揭秘YouTube视频世界:利用Python和Beautiful Soup的独特技术
YouTube作为全球最大的视频分享平台,每天有数以亿计的视频被上传和观看。对于数据分析师、市场营销人员和内容创作者来说,能够获取YouTube视频的相关数据(如标题、观看次数、喜欢和不喜欢的数量等)是非常有价值的。本文将介绍如何使用Python编程语言和Beautiful Soup库来抓取YouTube视频的数据。

Python 系列文章 —— BeautifulSoup 详解
BeautifulSoup.py
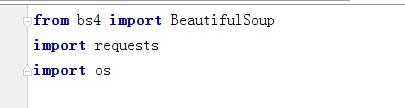
from bs4 import BeautifulSoup
# demo 1
# soup = BeautifulSoup(open("index.html"))
soup = BeautifulSoup("<html><head><title>index</title></head><body>content</body></html>", "lxml")
print(soup.head)
html_doc = """
<html><head><title>inde
Python 系列文章 —— BeautifulSoup 实战
BeautifulSoup 实战
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>index</title></head>
<body>
<p class="title"><b>首页</b></p>
<p class="main">我常用的网站
<a href="https://www.google.com" class="website" id="google">Google</a>
<a href="https://www
Python实现简易采集爬虫
对于爬取网页上的数据,采集爬虫是一个非常常见的方法。在Python中,我们可以通过一些库(如Requests、BeautifulSoup、Scrapy等)轻松实现一个简易的采集爬虫。本文将从多个方面详细阐述Python实现简易采集爬虫的方法。

利用爬虫技术自动化采集汽车之家的车型参数数据
汽车之家是一个专业的汽车网站,提供了丰富的汽车信息,包括车型参数、图片、视频、评测、报价等。如果我们想要获取这些信息,我们可以通过浏览器手动访问网站,或者利用爬虫技术自动化采集数据。本文将介绍如何使用Python编写一个简单的爬虫程序,实现对汽车之家的车型参数数据的自动化采集,并使用亿牛云爬虫代理服务来提高爬虫的稳定性和效率。

如何优化 Selenium 和 BeautifulSoup 的集成以提高数据抓取的效率?
摘要
在互联网时代,数据的价值日益凸显。对于电商网站如京东,其商品信息、用户评价等数据对于市场分析、产品定位等具有重要意义。然而,由于这些网站通常使用 JavaScript 动态生成内容,传统的爬虫技术难以直接获取到完整数据。本文将以爬取京东商品信息为例,探讨如何优化 Selenium 和 BeautifulSoup 的集成,以提高数据抓取的效率。
Python基础项目实战:爬取每一个歌单中的歌曲列表
今天为大家介绍一个爬取网易云音乐每一个歌单中的歌曲汇总,你想听的歌它都有,利用简单的爬虫库BeautifulSoup来进行获取网站的信息,下面一起来看看吧
技术无罪or技术原罪?爬图小心查水表
该网站是论坛结构,没有登录,反爬也基本没有,爬下来的东西也很实用,入门就从他开始吧(没有网址)

高级网页爬虫开发:Scrapy和BeautifulSoup的深度整合
引言
在互联网时代,数据的价值日益凸显。网页爬虫作为一种自动化获取网页内容的工具,广泛应用于数据挖掘、市场分析、内容聚合等领域。Scrapy是一个强大的网页爬虫框架,而BeautifulSoup则是一个灵活的HTML和XML文档解析库。本文将探讨如何将这两个工具深度整合,开发出高级的网页爬虫。
如何获取美团的热门商品和服务
美团是中国最大的生活服务平台之一,提供了各种各样的商品和服务,如美食、酒店、旅游、电影、娱乐等。如果你想了解美团的热门商品和服务,你可以使用爬虫技术来获取它们。本文将介绍如何使用Python和BeautifulSoup库来编写一个简单的爬虫程序,以及如何使用爬虫代理来提高爬虫的效率和稳定性。

使用Python和BeautifulSoup轻松抓取表格数据
你是否曾经希望可以轻松地从网页上获取表格数据,而不是手动复制粘贴?好消息来了,使用Python和BeautifulSoup,你可以轻松实现这一目标。今天,我们将探索如何使用这些工具抓取中国气象局网站(http://weather.cma.cn)上的天气数据,分析各地的天气情况。让我们开始这段有趣的旅程吧!

Web数据提取:Python中BeautifulSoup与htmltab的结合使用
Web数据提取,通常被称为Web Scraping或Web Crawling,是指从网页中自动提取信息的过程。这项技术在市场研究、数据分析、信息聚合等多个领域都有广泛的应用。Python社区提供了丰富的工具和库来支持这一技术,其中BeautifulSoup和htmltab是两个非常有用的库。

Web数据提取:Python中BeautifulSoup与htmltab的结合使用
Web数据提取,通常被称为Web Scraping或Web Crawling,是指从网页中自动提取信息的过程。这项技术在市场研究、数据分析、信息聚合等多个领域都有广泛的应用。Python社区提供了丰富的工具和库来支持这一技术,其中BeautifulSoup和htmltab是两个非常有用的库。
python爬虫中 HTTP 到 HTTPS 的自动转换
在当今互联网世界中,随着网络安全的重要性日益增加,越来越多的网站采用了 HTTPS 协议来保护用户数据的安全。然而,许多网站仍然支持 HTTP 协议,这就给我们的网络爬虫项目带来了一些挑战。为了应对这种情况,我们需要一种方法来自动将 HTTP 请求转换为 HTTPS 请求,以确保我们的爬虫项目在处理这些网站时能够正常工作。本文将介绍如何在 BeautifulSoup 项目中实现这一自动转换的功能。
使用BeautifulSoup解析豆瓣网站的HTML内容并查找图片链接
爬取豆瓣网图片的用途广泛。首先,对于雕塑和学者来说,爬取豆瓣图片可以用于文化研究、社会分析等领域。通过分析用户上传的图片,可以了解不同文化背景下的审美趋势和文化偏好,为相关研究提供数据支持。
利用爬虫技术自动化采集汽车之家的车型参数数据
汽车之家是一个专业的汽车网站,提供了丰富的汽车信息,包括车型参数、图片、视频、评测、报价等。如果我们想要获取这些信息,我们可以通过浏览器手动访问网站,或者利用爬虫技术自动化采集数据。本文将介绍如何使用Python编写一个简单的爬虫程序,实现对汽车之家的车型参数数据的自动化采集,并使用亿牛云爬虫代理服务来提高爬虫的稳定性和效率。

如何获取美团的热门商品和服务
美团是中国最大的生活服务平台之一,提供了各种各样的商品和服务,如美食、酒店、旅游、电影、娱乐等。如果你想了解美团的热门商品和服务,你可以使用爬虫技术来获取它们。本文将介绍如何使用Python和BeautifulSoup库来编写一个简单的爬虫程序,以及如何使用爬虫代理来提高爬虫的效率和稳定性。

使用Python和BeautifulSoup轻松抓取表格数据
你是否曾经希望可以轻松地从网页上获取表格数据,而不是手动复制粘贴?好消息来了,使用Python和BeautifulSoup,你可以轻松实现这一目标。今天,我们将探索如何使用这些工具抓取中国气象局网站(http://weather.cma.cn)上的天气数据,分析各地的天气情况。让我们开始这段有趣的旅程吧!

揭秘YouTube视频世界:利用Python和Beautiful Soup的独特技术
YouTube作为全球最大的视频分享平台,每天有数以亿计的视频被上传和观看。对于数据分析师、市场营销人员和内容创作者来说,能够获取YouTube视频的相关数据(如标题、观看次数、喜欢和不喜欢的数量等)是非常有价值的。本文将介绍如何使用Python编程语言和Beautiful Soup库来抓取YouTube视频的数据。

python爬虫中 HTTP 到 HTTPS 的自动转换
在当今互联网世界中,随着网络安全的重要性日益增加,越来越多的网站采用了 HTTPS 协议来保护用户数据的安全。然而,许多网站仍然支持 HTTP 协议,这就给我们的网络爬虫项目带来了一些挑战。为了应对这种情况,我们需要一种方法来自动将 HTTP 请求转换为 HTTPS 请求,以确保我们的爬虫项目在处理这些网站时能够正常工作。本文将介绍如何在 BeautifulSoup 项目中实现这一自动转换的功能。