腾讯云大学知识分享季·DNS专场有奖互动获奖名单公布
腾讯云大学知识分享季DNS专场直播互动获奖名单
▲ 腾小云来给大家开奖啦 ▲
腾讯云大学的各位同学们,4月22日晚举办的知识分享季·DNS专场直播公开课圆满结束,腾讯云大学平台观看直播人数超过千人。在整场直播活动中,我们准备了丰富的奖品,各位同学也积极参与了直播互动,小编直播平台积极参与评论互动的用户进行了汇总,按照几轮有奖互动的评选规则,最终梳理统计出获奖者名单。
现将获奖者名单公布如下,快去获奖名单里找找自己的名字吧!另外,获奖者请点击文末“阅读原文”,填写腾讯云UIN、收货信息等资料,也可以联系腾讯云

腾讯云大学知识分享季·DNS专场有奖互动获奖名单公布
腾讯云大学知识分享季DNS专场直播互动获奖名单
▲ 腾小云来给大家开奖啦 ▲
腾讯云大学的各位同学们,4月22日晚举办的知识分享季·DNS专场直播公开课圆满结束,腾讯云大学平台观看直播人数超过千人。在整场直播活动中,我们准备了丰富的奖品,各位同学也积极参与了直播互动,小编直播平台积极参与评论互动的用户进行了汇总,按照几轮有奖互动的评选规则,最终梳理统计出获奖者名单。
现将获奖者名单公布如下,快去获奖名单里找找自己的名字吧!另外,获奖者请点击文末“阅读原文”,填写腾讯云UIN、收货信息等资料,也可以联系腾讯云

美团大数据面试SQL-计算用户首单是即时单的比例
在外卖订单中,有时用户会指定订单的配送时间。现定义:如果用户下单日期与期望配送日期相同则认为是即时单,如果用户下单日期与期望配送时间不同则是预约单。每个用户下单时间最早的一单为用户首单,请计算用户首单中即时单的占比。

【深度学习】Pytorch教程(九):PyTorch数据结构:3、张量的统计计算详解
Tensor(张量)是PyTorch中用于表示多维数据的主要数据结构,类似于多维数组,可以存储和操作数字数据。

Power BI: 根据最新销售日期计算上一年的销售额
文章背景: DAX权威指南第16章讲的是DAX中的高级计算。最后一个例子提到,为了准确地计算出年同比(YOY),需要忽略上一年中发生在设定日期之后的任何销售数据。

GEE、PIE和AI Earth平台进行案例评测:NDVI计算,结果差异蛮大
本文主要是通过对比GEE、PIE和AI Earth平台,主要是计算不同平台,同一个NDVI的均值计算,我们已测试结果如何。
1341. 十三号星期五(基姆拉尔森计算公式)
请编写一个程序,计算 N 年内每个月的 13 号是星期日,星期一,星期二,星期三,星期四,星期五和星期六的频率。
大数据面试SQL043-计算出完成订单数的众数
众数是描述数据集中趋势的一种方式,它特别适用于分类数据和顺序数据。在实际应用中,众数可以帮助我们了解数据的集中趋势,尤其是在数据分布不均匀时。

用金山文档的python运行复杂统计计算行不行之一?2024.3.20
1、把财务预测移到WPS,可以实现线上增加数据,就可以计算结果,不需要安装python软件、配置环境,可以方便分析,可以出图可视化
计算整数二进制表示中各个1位的数目
举例:给定一个数字是7,假设是8位操作系统,二进制表示为00000111,其中有3个1,则调用函数返回3。
用金山文档的python运行复杂统计计算行不行之二?2024.3.21
1、代码代码语言:javascript复制import pandas as pd
from statsmodels.tsa.statespace.sarimax import SARIMAX
#from prophet import Prophet
#from pmdarima import auto_arima
from statsmodels.tsa.holtwinters import ExponentialSmoothing as ES1
from statsmodels.tsa.api impor...

HiveSQL-面试题031 计算每个用户的受欢迎程度
有好友关系表t_friend_031,记录了user1_id,user2_id的好友关系对。现定义用户受欢迎程度=用户拥有的朋友总数/平台上的用户总数,请计算出每个用户的受欢迎程度。

R语言计算Logistic的efect和OR值以及置信区间
各位小伙伴,大家好,我是邓飞,今天介绍一下,如何使用R语言进行logistic分析,并且计算OR值和置信区间。

indicspecies:计算物种与样本之间关系的强度与生态位宽度
Studying the statistical relationship between species and groups of sites
评估物种发生/丰度与样本之间关系的强度和统计意义,并能够计算生态位宽度。
##indicspecies
install.packages("indicspecies")
library(indicspecies)
strassoc 计算物种与样本之间联系的强度
strassoc(X, cluster, func = "r", group = NULL, nbo
计算一个项目工程中所有包下面的代码行数
有时我们在做项目归档的时候难免会遇到,进行统计代码的行数,这时我们可以用一段代码,直接统计出来。
单细胞转录组可以这样简单计算相关性吗
各种数据挖掘文章本质上都是要把目标基因集缩小,比如表达量矩阵通常是2万多个蛋白编码基因,不管是表达芯片还是RNA-seq测序的,采用何种程度的差异分析,最后都还有成百上千个目标基因。如果是临床队列,通常是会跟生存分析进行交集,或者多个数据集差异结果的交集,比如:多个数据集整合神器-RobustRankAggreg包 ,这样的基因集就是100个以内的数量了,但是仍然有缩小的空间,比如lasso等统计学算法,最后搞成10个左右的基因组成signature即可顺利发表。其实还有另外一个策略方向,有点类似于人工选择啦,通常是可以往热点靠,比如肿瘤免疫,相当于你不需要全部的两万多个基因的表达量矩阵进行后续分析,仅仅是拿着几千个免疫相关基因的表达矩阵即可。最近比较热门的有:自噬基因,铁死亡,EMT基因,核受体基因家族,代谢基因。还有一个最搞笑的是m6a基因的策略,完全是无厘头的基因集搞小,纯粹是为了搞小而搞小。目前单细胞转录组大行其道,所以很多人喜欢使用公共的单细胞转录组数据集来缩小基因范围。学员在微信交流群分享了一个2024年5月的单细胞数据挖掘文章,标题是:《Single-cell combined with transcriptome sequencing to explore the molecular mechanism of cell communication in idiopathic pulmonary fibrosis》,研究者们重新分析了 GSE122960 这个单细胞转录组数据集,主要是第一层次降维聚类分群后,提取了巨噬细胞的特异性基因,然后走了随机森林生存分析算法,得到了 five most related key genes (CD163, IFITM2, IGSF6, S100A14 and SOD3). 有了目标的5个基因就可以很方便的各种简单分析来强调他们的生物学意义。比如去跟PDCD1基因看相关性:

优思学院|六西格玛的方差分析怎么计算?
六西格玛或者统计学中的方差分析(Analysis of Variance, ANOVA)是一种用于分析多个变量之间差异性的统计方法,方差分析的基本思想是将总体方差分解为不同来源的方差,以确定这些来源是否对总方差产生显著的影响。

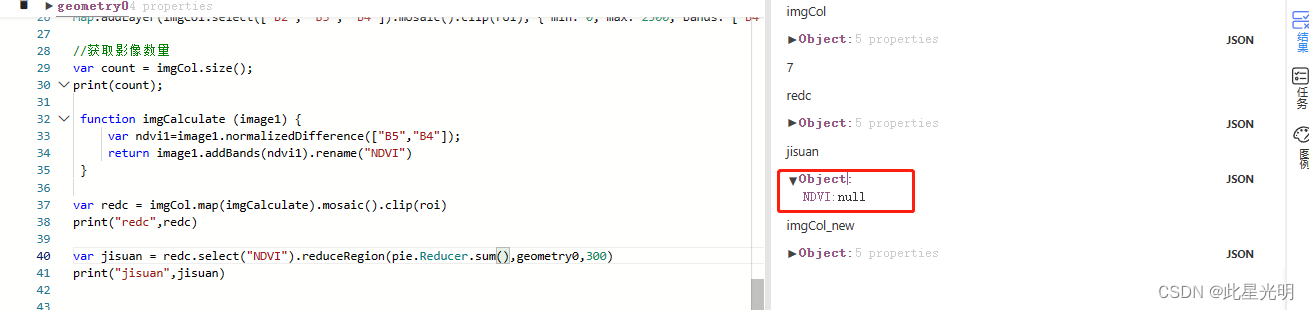
GEE(Google Earth Engine)如何获取影像像素均值和栅格计算?
Generates an image containing a constant value everywhere.

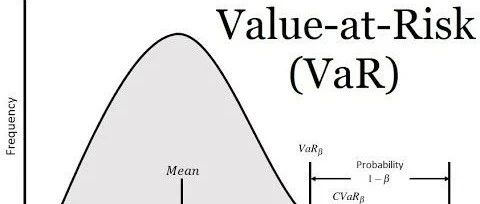
三种常用的风险价值(VaR)计算方法总结
风险价值(VaR)是金融领域广泛使用的风险度量,它量化了在特定时间范围内和给定置信度水平下投资或投资组合的潜在损失。它提供了一个单一的数字,代表投资者在正常市场条件下可能经历的最大损失。VaR是风险管理、投资组合优化和法规遵从的重要工具。
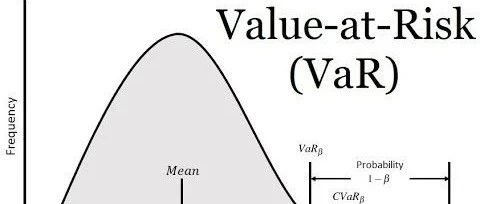
三种常用的风险价值(VaR)计算方法总结
风险价值(VaR)是金融领域广泛使用的风险度量,它量化了在特定时间范围内和给定置信度水平下投资或投资组合的潜在损失。它提供了一个单一的数字,代表投资者在正常市场条件下可能经历的最大损失。VaR是风险管理、投资组合优化和法规遵从的重要工具。