axios 小程序_vscode使用uniapp
在小程序中使用请求,只能使用原生的wx.request,如果想要向axio一样使用三方包,只能使用flyio,不然会报错,同时flyio是属于多种兼容的可以放心使用到多端。
python httplib post
Python的模块 httplib 利用post进行表单数据提交.{用以实现自动发布这个功能,前提是不需要登录的情况;登录的情况还需要研究,暂时没搞定呢}
学习知识点:
httplib request的用法
getresponse() 用以进行返回数据
看下面的列子:
WordPress二级子目录怎么设置伪静态
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
nginx怎么设置301重定向
nginx设置301重定向的方法:
修改nginx中对应该网站的配置文件,例如:
#www.idc.net.conf
#301-START
if ($host ~ '^www.idc.net'){
return 301 http://idc.net$request_uri;
}
if ($host ~ '^idc.net'){
return 301 http://idc.net$request_uri;
}
#301-END
Scrapy爬虫中合理使用time.sleep和Request
在Scrapy爬虫中,我们需要深入分析time.sleep和Request对象对并发请求的影响。time.sleep函数用于在发起请求之前等待一段时间,而Request对象用于发送HTTP请求。我们必须仔细考虑这些操作对其他并发请求的潜在影响,以及在异步情况下可能会导致所有并发请求被阻塞。这种分析需要Python的协程机制、异步IO操作以及Scrapy框架的异步特性,以便全面理解这些操作对爬虫性能和效率的影响。
深入分析爬虫中time.sleep和Request的并发影响
在编写Python爬虫程序时,我们经常会遇到需要控制爬取速度以及处理并发请求的情况。本文将深入探讨Python爬虫中使用time.sleep()和请求对象时可能出现的并发影响,并提供解决方案。
Scrapy爬虫中合理使用time.sleep和Request
在Scrapy爬虫中,我们需要深入分析time.sleep和Request对象对并发请求的影响。time.sleep函数用于在发起请求之前等待一段时间,而Request对象用于发送HTTP请求。我们必须仔细考虑这些操作对其他并发请求的潜在影响,以及在异步情况下可能会导致所有并发请求被阻塞。这种分析需要Python的协程机制、异步IO操作以及Scrapy框架的异步特性,以便全面理解这些操作对爬虫性能和效率的影响。
不好意思,ELK 该换了!
最近客户有个新需求,就是想查看网站的访问情况,由于网站没有做google的统计和百度的统计,所以访问情况,只能通过日志查看,通过脚本的形式给客户导出也不太实际,给客户写个简单的页面,咱也做不到

Python 爬虫之 Request +re
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等

Request 爬虫的 SSL 连接问题深度解析
SSL(Secure Sockets Layer)是一种用于确保网络通信安全性的加密协议,广泛应用于互联网上的数据传输。在数据爬取过程中,爬虫需要与使用 HTTPS 协议的网站进行通信,这就牵涉到了 SSL 连接。本文将深入研究 Request 爬虫中的 SSL 连接问题,并提供解决方案以应对各种情况。
3700字!爬虫数据清洗已经不重要了,我这样的爬虫架构,如履薄冰
在毕业设计中,用Java写下了第一个爬虫。2019年工作之后,从Python的requests原生爬虫库,学到分布式爬虫框架Scrapy,写了60个左右爬虫。然后写了十几篇有关于爬虫的文章。但大多都是围绕着程序设计、功能模块的角度写的,今天就从数据的角度出发,来看看爬虫程序是如何开发的。

突破技术限制:使用 request-promise 库进行美团数据获取
美团是一家知名的外卖、酒店预订和团购服务平台,但有时我们可能需要获取一些数据,例如餐厅信息、菜单、评论等。在这篇文章中,我们将介绍如何使用 request-promise 库来爬取美团网站的数据,以及如何使用爬虫代理IP来提高采集效率。

Lua的Resty-Request库写的一个简单爬虫
Lua语言广泛应用于嵌入式领域、游戏开发等场景,而在Web开发中,特别是在Nginx服务器的OpenResty环境下,Lua也展现出强大的能力。Resty-Request是一个基于OpenResty的HTTP客户端库,提供了方便的API用于发送HTTP请求。在这篇文章中,我们将使用Resty-Request库,基于Lua语言编写一个简单的爬虫,实现网页数据的抓取。

揭秘豆瓣网站爬虫:利用lua-resty-request库获取图片链接
在网络数据采集领域,爬虫技术在图片获取方面具有广泛的应用。而豆瓣网站作为一个内容丰富的综合性平台,其图片资源也是广受关注的热点之一。本文将聚焦于如何利用Lua语言中的lua-resty-request库,高效地从豆瓣网站获取图片链接。我们将深入讨论如何通过定制请求头部和利用爬虫代理IP技术,提升爬虫的效率和匿名性,从而更好地应对豆瓣网站图片获取的挑战。

美餐支付 - PHP代碼实现
前言 背景
前段时间,因接手的项目需要实现 美餐支付 的功能对接
在此记录一下鄙人的实现步骤,方便有需要的道友参考借鉴
场景描述
我们的 “现代膳食” 售卖机,可以在屏幕上显示可配送的餐食
用户选中商品后,点击购买
选择 “美餐支付” 后,提示用户刷卡或扫描 美餐APP支付码
我们的设备端,会将读取到的 卡号/⼆维码 Code 传到服务接口,随后开发人员处理支付逻辑
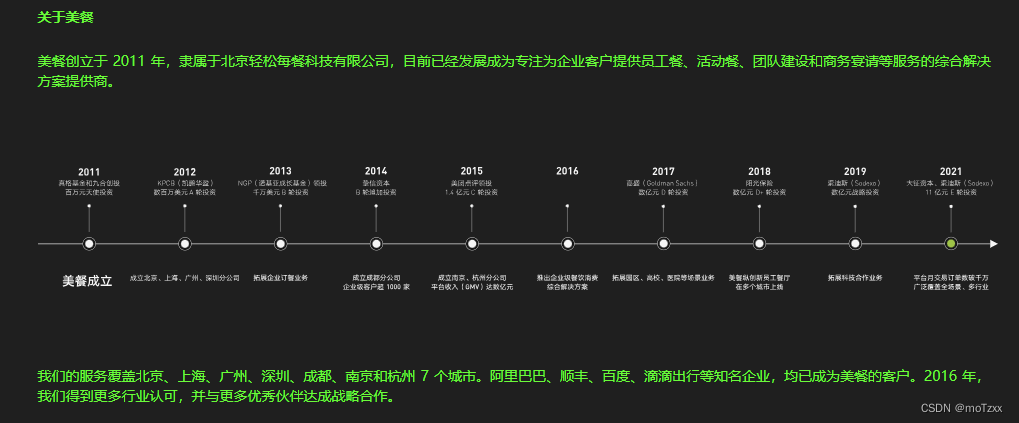
美餐
听客户描述,当地使用美餐卡的用户群比较普遍 …
实现步骤 以下为鄙人整理的开发过程,可根据自己的实际业务优化处理...
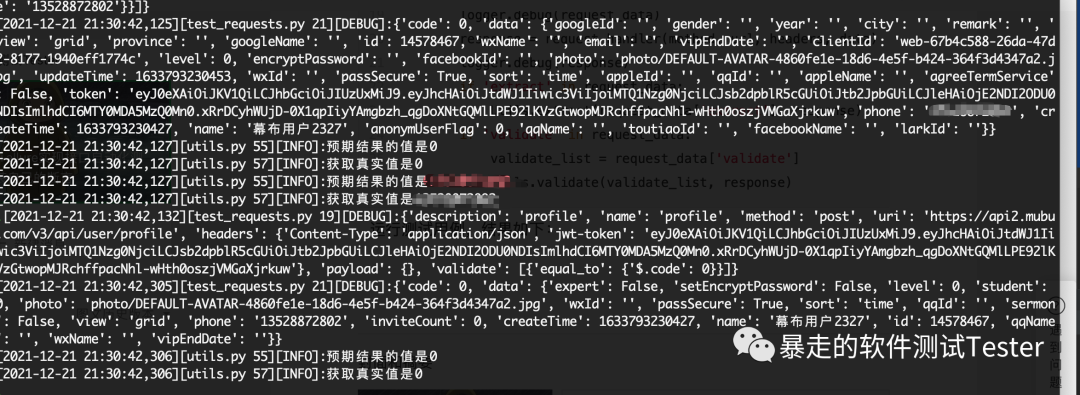
pytest+requests+allure实现接口自动化测试系列(9)-封装自己的断言
上一篇分享了接口之间的数据依赖,我们的测试结构数据,还有一部分没有说明,就是断言这一部分,下面的数据结构,我设计的需要断言的放在
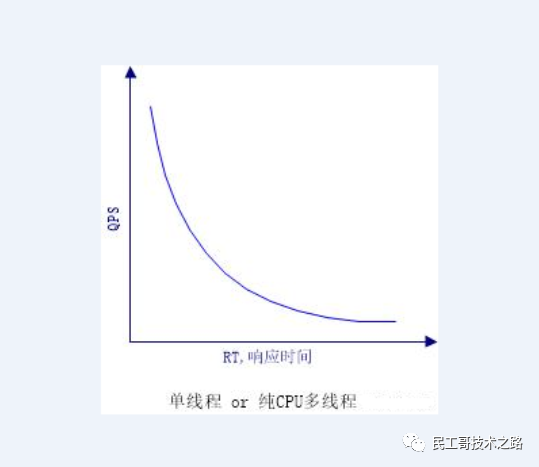
面试被问了几百遍的 QPS、TPS、RT !你还傻傻搞不清楚?
总有不少读者私下与我讨论,面试总被面试官问倒在 QPS、TPS、RT、吞吐量等这些高并发性能指标的理解上。所以,今天干脆来一个全面的科普详解。
揭秘豆瓣网站爬虫:利用lua-resty-request库获取图片链接
在网络数据采集领域,爬虫技术在图片获取方面具有广泛的应用。而豆瓣网站作为一个内容丰富的综合性平台,其图片资源也是广受关注的热点之一。本文将聚焦于如何利用Lua语言中的lua-resty-request库,高效地从豆瓣网站获取图片链接。我们将深入讨论如何通过定制请求头部和利用爬虫代理IP技术,提升爬虫的效率和匿名性,从而更好地应对豆瓣网站图片获取的挑战。

记录 OpenHarmony 使用 request.uploadFile 时踩的坑
上传文件依赖后台服务器,如果使用本地搭建的服务,是无法访问的,还没试过修改 hosts 文件是否可以。否则就会出现如下错误

SpringBoot允许跨域无效原因
关键F12看浏览器日志有没有Response to preflight request doesn't pass access control check,没有就说明访问路径错了