大家晚上好,今天给大家介绍一个可以处理FASTA文件的包-Biostrings。这个包主要是处理基因组的一些序列信息,包括:序列翻译、DNA/RNA互转、统计各个碱基的含量、三连字母的含量.....这些都是一行命令可以解决的。今天就先来教大家怎样计算GC/AT含量。

首先是安装,代码如下:
代码语言:javascript
复制
source("http://bioconductor.org/biocLite.R")biocLite("Biostrings")输入代码后需要耐心地等待几分钟。

安装完毕,只需敲几行代码,就可以实现GC/AT含量可视化。
代码语言:javascript
复制
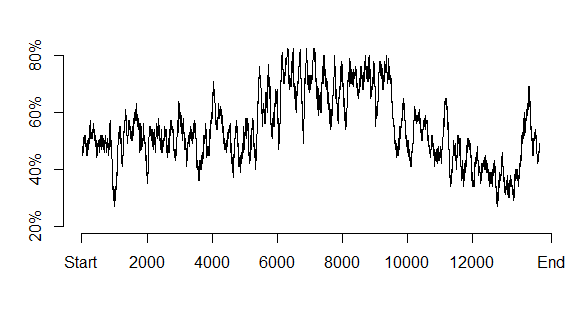
#序列文件储存路径filepath<-"C:/Users/dell/Desktop/sequence.fasta"#读取文件(FASTA格式)x<-readDNAStringSet(filepath)chrom<-x[[1]]#每100个碱基为窗口计算AT含量at<-rowSums(letterFrequencyInSlidingView(chrom,100,c("A","T")))/100#获取描述性统计量根据此设置坐标summary(at)#画图plot(at,type='l',axes=F,xlab=NA,ylab=NA,ylim=c(0.2,0.8))axis(2,at=c(0.2,0.4,0.6,0.8),labels=c("20%","40%","60%","80%"))#纵坐标设置根据summary函数计算结果axis(1,at=c(0,2000,4000,6000,8000,10000,12000,14434),labels=c("Start","2000","4000","6000","8000","10000","12000","End"))#根据基因组显示横坐标信息运行,结果如下:
END
