用的数据清洗方式的一个总结,都是一些简单的程序处理逻辑,希望对大家了解爬虫、开发爬虫有所帮助。
同时,我个人也写了关于requests爬虫入门的7篇文章,以及Scrapy爬虫的10篇文章,有兴趣的可以去参考一下。