
放一张效果图,这些,三四年前的东西,我其实一直懒得说。

写在前面
“Gene Structure View (Advanced)”这个功能可以说,也是一时兴起写出来的。开发的主要动机,还是发现师弟师妹在做的事情实在是太费时间精力。就这样,四五年过去了。直到现在,我仍然没搞懂,这个功能是怎么被大伙用起来的。我甚至没有花过时间,专门为这个功能写教程。网络上已有的教程,均是用户们自发总结,确实已经讲解得足够清晰明白。多少,我有时看到还是有点感动,毕竟这些事情也可以说是软件开发的一部分。太懒,仍然是我的问题。工作以后,能静下心来写点文字的时间,越来越少。正是假期,我已然预见明天之后便是忙碌的一个月。为此,享受这最后一天。相对系统的总结一份教程,希望能减少一部分用户使用问题,也让一些朋友能够更好的使用工具。
这份教程,将会首先简单介绍界面组成,随后介绍分块功能(原名是 Amazing Optional Gene View,因为确实灵活),最后介绍全局组合。
功能界面介绍
TBtools 这个子工具的功能,比较稳健和丰富。可以先看看界面的主要组成。
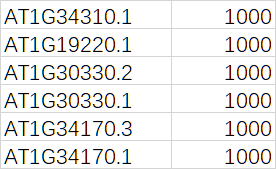
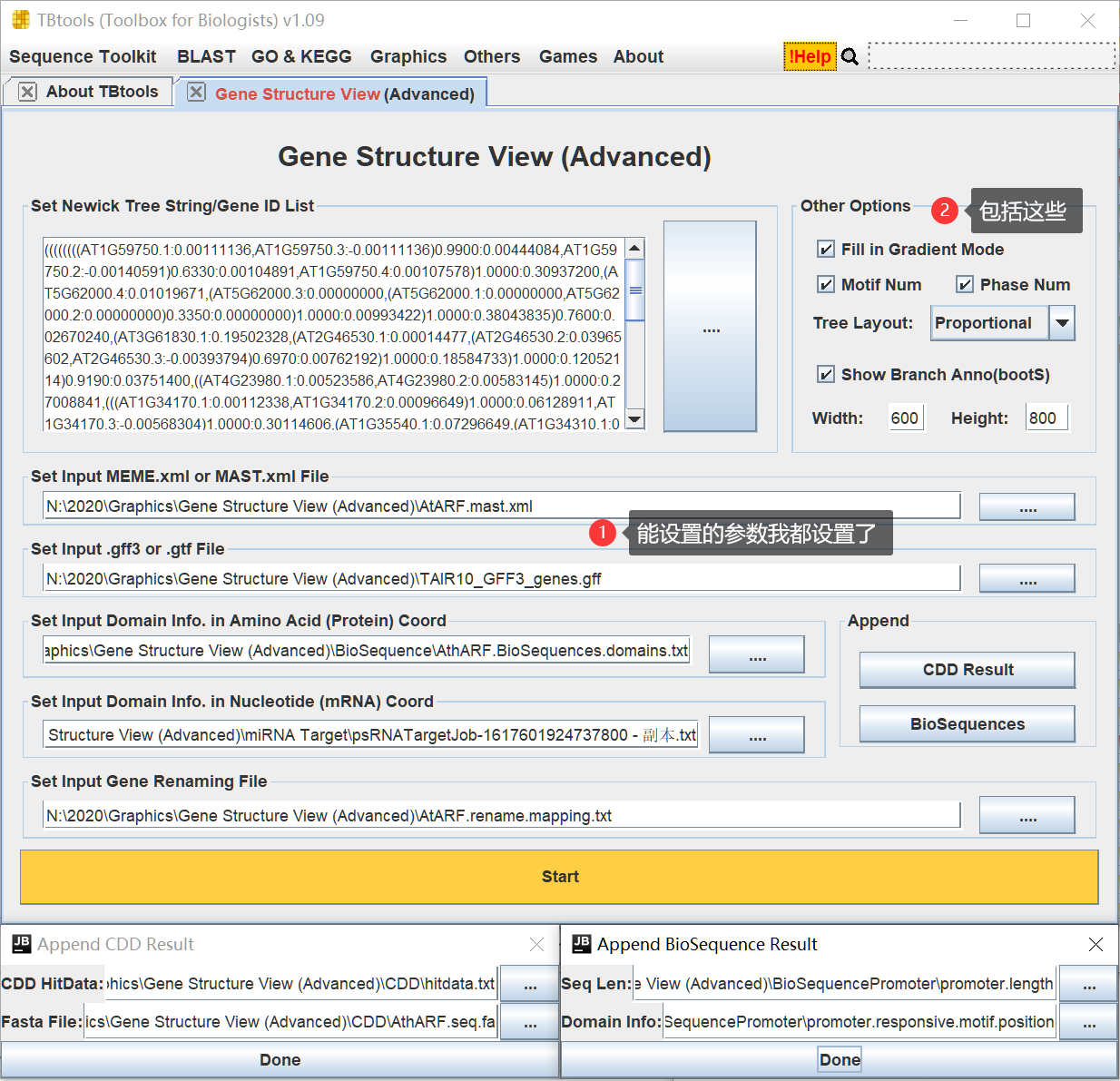
- **待可视化的基因 ID 列表或者进化树**,如果输入的是进化树,那么进化树也是有基因 ID 的,在程序逻辑上,跟 ID 列表区别不大。TBtools 会使用这个基因 ID 列表,自动提取MEME,Domain,尤其是gff3/gtf 文件中的基因结构信息。用于展示。可想而知,这个输入对于 gtf/gff3 文件来说是必须,对于 MEME 等输入非必须。
- **MEME / MAST XML File**,对应的是MEME Suite的两个软件输出。从MEME Suite分析Motifs后,自然会得到这两个XML文件。当然,也可以用 TBtools 打包的 **MEME/MAST GUI Wrapper**,直接在 Windows/MacOS 电脑下本地跑。
- **GFF3/GTF文件 - 基因结构注释信息**,此处是 TBtools 最有趣的地方。用户当然可以提供只包含某些基因的文件,比如某个家族的所有成员的基因结构信息。但对于 TBtools 用户来说,准备这个文件,只是**画蛇添足**。TBtools 直接支持物种基因结构注释信息全集!在软件处理逻辑上,会自动根据“待可视化的基因ID列表或者进化树”在后台提取出对应的基因结构,然后可视化。完全不需要用户自己去整理这些信息,毕竟这是一个繁琐的操作。
- **序列特征/结构域信息- 蛋白坐标**,输入的数据格式在文本提示上已经注明“基因ID\t蛋白起始坐标\t蛋白终止坐标\t结构域名字”,输入数据一般可以直接通过一些结构域预测软件,如NCBI CDD,pfam,SMART等网站预测,简单整理得到。在最终可视化图表上,这些蛋白坐标将会被自动映射到基因组(外显子)坐标上。
- **序列特征/结构域信息- mRNA坐标**,与 4. 中类似,输入的具体坐标为mRNA坐标,即Exon坐标。这类数据一般可以通过直接拿转录本序列(exon组合 - 可用TBtools提取完整转录本),随后用于分析。事实上,NCBI CDD也支持转录本直接预测结构域。对于我个人来说,则是用于分析小RNA靶向位点等。在最终可视化图表上,这些蛋白坐标将会被自动映射到基因组(外显子)坐标上。
- **ID 重命名**信息文件,在最终图稿上,用户可以直接给 ID 映射表格,批量调整 ID 名字,如“ATG123456”调整为“AthARF3”等。
- **一些有趣的参数**:
\* Fill in Gradient Mode,即是否渐变着色,在可视化数据多时,这个参数很有用\* Motif Num:是否显示 Motif 的数字标志\* Phase Num:是否显示剪接位点,即内含子外显子交接点的相位信息\* Tree Layout:进化树的布局模式\* Show Branch Anno:是否展示BootStrap值\* Width:图片宽度\* Height:图片高度- **CDD Result**,为了方便用户做一些可视化,这个摁钮是去年顺手加上去的,因为我发现不少人就是想要直接放CDD的预测结果(而且是单独一栏,不映射到基因结构上)。换句话说,NCBI CDD预测之后,下载 hitdata.txt 文件就可以直接可视化,不需要用户做任何进一步文本整理。
9.**BioSequences**,这个更为灵活,只要用户了解TBtools的生物序列可视化功能,就知道如何准备这个文件。可以拿来可视化结构域信息,如pfam,SMART等,也可以拿来可视化启动子的顺式作用元件预测结果等。
主界面的介绍略显枯燥,也不形象,下面**用非常多的使用实例**来说明这个功能的有趣之处。
可视化 MEME/MAST XML 结果
一般情况下,将蛋白序列提交到 MEME Suite 网站,等待任务结束,即可得到 MEME.xml 或 MAST.xml 文件。不知道操作的朋友自行谷歌百度。这里给出网站的一个截图

有时候网站访问不到,那么可以用 TBtools 的 MEME/MAST GUI Wrapper跑。

所以非常简单.....
如果这个时候,只给部分基因的 ID,那么就只会显示这部分的 motifs 信息。

当然,很少人这么干。
可视化进化树
“Gene Structure View (Advanced)”以前的名字是“Amazing Optional Gene View”,其中最重要的是 Optional,表示这个功能非常灵活。用户可以只单独可视化某一个部分。比如只可视化进化树。

当然,更多时候,大家会希望和 MEME 图一起可视化。

可视化基因结构
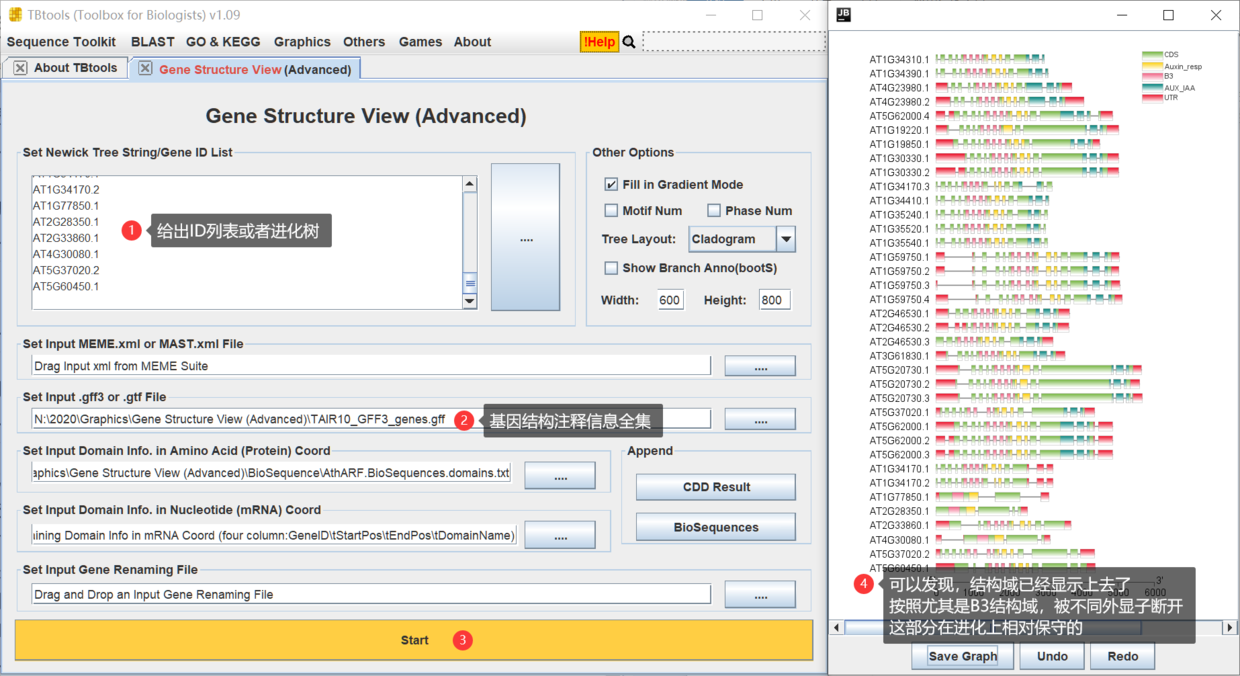
在 TBtools 中可视化基因结构,**用户只需要直接下载物种数据库提供的基因结构注释信息文件,一般是几十Mb的GTF/GFF3文件,而不需要进行任何处理,就可以直接用于基因结构可视化**,相应的, TBtools 需要用户至少给 ID 列表,或者进化树。因为 TBtools 会基于这些IDs信息,自动提取出对应的基因结构,随后可视化。

当然,更多时候,我们希望是按照进化树的顺序来。

可视化结构域信息
很多时候,我还是比较推荐 NCBI CDD 的预测结果,我们提交预测信息上去之后,点击下载,则可以得到 hitdata.txt 文件,响应教程也请自行微信/百度/谷歌检索。以前肯定有人写过的。使用起来方便。

当然,还是那样,可能用户希望的是跟进化树放在一起...

可视化顺式作用元件(启动子)信息
顺式作用元件的预测,目前已经有不少推文可以看到了。微信百度谷歌一检索,肯定还是能看到我以前写的教程。使用Gene Structure View (Advanced)这个功能时,需要大体整理成以下格式。本例取的是 ATG 上游 1kb 的序列,提交到 PlantCARE 预测,随后整理。

同时应该提供每个序列的长度信息,这里都是 1kb。
随后即可用于可视化

当然,还是那样,可能用户希望的还是和进化树放在一起

在基因结构上可视化结构域特征
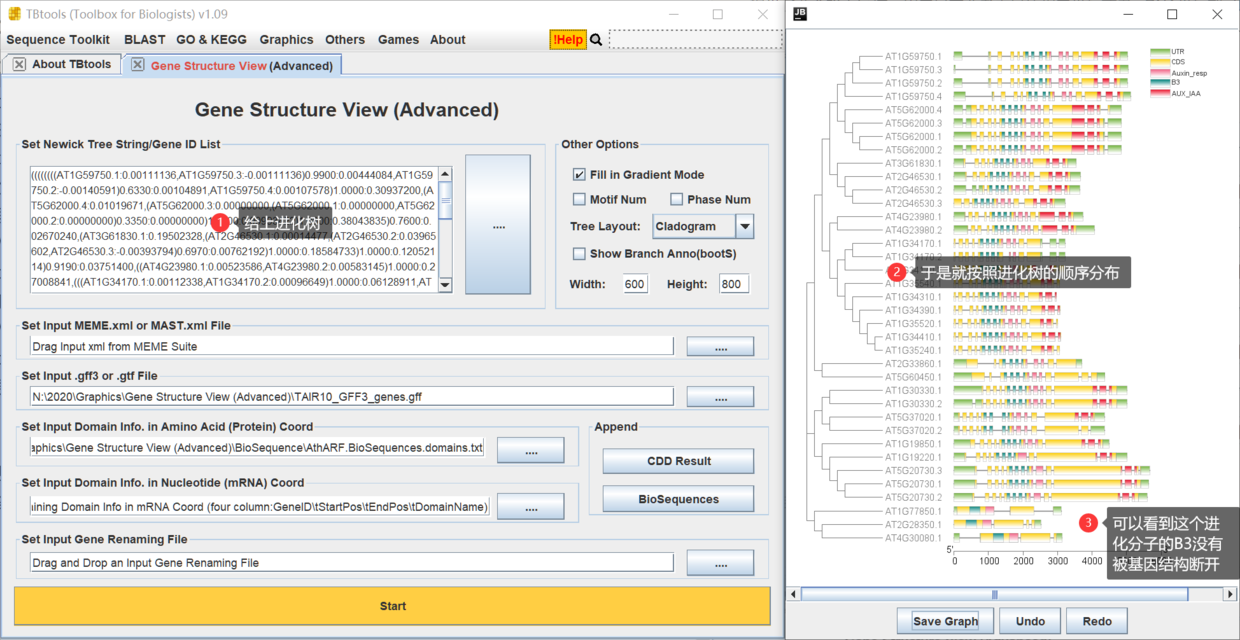
事实上上,上面的都比较直观,我们可以看到“基因结构”和“蛋白结构域”是分开绘制的。但事实上,蛋白结构域,本身对应的也是mRNA序列,回到基因组上,那么就是基因结构上的某一段。所以 TBtools 最初直接提供了两个输入区域,用户只需要考虑具体蛋白坐标或者mRNA坐标就可以可视化序列特征到基因组(基因结构-外显子-内含子)坐标上。此处先看看基因结构域信息。稍微整理了一下之前的 NCBI CDD 预测结果,整理格式大概是,

随后即可用于可视化,
当然,要从成员亲缘关系来分析,还是得给进化树
在基因结构上可视化转录本序列特征信息
蛋白序列特征,如保守结构域信息当然是大家都在关注的。也有一些情况,序列特征体现在转录本序列上,体现在核酸水平,比如小RNA(如miRNA)的靶位点。对于这类信息,只需要简单整理成类似文件,如下

随后即可用于可视化

当然,还是那句话,进化树可以一起展示

当然,在同一进化分支上不同基因上靶位点会保守存在

对进化树进行重命名...
Emmm,TBtools在开发的时候,一直追求的是ID的统一性,但在最后图稿上,一般用户都希望是可以替换成自己喜欢的名字。比如做一个简单的。

其中,重命名信息文件的格式简单,也就是两列,制表符分隔。

(当然,这个例子里面转录本都包含进来了,一般做家族分析,我们是不会包含转录本信息的)
多图组合
如上所示,其中**每一部分都可以分开可视化,也可以随机组合,也可以全部组合!**,这就是所谓的**Amazing Optional....**。这里放出一张图稿。
效果如下(进化树还是用Cla....这个布局好看点),
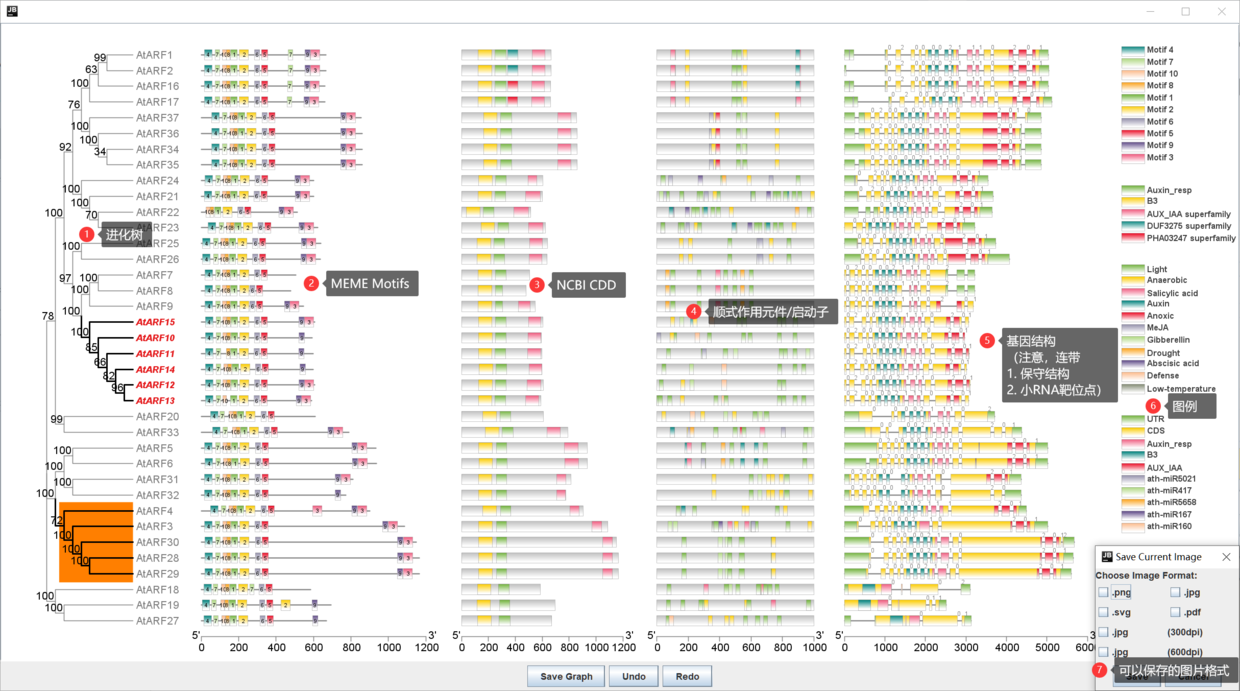
当然,其实还可以利用 JIGplot 特性(毕竟我是开发的嘛)做更多的事情...就不再赘述。
写在最后
没啥好说的。准入门槛越低,越是容易被误解。
**“终于,我们没有改变世界,是世界改变了我们”。**