今天小婷儿给大家分享的是scrapy (四)基本配置。
scrapy (四)基本配置
scrapy使用细节配置
一、建立项目
1、scrapy startproject 项目名字
2、进入项目:
scrapy genspider 名字 不带http的根网址
3、默认模板(或改变模板)
默认模板:class HuaSpider(scrapy.Spider):
改变模板:scapy genspider -t crwal 名字(hua2) 不带http的根网址:
(class Hua2Spider(CrawlSpider)
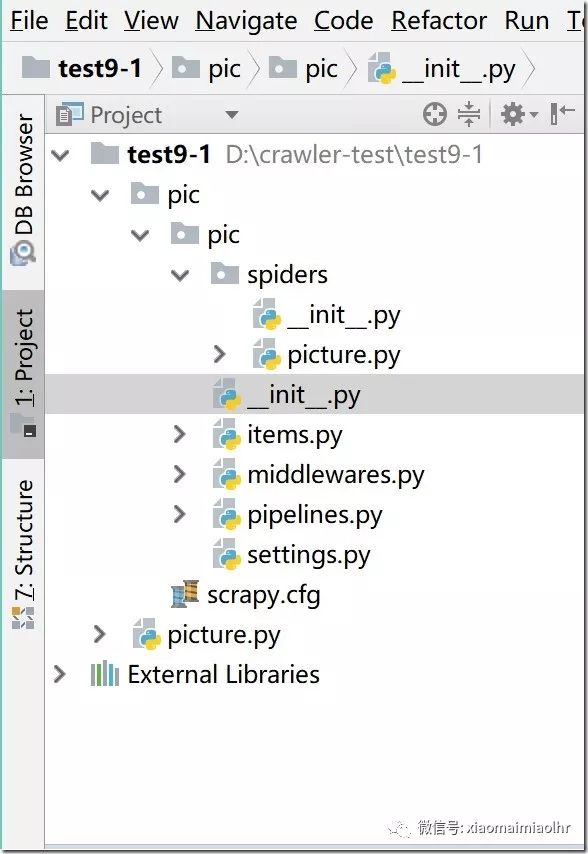
4、目录结构
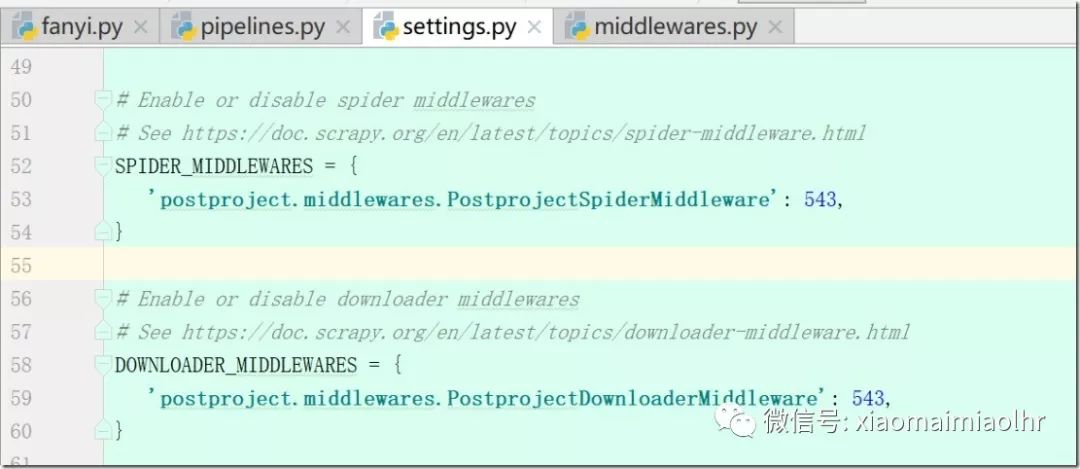
二、setting基本设置
1、log日志输出的级别:
INFO、ERROR......
LOG_LEVEL = 'ERROR'
2、将log写到文件中(自动创建log.txt)
LOG_FILE = './log.txt'
3、robots
是否遵守各大网站的爬虫规则(robots),默认是True,为了得到我们想要的数据,设置ROBOTSTXT_OBEY为F alse: ROBOTSTXT_OBEY = False
查看各大网站的规则:根网址+/robots.txt,例如https://www.baidu.com/robots.txt
4、设置代理middlewares.py
下载中间件设置:
1) 在setting中打开以下配置
DOWNLOADER_MIDDLEWARES = {
'postproject.middlewares.PostprojectDownloaderMiddleware': 543,
}
2)在middlewares.py中添加代理
在class PostprojectDownloaderMiddleware(object):
def process_request(self, request, spider):
公开代理格式:request.meta['proxy'] ='http://ip:port'
私密代理格式:request.meta['proxy'] = 'http://username:password@ip:port'
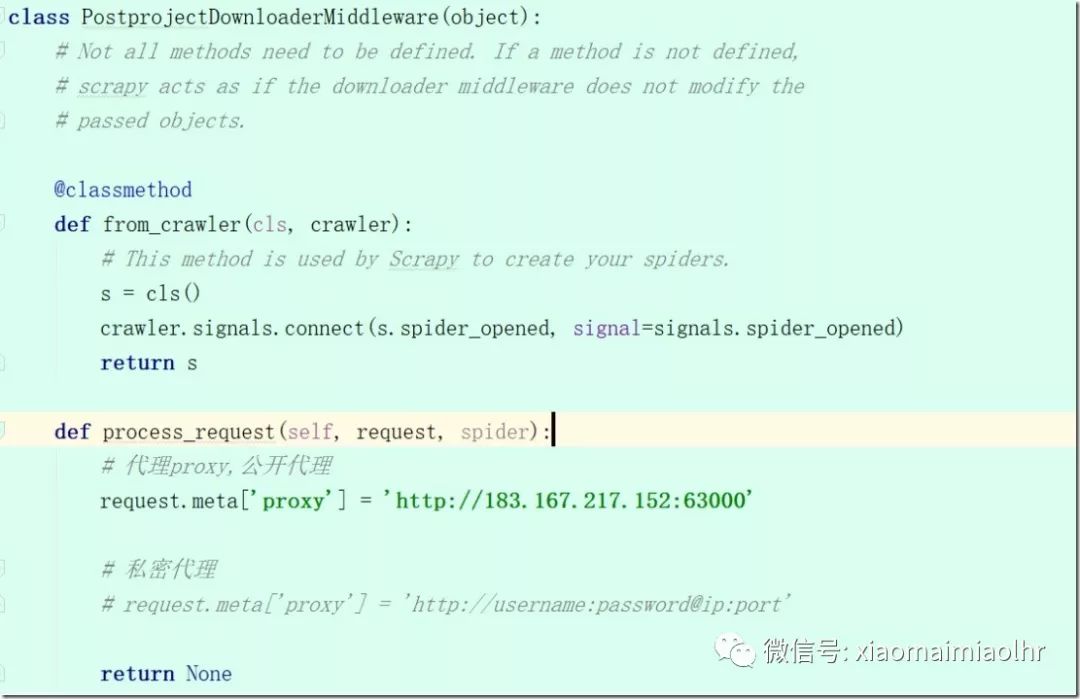
3)回到setting,解开下载中间件DOWNLOADER_MIDDLEWARES