❝人生就像钟摆,晃动在痛苦和无聊之间,其动力便是欲望 ❞
大家好,我是「柒八九」。
前言
在前几天师夷长技以制夷:跟着PS学前端技术文件中,我们提到了WorkBox,然后自己也对这块很感兴趣,所以就利用业余时间进行相关资源的查询学习和实践。在学习过程中发现,想要弄明白WorkBox,有一点很关键,我们需要搞懂Service Worker。
而在之前的
- Web性能优化之Worker线程(上)
- Web性能优化之Worker线程(下),
其实已经写过相关的文章,但是由于当时的技术所限,其中的内容只是单纯的从实现逻辑上,也就是API层面做了一次不完整归纳总结。总体从Worker层面的继承关系和简单使用方面出发。

而,今天我们再次对Service Worker做一次深度的剖析。当然,其中API的部分大家可以翻看之前的文章。下文中不再赘述。
好了,天不早了,干点正事哇。

我们能所学到的知识点
❝
- 前置知识点
- service workers 能为我们带来什么
- Service worker 的生命周期
- Service worker 缓存策略
- Service Worker 预缓存的陷阱
- 改进Service Worker开发体验
❞
1. 前置知识点
❝「前置知识点」,只是做一个概念的介绍,不会做深度解释。因为,这些概念在下面文章中会有出现,为了让行文更加的顺畅,所以将本该在文内的概念解释放到前面来。「如果大家对这些概念熟悉,可以直接忽略」
同时,由于阅读我文章的群体有很多,所以有些知识点可能「我视之若珍宝,尔视只如草芥,弃之如敝履」。以下知识点,请「酌情使用」。
❞
如何查看Service Worker
要查看正在运行的Service workers列表,我们可以在Chrome/Chromium中地址栏中输入chrome://serviceworker-internals/。
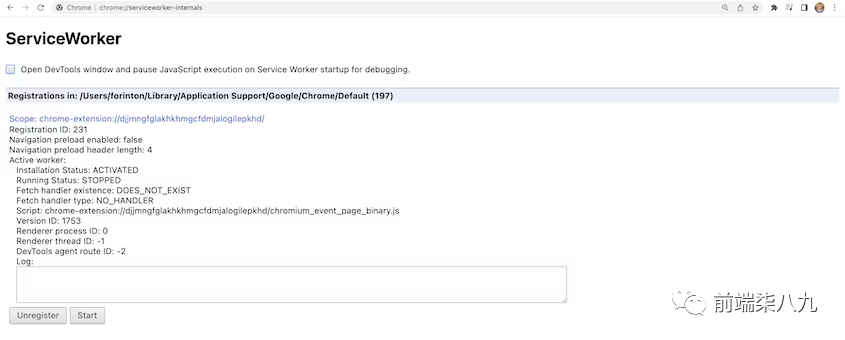
❝
chrome://xx包含了很多内置的功能,这块也是有很大的说道的。后期,会单独有一个专题来讲。(已经在筹划准备中....)
❞
Cache API
❝
Cache API为缓存的Request/Response对象对提供存储机制。例如,作为ServiceWorker生命周期的一部分
❞
Cache API像 workers 一样,是暴露在 window 作用域下的。尽管它被定义在 service worker 的标准中,但是它不必一定要配合 service worker 使用。
「一个域可以有多个命名 Cache 对象」。我们需要在脚本 (例如,在 ServiceWorker 中) 中处理缓存更新的方式。
- 除非明确地更新缓存,否则缓存将不会被更新;
- 除非删除,否则缓存数据不会过期
- 使用
CacheStorage.open(cacheName)打开一个Cache 对象,再使用Cache 对象的方法去处理缓存。 - 需要定期地清理缓存条目,因为每个浏览器都硬性限制了一个域下缓存数据的大小。
- 缓存配额使用估算值,可以使用
StorageEstimate API获得。 - 浏览器尽其所能去管理磁盘空间,但它有可能删除一个域下的缓存数据。
- 浏览器要么自动删除特定域的全部缓存,要么全部保留。
- 缓存配额使用估算值,可以使用
一些围绕service worker缓存的重要 API 方法包括:
CacheStorage.open用于创建新的 Cache 实例。Cache.add和Cache.put用于将「网络响应」存储在service worker缓存中。Cache.match用于查找 Cache 实例中的缓存响应。Cache.delete用于从 Cache 实例中删除缓存响应。- .....
❝
Cache.put,Cache.add和Cache.addAll只能在GET请求下使用。
❞
更多详情可以参考MDN-Cache[1]
Cache API 与 HTTP 缓存的区别
如果我们以前没有使用过Cache接口,可能会认为它与 HTTP 缓存相同,或者至少与 HTTP 缓存相关。但实际情况并非如此。
Cache接口是一个「完全独立于」HTTP 缓存的缓存机制- 用于影响
HTTP缓存的任何Cache-Control配置对存储在Cache接口中的资源没有影响。
❝可以将浏览器缓存看作是「分层的」。
HTTP缓存是一个由「键-值对驱动」的「低级缓存」,其中的指令在HTTP Header中表示。Cache接口是由「JavaScript API 驱动」的「高级缓存」。这比使用相对简单的HTTP键-值对具有更大的灵活性。
❞
2. service workers 能为我们带来什么
❝
Service workers是JavaScript层面的 API,「充当 Web 浏览器和 Web 服务器之间的代理」。它们的目标是通过提供离线访问以及提升页面性能来提高可靠性。 ❞
渐进增强,类似应用程序生命周期
Service workers是对现有网站的增强。这意味着如果使用Service workers的网站的用户使用不支持Service workers的浏览器访问网站,基本功能不会受到破坏。它是向下兼容的。
Service workers通过类似于桌面应用程序的生命周期逐渐增强网站。想象一下当从应用商城安装APP时会发生流程:
- 发出下载
APP的请求。 APP下载并安装。APP准备好使用并可以启动。APP进行新版本的更新。
Service worker也采用类似的生命周期,但采用「渐进增强」的方法。
- 在首次访问安装了新
Service worker的网页时,初始访问提供网站的基本功能,同时Service worker开始「下载」。 - 「安装」和「激活」
Service worker后,它将控制页面以提供更高的可靠性和速度。
采用 JavaScript 驱动的 Cache API
Service worker技术中不可或缺的一部分是Cache API,这是一种「完全独立于 HTTP 缓存的缓存机制」。Cache API可以在Service worker作用域内和「主线程」作用域内访问。该特性为用户操作与 Cache 实例的交互提供了许多可能性。
❝
HTTP缓存是通过HTTP Header中指定的「缓存指令」来影响的Cache API可以「通过 JavaScript 进行编程」
❞
这意味着可以根据网站的特有的逻辑来缓存网络请求的响应。例如:
- 在「首次请求静态资源时」将其存储在缓存中,然后在「后续请求中从缓存中获取」。
- 将
页面结构存储在缓存中,但在「离线情况下」从缓存中获取。 - 对于一些「非紧急的资源」,先从缓存中获取,然后在后台中通过网络再更新它。下次再获取该资源时候,就认为是最新的
- 网络采用「流式传输」处理部分内容,并与缓存中的应用程序拦截层组合以改善感知性能。
这些都是缓存策略的应用方向。缓存策略使离线体验成为可能,并「通过绕过 HTTP 缓存触发的高延迟重新验证检查提供更好的性能」。
异步和事件驱动的 API
在「网络上传输数据本质上是异步的」。请求资产、服务器响应请求以及下载响应都需要时间。所涉及的时间是多样且不确定的。Service workers通过「事件驱动」的 API 来适应这种异步性,「使用回调处理事件」,例如:
- 当
Service worker正在「安装」时。 - 当
Service worker正在「激活」时。 - 当
Service worker检测到网络请求时。
都可以使用addEventListener API 注册事件。所有这些事件都可以与Cache API进行交互。特别是在网络请求是离散的,运行回调的能力对于「提供所期望的可靠性和速度」至关重要。
在JavaScript中进行异步工作涉及使用Promises。因为Promises也支持async和await,这些JavaScript特性也可用于简化Service worker代码,从而提供更好的开发者体验。
预缓存和运行时缓存
Service worker与Cache实例之间的交互涉及两个不同的缓存概念:
- 「预缓存」(
Precaching caching) - 「运行时缓存」(
Runtime caching)
预缓存是需要提前缓存资源的过程,通常在Service worker「安装期间」进行。通过预缓存,「关键的静态资产和离线访问所需的材料可以被下载并存储在 Cache 实例中」。这种类型的缓存还可以提高需要预缓存资源的后续页面的页面速度。
运行时缓存是指在运行时从网络请求资源时应用缓存策略。这种类型的缓存非常有用,因为它保证了用户已经访问过的页面和资源的离线访问。
当在Service worker中使用这些方法时,可以为用户体验提供巨大的好处,并为普通的网页提供类似应用程序的行为。
与主线程隔离
Service workers与Web workers类似,它们的「所有工作都在自己的线程上进行」。这意味着Service workers的任务不会与主线程上的其他任务竞争。
我们就以Web Worker为例子,做一个简单的演示 在JavaScript中创建Web Worker并不是一项复杂的任务。
创建一个新的JavaScript文件,其中包含我们希望在工作线程中运行的代码。此文件不应包含对DOM的任何引用,因为它将无法访问DOM。
在我们的主JavaScript文件中,使用Worker构造函数创建一个新的Worker对象。此构造函数接受一个参数,即我们在第1步中创建的JavaScript文件的URL。
const worker = new Worker('worker.js');
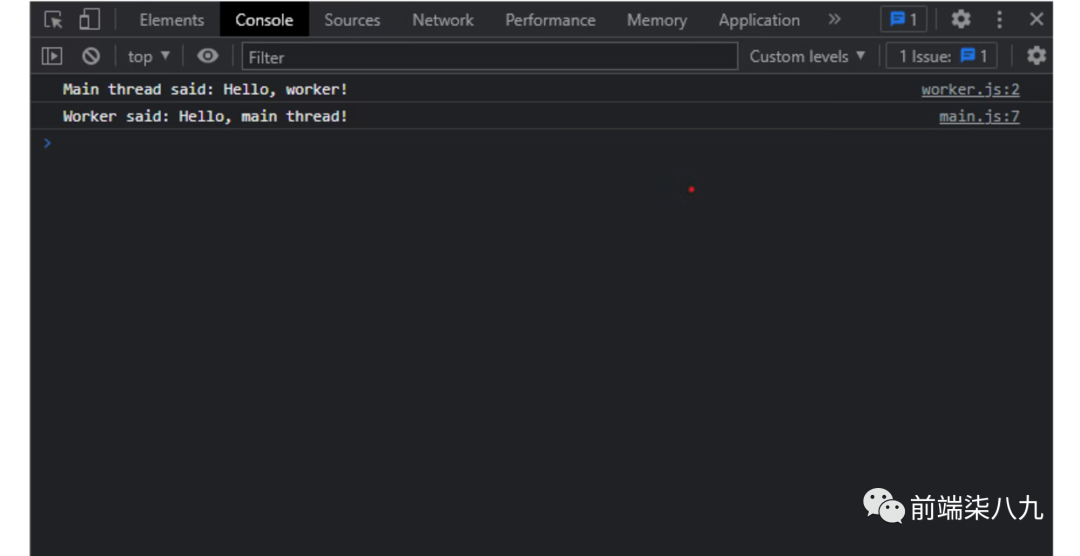
为Worker对象添加事件侦听器,以处理主线程和工作线程之间发送的消息。onmessage事件处理程序用于处理从工作线程发送的消息,而postMessage方法用于向工作线程发送消息。
worker.onmessage = function(event) {
console.log('Worker said: ' + event.data);
};
worker.postMessage('Hello, worker!');
在我们的工作线程JavaScript文件中,添加一个事件侦听器,以处理从主线程发送的消息,使用self对象的onmessage属性。我们可以使用event.data属性访问消息中发送的数据。
self.onmessage = function(event) {
console.log('Main thread said: ' + event.data);
self.postMessage('Hello, main thread!');
};
现在让我们运行Web应用程序并测试Worker。我们应该在控制台中看到打印的消息,指示主线程和工作线程之间已发送和接收消息。
3. Service worker 的生命周期
定义术语
在深入了解service worker的生命周期之前,我们先来了解一下与生命周期运作相关的「术语」(黑话)
控制和作用域
了解service worker运作方式的关键在于理解「控制」(control)。
- 由
service worker控制的页面允许service worker代表该页面进行拦截网络请求。 - 在给定的「作用域」(
scope)内,service worker能够为页面执行处理资源的相关工作。
作用域
一个service worker的作用域由其「在 Web 服务器上的位置确定」。如果一个service worker在位于/A/index.html的页面上运行,并且位于/A/sw.js上,那么该service worker的作用域就是/A/。
- 打开
https://service-worker-scope-viewer.glitch.me/subdir/index.html。将显示一条消息,说明没有service worker正在「控制」该页面。但是,该页面从https://service-worker-scope-viewer.glitch.me/subdir/sw.js注册了一个service worker。 - 「重新加载页面」。因为
service worker「已经注册并处于活动状态」,它正在「控制」页面。将显示一个包含service worker作用域、当前状态和其 URL 的表单。 - 现在打开
https://service-worker-scope-viewer.glitch.me/index.html。尽管在此origin上注册了一个service worker,但仍然会显示一条消息,说明没有当前的service worker。这是因为此页面不在已注册service worker的作用域内。
作用域限制了service worker控制的页面。在上面的例子中,这意味着从/subdir/sw.js加载的service worker只能「控制位于/subdir/或其子页面中」。
❝控制页面的
service worker仍然可以「拦截任何网络请求」,包括跨域资源的请求。作用域限制了由service worker控制的页面。 ❞
上述是默认情况下作用域工作的方式,但可以通过设置Service-Worker-Allowed响应头,以及通过向register方法传递作用域选项来进行覆盖。
除非有很好的理由将service worker的作用域限制为origin的子集,否则应「从 Web 服务器的根目录加载service worker,以便其作用域尽可能广泛」,不必担心Service-Worker-Allowed头部。
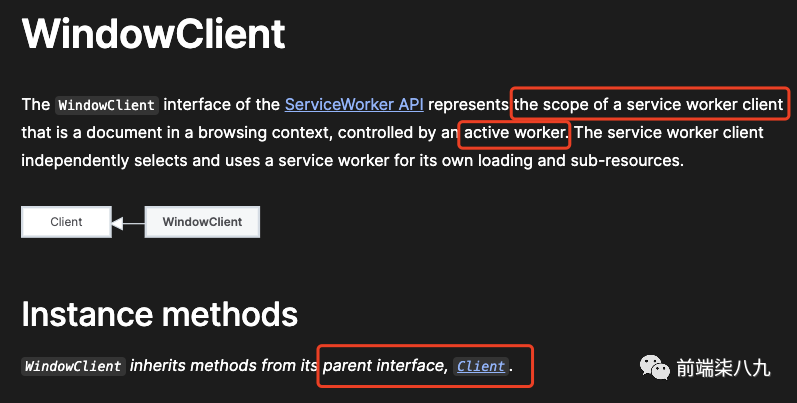
客户端
当说一个service worker正在控制一个页面时,实际上「是在控制一个客户端」。客户端是指URL位于该service worker作用域内的「任何打开的页面」。具体来说,这些是WindowClient的实例。
3.1 Service worker 在初始化时的生命周期
为了使service worker能够控制页面,首先必须将其部署。
让我们看看一个没有service worker的网站到部署全新service worker时,中间发生了啥?
1. 注册(Registration)
注册是service worker生命周期的「初始步骤」:
<script>
// 直到页面完全加载后再注册service worker
window.addEventListener("load", () => {
// 检查service worker是否可用
if ("serviceWorker" in navigator) {
navigator.serviceWorker
.register("/sw.js")
.then(() => {
console.log("Service worker 注册成功!");
})
.catch((error) => {
console.warn("注册service worker时发生错误:");
console.warn(error);
});
}
});
</script>
此代码在「主线程」上运行,并执行以下操作:
- 因为用户「首次访问网站时」没有注册
service worker,所以等待「页面完全加载后」再注册一个。这样可以避免在service worker预缓存任何内容时出现「带宽争用」。 - 尽管
service worker得到了广泛支持,但进行「特性检查」可以避免在不支持它的浏览器中出现错误。 - 当页面完全加载后,如果支持
service worker,则注册/sw.js。
还有一些关键要点:
Service worker仅在HTTPS或localhost上可用。- 如果
service worker的内容包含「语法错误」,注册会失败,并丢弃service worker。 service worker在一个作用域内运行。在这里,作用域是整个origin,因为它是从根目录加载的。- 当注册开始时,
service worker的状态被设置为installing。
❝一旦注册完成,「安装」就开始了。 ❞
2. 安装(Installation)
service worker在注册后触发其install事件。install「只会在每个service worker中调用一次,直到它被更新才会再次触发」。可以使用addEventListener在worker的作用域内注册install事件的回调:
// /sw.js self.addEventListener("install", (event) => { const cacheKey = "前端柒八九_v1";
event.waitUntil(
caches.open(cacheKey).then((cache) => {
// 将数组中的所有资产添加到'前端柒八九_v1'的Cache实例中以供以后使用。
return cache.addAll([
"/css/global.bc7b80b7.css",
"/css/home.fe5d0b23.css",
"/js/home.d3cc4ba4.js",
"/js/A.43ca4933.js",
]);
})
);
});
这会创建一个新的Cache实例并对资产进行「预缓存」。其中有一个event.waitUntil。event.waitUntil接受一个Promise,并等待该Promise被解决。
在这个示例中,这个Promise执行两个异步操作:
- 创建一个名为
前端柒八九_v1的新Cache实例。 - 在创建缓存之后,使用其异步的
addAll方法「预缓存」一个资源URL数组。
如果传递给event.waitUntil的Promise被「拒绝,安装将失败」。如果发生这种情况,service worker将被「丢弃」。
如果Promise被解决,安装成功,service worker的状态将更改为installed,然后进入「激活」阶段。
3. 激活(Activation)
如果注册和安装成功,service worker将被「激活」,其状态将变为activating。在service worker的activate事件中可以进行激活期间的工作。在此事件中的一个典型任务是「清理旧缓存」,但对于「全新 service worker」,目前还不相关。
对于新的service worker,「安装成功后,激活会立即触发」。一旦激活完成,service worker的状态将变为activated。
❝默认情况下,新的
service worker直到「下一次导航或页面刷新之前才会开始控制页面」。
❞
3.2 处理 service worker 的更新
一旦部署了第一个service worker,它很可能需要在以后进行更新。例如,如果请求处理或预缓存逻辑发生了变化,就可能需要进行更新。
更新发生的时机
浏览器会在以下情况下检查service worker的更新:
- 用户导航到
service worker作用域内的页面。 - 调用
navigator.serviceWorker.register()并「传入与当前安装的 service worker 不同的 URL」 - 调用
navigator.serviceWorker.register()并「传入与已安装的 service worker 相同的 URL」,但具有「不同的作用域」。
更新的方式
了解浏览器何时更新service worker很重要,但“如何”也很重要。假设service worker的URL或作用域未更改,「只有在其内容发生变化时,当前安装的service worker才会更新到新版本」。
浏览器以几种方式检测变化:
importScripts请求的脚本的「字节级更改」。service worker的「顶级代码的任何更改」,这会影响浏览器生成的指纹。
为确保浏览器能够可靠地检测service worker内容的变化,「不要使用 HTTP 缓存保留它,也不要更改其文件名」。当导航到service worker作用域内的新页面时,浏览器会自动执行更新检查。
手动触发更新检查
关于更新,注册逻辑通常不应更改。然而,一个例外情况可能是「网站上的会话持续时间很长」。这可能在「单页应用程序」中发生,因为导航请求通常很少,应用程序通常在应用程序生命周期的开始遇到一个导航请求。在这种情况下,可以在「主线程上手动触发更新」:
navigator.serviceWorker.ready.then((registration) => {
registration.update();
});
对于传统的网站,或者在用户会话不持续很长时间的任何情况下,手动更新可能不是必要的。
安装(Installation)
当使用打包工具生成「静态资源」时,这些资源的「名称中会包含哈希值」,例如framework.3defa9d2.js。假设其中一些资源被预缓存以供以后离线访问,这将需要对service worker进行更新以预缓存新的资源:
self.addEventListener("install", (event) => {
const cacheKey = "前端柒八九_v2";
event.waitUntil(
caches.open(cacheKey).then((cache) => {
// 将数组中的所有资产添加到'前端柒八九_v2'的Cache实例中以供以后使用。
return cache.addAll([
"/css/global.ced4aef2.css",
"/css/home.cbe409ad.css",
"/js/home.109defa4.js",
"/js/A.38caf32d.js",
]);
})
);
});
与之前的install事件示例有两个方面不同:
- 创建了一个具有
key为前端柒八九_v2的「新 Cache 实例」。 - 预缓存资源的名称已更改。(
/css/global.bc7b80b7.css变为/css/global.ced4aef2.css)
❝更新后的
service worker会与先前的service worker并存。这意味着旧的service worker仍然控制着任何打开的页面。刚才安装的新的service worker进入等待状态,直到被激活。
❞
默认情况下,新的service worker将在「没有任何客户端由旧的service worker控制时激活」。这发生在相关网站的所有打开标签都关闭时。
激活(Activation)
当安装了新的service worker并结束了等待阶段时,它会被激活,并丢弃旧的service worker。在更新后的service worker的activate事件中执行的常见任务是「清理旧缓存」。通过使用caches.keys获取所有打开的 Cache 实例的key,并使用caches.delete删除不在允许列表中的所有旧缓存:
self.addEventListener("activate", (event) => {
// 指定允许的缓存密钥
const cacheAllowList = ["前端柒八九_v2"];
// 获取当前活动的所有Cache实例。
event.waitUntil(
caches.keys().then((keys) => {
// 删除不在允许列表中的所有缓存:
return Promise.all(
keys.map((key) => {
if (!cacheAllowList.includes(key)) {
return caches.delete(key);
}
})
);
})
);
});
❝旧的缓存不会自动清理。我们需要自己来做,否则可能会超过存储配额。
❞
由于第一个service worker中的前端柒八九_v1已经过时,缓存允许列表已更新为指定前端柒八九_v2,这将删除具有不同名称的缓存。
「激活事件在旧缓存被删除后完成」。此时,新的service worker将控制页面,最终替代旧的service worker!
4. Service worker 缓存策略
要有效使用service worker,有必要采用一个或多个缓存策略,这需要对Cache API有一定的了解。
缓存策略是service worker的fetch事件与Cache API之间的交互。如何编写缓存策略取决于不同情况。
普通的 Fetch 事件
缓存策略的另一个重要的用途就是与service worker的fetch事件配合使用。我们已经听说过一些关于「拦截网络请求」的内容,而service worker内部的fetch事件就是处理这种情况的:
// 建立缓存名称
const cacheName = "前端柒八九_v1";self.addEventListener("install", (event) => {
event.waitUntil(caches.open(cacheName));
});self.addEventListener("fetch", async (event) => {
// 这是一个图片请求
if (event.request.destination === "image") {
// 打开缓存
event.respondWith(
caches.open(cacheName).then((cache) => {
// 从缓存中响应图片,如果缓存中没有,就从网络获取图片
return cache.match(event.request).then((cachedResponse) => {
return (
cachedResponse ||
fetch(event.request.url).then((fetchedResponse) => {
// 将网络响应添加到缓存以供将来访问。
// 注意:我们需要复制响应以保存在缓存中,同时使用原始响应作为请求的响应。
cache.put(event.request, fetchedResponse.clone());// 返回网络响应 return fetchedResponse; }) ); }); }) );
} else {
return;
}
});
上面的代码执行以下操作:
- 检查请求的
destination属性,以查看是否是图像请求。 - 如果图像在
service worker缓存中,则从缓存中提供它。如果没有,从网络获取图像,将响应存储在缓存中,并返回网络响应。 - 所有其他请求都会通过
service worker,不与缓存互动。
fetch事件的事件对象包含一个request属性,其中包含一些有用的信息,可帮助我们识别每个请求的类型:
url,表示当前由fetch事件处理的网络请求的URL。method,表示请求方法(例如GET或POST)。mode,描述请求的模式。通常使用值navigate来区分对HTML文档的请求与其他请求。destination,以一种避免使用所请求资产的文件扩展名的方式描述所请求内容的类型。
「异步操作是关键」。我们还记得install事件提供了一个event.waitUntil方法,它接受一个promise,并在激活之前等待其解析。fetch事件提供了类似的event.respondWith方法,我们可以使用它来返回异步fetch请求的结果或Cache接口的match方法返回的响应。
缓存策略
1. 仅缓存(Cache only)
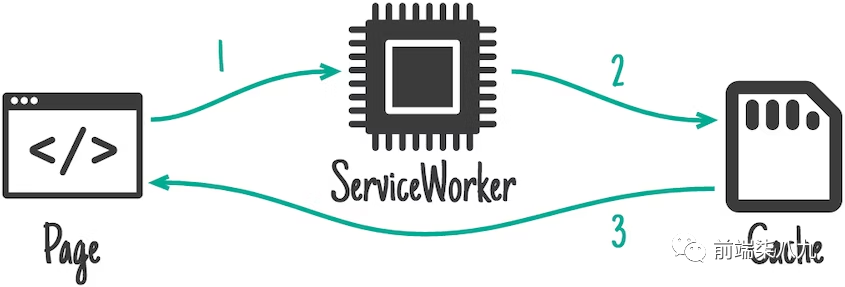
展示了从页面到service worker到缓存的流程。
「仅缓存」运作方式:当service worker控制页面时,「匹配的请求只会进入缓存」。这意味着为了使该模式有效,「任何缓存的资源都需要在安装时进行预缓存」,而「这些资源在service worker更新之前将不会在缓存中进行更新」。
// 建立缓存名称
const cacheName = "前端柒八九_v1";// 要预缓存的资产
const preCachedAssets = ["/A.jpg", "/B.jpg", "/C.jpg", "/D.jpg"];self.addEventListener("install", (event) => {
// 在安装时预缓存资产
event.waitUntil(
caches.open(cacheName).then((cache) => {
return cache.addAll(preCachedAssets);
})
);
});self.addEventListener("fetch", (event) => {
const url = new URL(event.request.url);
const isPrecachedRequest = preCachedAssets.includes(url.pathname);
if (isPrecachedRequest) {
// 从缓存中获取预缓存的资产
event.respondWith(
caches.open(cacheName).then((cache) => {
return cache.match(event.request.url);
})
);
} else {
// 转到网络
return;
}
});
在上面的示例中,数组中的资产在安装时被预缓存。当service worker处理fetch请求时,我们「检查fetch事件处理的请求 URL 是否在预缓存资产的数组中」。
- 如果是,我们从缓存中获取资源,并跳过网络。
- 其他请求将通过网络传递,只经过网络。
2. 仅网络(Network only)
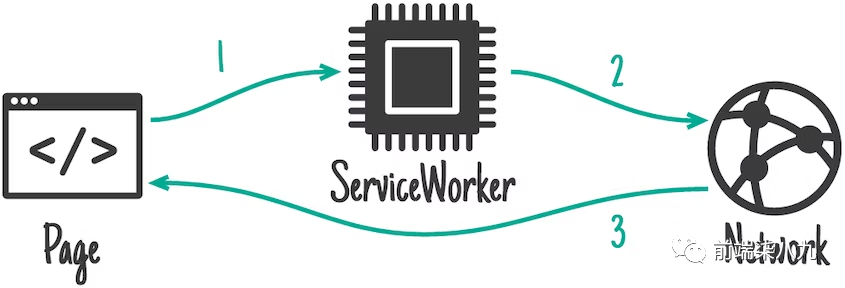
「仅网络」的策略与「仅缓存」相反,它将请求通过service worker传递到网络,而「不与 service worker 缓存进行任何交互」。这是一种「确保内容新鲜度」的好策略,但其权衡是「当用户离线时将无法正常工作」。
要确保请求直接通过到网络,只需「不对匹配的请求调用 event.respondWith」。如果我们想更明确,可以在要传递到网络的请求的fetch事件回调中加入一个空的return;。这就是「仅缓存」策略演示中对于未经预缓存的请求所发生的情况。
3. 缓存优先,备用网络(Cache first, falling back to network)
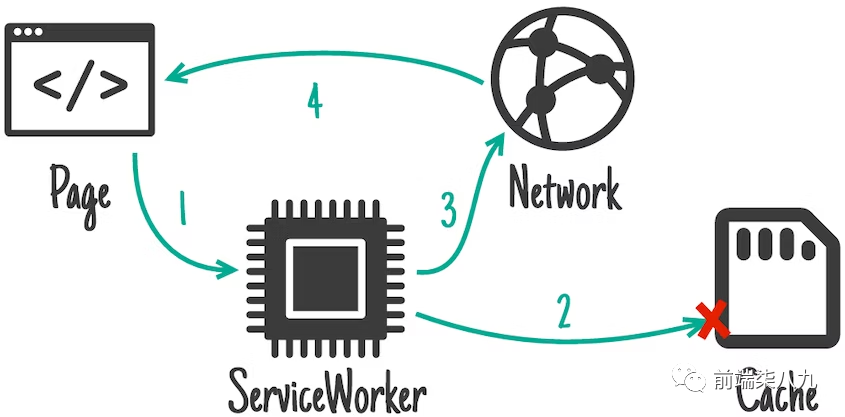
对于「匹配的请求」,流程如下:
- 请求到达缓存。如果资产在缓存中,就从缓存中提供。
- 如果请求不在缓存中,去访问网络。
- 一旦网络请求完成,将其添加到缓存,然后返回网络响应。
// 建立缓存名称
const cacheName = "前端柒八九_v1";self.addEventListener("fetch", (event) => {
// 检查这是否是一个图像请求
if (event.request.destination === "image") {
event.respondWith(
caches.open(cacheName).then((cache) => {
// 首先从缓存中获取
return cache.match(event.request.url).then((cachedResponse) => {
// 如果我们有缓存的响应,则返回缓存的响应
if (cachedResponse) {
return cachedResponse;
}// 否则,访问网络 return fetch(event.request).then((fetchedResponse) => { // 将网络响应添加到缓存以供以后访问 cache.put(event.request, fetchedResponse.clone()); // 返回网络响应 return fetchedResponse; }); }); }) );
} else {
return;
}
});
尽管这个示例只涵盖了图像,但这是一个很好的范例,「适用于所有静态资产」(如CSS、JavaScript、图像和字体),「尤其是哈希版本的资产」。它「通过跳过 HTTP 缓存可能启动的任何与服务器的内容新鲜度检查,为不可变资产提供了速度提升」。更重要的是,「任何缓存的资产都将在离线时可用」。
4. 网络优先,备用缓存(Network first, falling back to cache)

它的含义就是:
- 首先通过网络请求资源,然后将响应放入缓存。
- 如果以后「离线了,就回退到缓存中的最新版本的响应」。
这种策略对于HTML或 API 请求非常有用,当在线时,我们希望获取资源的最新版本,但希望在离线时能够访问最新可用的版本。
// 建立缓存名称
const cacheName = "前端柒八九_v1";self.addEventListener("fetch", (event) => {
// 检查这是否是导航请求
if (event.request.mode === "navigate") {
// 打开缓存
event.respondWith(
caches.open(cacheName).then((cache) => {
// 首先通过网络请求
return fetch(event.request.url)
.then((fetchedResponse) => {
cache.put(event.request, fetchedResponse.clone());return fetchedResponse; }) .catch(() => { // 如果网络不可用,从缓存中获取 return cache.match(event.request.url); }); }) );
} else {
return;
}
});
- 首先,访问页面。可能需要在将
HTML响应放入缓存之前重新加载。 - 然后在开发者工具中,模拟离线连接,然后重新加载。
- 最后一个可用版本将立即从缓存中提供。
在需要重视离线功能,但又需要平衡该功能与获取一些标记或 API 数据的最新版本的情况下,「网络优先,备用缓存」是一种实现这一目标的可靠策略。
5. 陈旧时重新验(Stale-while-revalidate)

「陈旧时重新验证」策略是其中最复杂的。该策略的过程「优先考虑了资源的访问速度」,同时在后台保持其更新。该策略的工作流程如下:
- 对于
首次请求的资源,从网络获取,将其放入缓存,并返回网络响应。 - 对于
后续请求,首先从缓存中提供资源,然后在后台重新从网络请求并更新资源的缓存条目。 - 对于以后的请求,我们将收到从网络获取并在前一步放入缓存的最新版本。
这是一个适用于「需要保持更新但不是绝对必要的资源」的策略,比如网站的头像。它们会在用户愿意更新时进行更新,但不一定需要在每次请求时获取最新版本。
// 建立缓存名称
const cacheName = "前端柒八九_v1";self.addEventListener("fetch", (event) => {
if (event.request.destination === "image") {
event.respondWith(
caches.open(cacheName).then((cache) => {
return cache.match(event.request).then((cachedResponse) => {
const fetchedResponse = fetch(event.request).then(
(networkResponse) => {
cache.put(event.request, networkResponse.clone());return networkResponse; } ); return cachedResponse || fetchedResponse; }); }) );
} else {
return;
}
});
5. Service Worker 预缓存的陷阱
如果将预缓存「应用于太多的资产」,或者如果Service Worker在页面「完成加载关键资产之前」就注册了,那么可能会遇到问题。
当Service Worker在「安装期间预缓存资产时,将同时发起一个或多个网络请求」。如果时机不合适,这可能会对用户体验产生问题。即使时机刚刚好,如果未对预缓存资产的「数量进行限制」,仍可能会浪费数据。
一切都取决于时机
如果Service Worker预缓存任何内容,那么它的注册时机很重要。Service Worker通常使用内联的<script>元素注册。这意味着 HTML 解析器可能在页面的关键资产加载完成之前就发现了Service Worker的注册代码。
这是一个问题。Service Worker在最坏的情况下应该对性能没有不利影响,而不是使性能变差。为用户着想,应该在「页面加载事件」触发时注册Service Worker。这减少了预缓存可能干扰加载页面的关键资产的机会,从而意味着页面可以更快地实现交互,而无需处理后来可能不需要的资产的网络请求。
if ("serviceWorker" in navigator) {
window.addEventListener("load", function () {
navigator.serviceWorker.register("/service-worker.js");
});
}
考虑数据使用
无论时机如何,「预缓存都涉及发送网络请求」。如果不谨慎地选择要预缓存的资产清单,结果可能会浪费一些数据。
「浪费数据是预缓存的一个潜在代价」,但并非每个人都可以访问快速的互联网或无限的数据计划!「在预缓存时,应考虑删除特别大的资产,并依赖于运行时缓存来捕捉它们」,而不是进行假设用户都需要这些资源,从而全部都进行缓存。
6. 改进Service Worker开发体验
虽然Service Worker生命周期确保了可预测的安装和更新过程,但它可能使本地开发与常规开发有些不同。
本地开发的异常情况
通常情况下,Service WorkerAPI 仅在通过 HTTPS 提供的页面上可用,但是我们平时开发中,经常是通过 localhost 提供的页面进行严重。
此时,我们可以通过 chrome://flags/#unsafely-treat-insecure-origin-as-secure,并指定要将不安全的起源视为安全起源。
Service Worker开发辅助工具
迄今为止,测试Service Worker的最有效方法是依赖于无痕窗口,例如 Chrome 中的无痕窗口。每次打开无痕窗口时,我们都是从头开始的。没有活动的Service Worker,也没有打开的缓存实例。这种测试的常规流程如下:
- 打开一个无痕浏览窗口。
- 转到注册了
Service Worker的页面。 - 验证
Service Worker是否按我们的预期工作。 - 关闭无痕窗口。
- 重复。
通过这个过程,我们模拟了Service Worker的生命周期。
Chrome DevTools 应用程序面板中提供的其他测试工具也可以帮助,尽管它们可能在某些方面修改了Service Worker的生命周期。
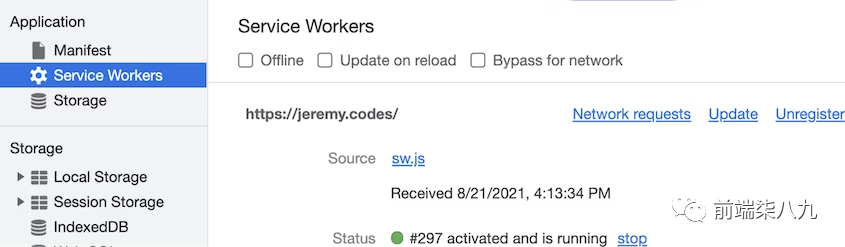
应用程序面板有一个名为Service Workers的面板,显示了当前页面的活动Service Worker。每个活动Service Worker都可以手动更新,甚至完全注销。面板顶部还有三个开关按钮,有助于开发。
Offline(离线):模拟离线条件。这有助于测试当前是否有活动Service Worker提供脱机内容。Update on reload(重新加载时更新):当切换开启时,每次重新加载页面时都会重新获取并替换当前的Service Worker。Bypass for network(绕过网络):切换开启时,会绕过Service Worker的 fetch 事件中的任何代码,并始终从网络获取内容。
这些开关非常有帮助,特别是Bypass for network,当我们正在开发一个具有活动Service Worker的项目时,同时还希望确保体验在没有Service Worker的情况下也能按预期工作。
强制刷新
当在本地开发中使用活动的Service Worker,而不需要更新后刷新或绕过网络功能时,按住 Shift 键并单击刷新按钮也非常有用。
这个操作的键盘变体涉及在 macOS 计算机上按住 Shift、Cmd 和 R 键。
这被称为「强制刷新」,它绕过 HTTP 缓存以获取网络数据。当Service Worker处于活动状态时,强制刷新也将完全绕过Service Worker。
如果不确定特定缓存策略是否按预期工作,或者希望从网络获取所有内容以比较有Service Worker和无Service Worker时的行为,这个功能非常有用。更好的是,这是一个规定的行为,因此所有支持Service Worker的浏览器都会观察到它。
检查缓存内容
如果无法检查缓存,就很难确定缓存策略是否按预期工作。Chrome DevTools 的应用程序面板提供了一个子面板,用于检查缓存实例的内容。
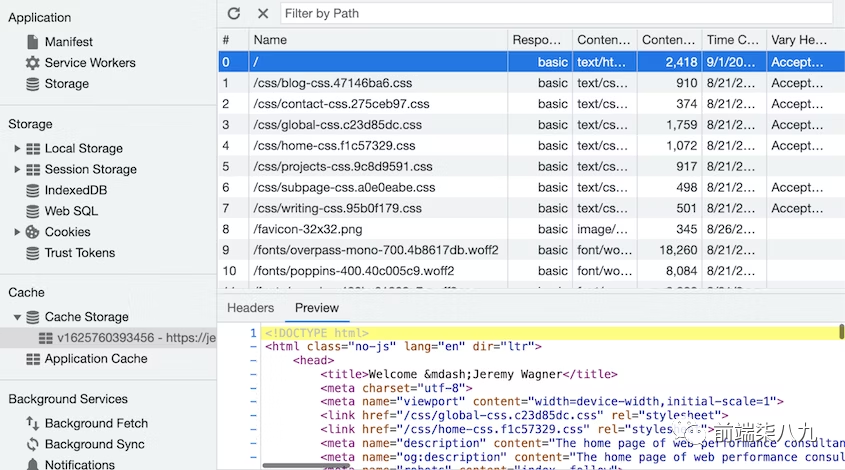
在DevTools中检查缓存
这个子面板通过提供以下功能来使Service Worker开发变得更容易:
- 查看缓存实例的名称。
- 检查缓存资产的响应正文以及它们关联的响应标头。
- 从缓存中清除一个或多个项目,甚至删除整个缓存实例。
这个图形用户界面使检查Service Worker缓存更容易,以查看项目是否已添加、更新或从Service Worker缓存中完全删除。
模拟存储配额
在拥有大量大型静态资产(如高分辨率图像)的网站中,可能会触及存储配额。当这种情况发生时,浏览器将从缓存中驱逐它认为过时或值得牺牲以腾出空间以容纳新资产的项目。
处理存储配额应该是Service Worker开发的一部分,而 Workbox 使这个过程比自行管理更简单。不管是否使用 Workbox,模拟自定义存储配额以测试缓存管理逻辑可能是一个不错的主意。

存储使用查看器
Chrome DevTools 的 Application 面板中的存储使用查看器。在这里,正在设置自定义存储配额。
Chrome DevTools 的 Application 面板有一个存储子面板,提供了有关页面使用的当前存储配额的信息。它还允许指定以兆字节为单位的自定义配额。一旦生效,Chrome 将执行自定义存储配额以进行测试。
这个子面板还包含一个清除站点数据按钮以及一整套相关的复选框,用于在单击按钮时清除哪些内容。其中包括任何打开的缓存实例,以及注销控制页面的任何活动Service Worker的能力。
后记
「分享是一种态度」。
「全文完,既然看到这里了,如果觉得不错,随手点个赞吧。」
Reference
[1]
MDN-Cache: https://developer.mozilla.org/zh-CN/docs/Web/API/Cache