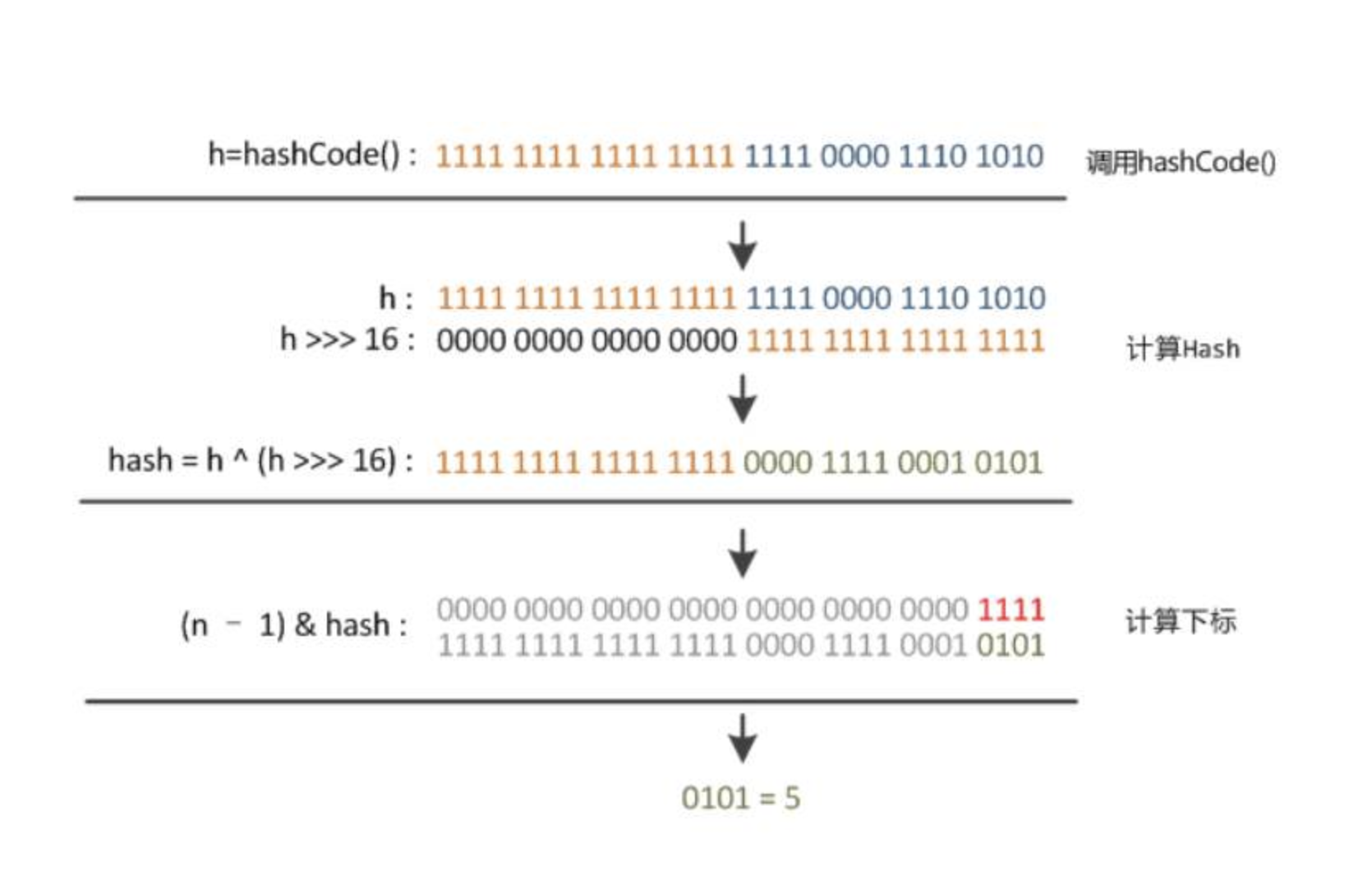
为什么 HashMap 要用 h^(h >>>16) 计算hash值?槽位数必须是 2^n?
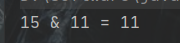
昨天中午,一位粉丝朋友在微信私信我,问:为啥HashMap的hash值计算格式是这样:(h = key.hashCode()) ^ (h >>> 16)?h ^ ^ (h >>> 16)是什么意思?
为什么 HashMap 要用 h^(h >>>16) 计算hash值?槽位数必须是 2^n?
昨天中午,一位粉丝朋友在微信私信我,问:为啥HashMap的hash值计算格式是这样:(h = key.hashCode()) ^ (h >>> 16)?h ^ ^ (h >>> 16)是什么意思?
调用 indexFor(int h, int length) 方法来计算 table 数组的哪个索引处
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用 hash(int h) 方法所计算得到的 hash 码值总是相同的。我们首先想到的就是把hash值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,“模”运算的消耗还是比较大的,在HashMap中是这样做的:调用 indexFor(int h, int length) 方法来计算该对象应该保存在 table 数组的哪个索引处。indexFor(int h, int length) 方法的代码如下:
【从Java面试题看源码】-HashMap 初始容量 计算方法
如果在new HashMap的时候,没有指定初始initialCapacity,则初始initialCapacity为16,负载因子为0.75,下次扩容阈值为 16*0.75=12
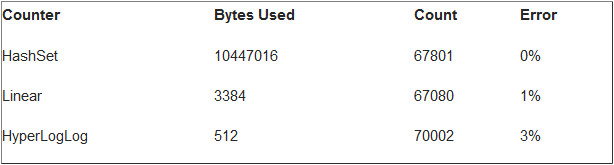
大数据计算:如何仅用1.5KB内存为十亿对象计数
Big Data Counting: How To Count A Billion Distinct Objects Using Only 1.5K
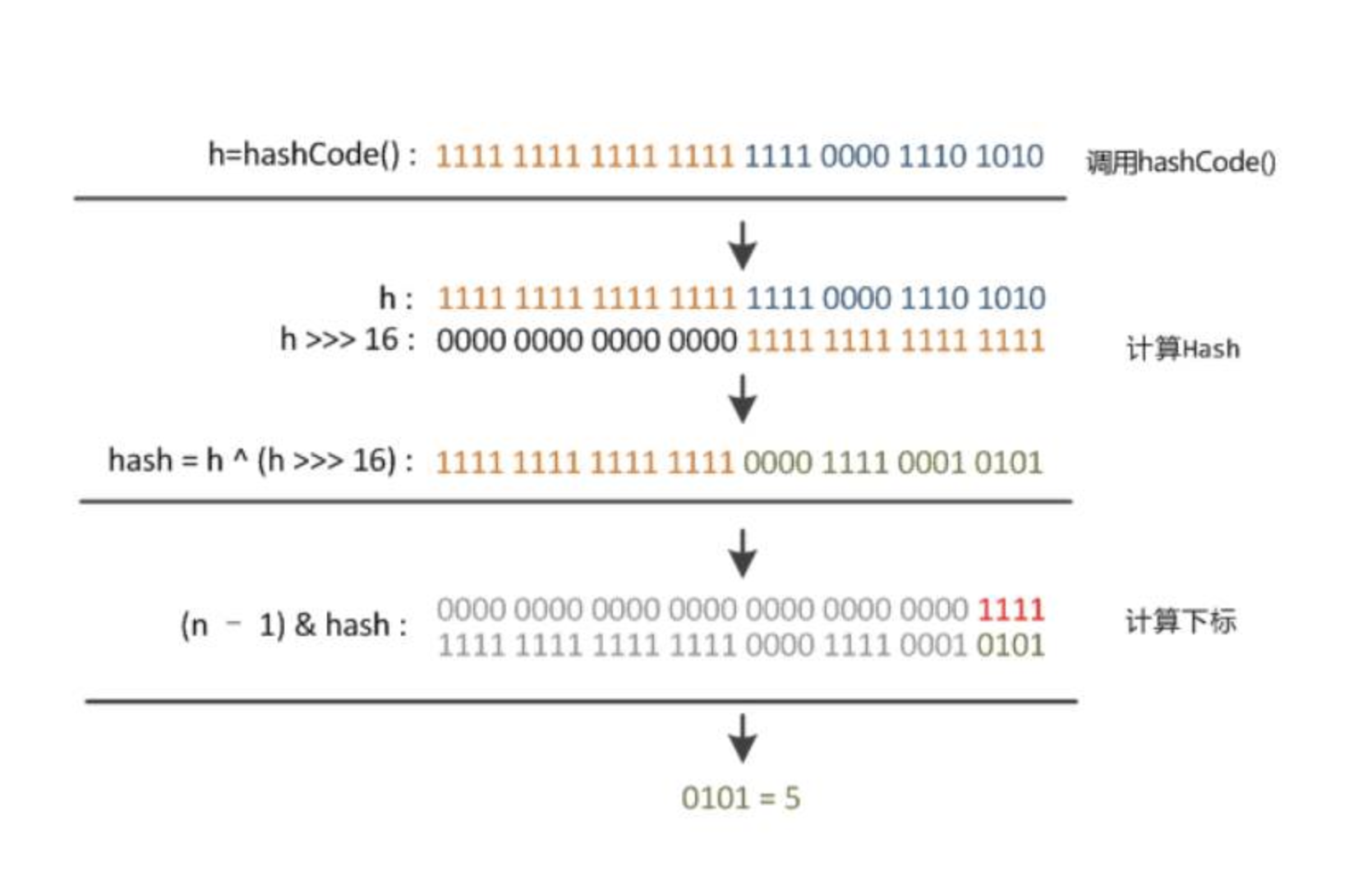
ddEntry(hash, key, value, i)方法根据计算出的hash值
ddEntry(hash, key, value, i)方法根据计算出的hash值,将key-value对放在数组table的i索引处。addEntry 是 HashMap 提供的一个包访问权限的方法(就是没有public,protected,private这三个访问权限修饰词修饰,为默认的访问权限,用default表示,但在代码中没有这个default),代码如下:
ddEntry(hash, key, value, i)方法根据计算出的hash值
ddEntry(hash, key, value, i)方法根据计算出的hash值,将key-value对放在数组table的i索引处。addEntry 是 HashMap 提供的一个包访问权限的方法(就是没有public,protected,private这三个访问权限修饰词修饰,为默认的访问权限,用default表示,但在代码中没有这个default),代码如下:
秋招面经三(作业帮、新浪、阿里云)
位码即tcp标志位,有6种标示:SYN(synchronous建立联机) 、ACK(acknowledgement 确认) 、PSH(push传送)、 FIN(finish结束) 、RST(reset重置) 、URG(urgent紧急)、Sequence number(顺序号码) 、Acknowledge number(确认号码)。
网易云音乐Java面经(共三面)
【每日一语】很多人都无从得知自己的天赋,因为找不到相信他们的老师。于是他们深信自己很笨。——《心灵捕手》
海量数据相似度计算之simhash和海明距离
通过 采集系统 我们采集了大量文本数据,但是文本中有很多重复数据影响我们对于结果的分析。分析前我们需要对这些数据去除重复,如何选择和设计文本的去重算法?常见的有余弦夹角算法、欧式距离、Jaccard相似度、最长公共子串、编辑距离等。这些算法对于待比较的文本数据不多时还比较好用,如果我们的爬虫每天采集的数据以千万计算,我们如何对于这些海量千万级的数据进行高效的合并去重。最简单的做法是拿着待比较的文本和数据库中所有的文本比较一遍如果是重复的数据就标示为重复。看起来很简单,我们来做个测试,就拿最简单的两个数据使用Apache提供的 Levenshtein for 循环100w次计算这两个数据的相似度。代码结果如下:
[Java 8 HashMap 详解系列] 2.HashMap 中 Key 的 index 是怎样计算的?
对于HashMap内的所有实现来说,首先第一步是定位对键值对所在数组的索引下标位置,这是后续所有操作的基础.
[Java 8 HashMap 详解系列] 2.HashMap 中 Key 的 index 是怎样计算的?
对于HashMap内的所有实现来说,首先第一步是定位对键值对所在数组的索引下标位置,这是后续所有操作的基础.
(40) 剖析HashMap / 计算机程序的思维逻辑
查看历史文章,请点击上方链接关注公众号。
前面两节介绍了ArrayList和LinkedList,它们的一个共同特点是,查找元素的效率都比较低,都需要逐个进行比较,本节介绍HashMap,它的查找效率则要高的多,HashMap是什么?怎么用?是如何实现的?本节详细介绍。
字面上看,HashMap由两个单词组成,Hash和Map,这里Map不是地图的意思,而是表示映射关系,是一个接口,实现Map接口有多种方式,HashMap实现的方式利用了Hash。
下面,我们先来看Map接口,接着看如何使用HashMap,
高性能 Java 计算服务的性能调优实战
随着业务的日渐复杂,性能优化俨然成为了每一位技术人的必修课。性能优化从何着手?如何从问题表象定位到性能瓶颈?如何验证优化措施是否有效?本文将介绍分享 vivo push 推荐项目中的性能调优实践,希望给大家提供一些借鉴和参考。
HashMap底层实现原理_计算机底层原理
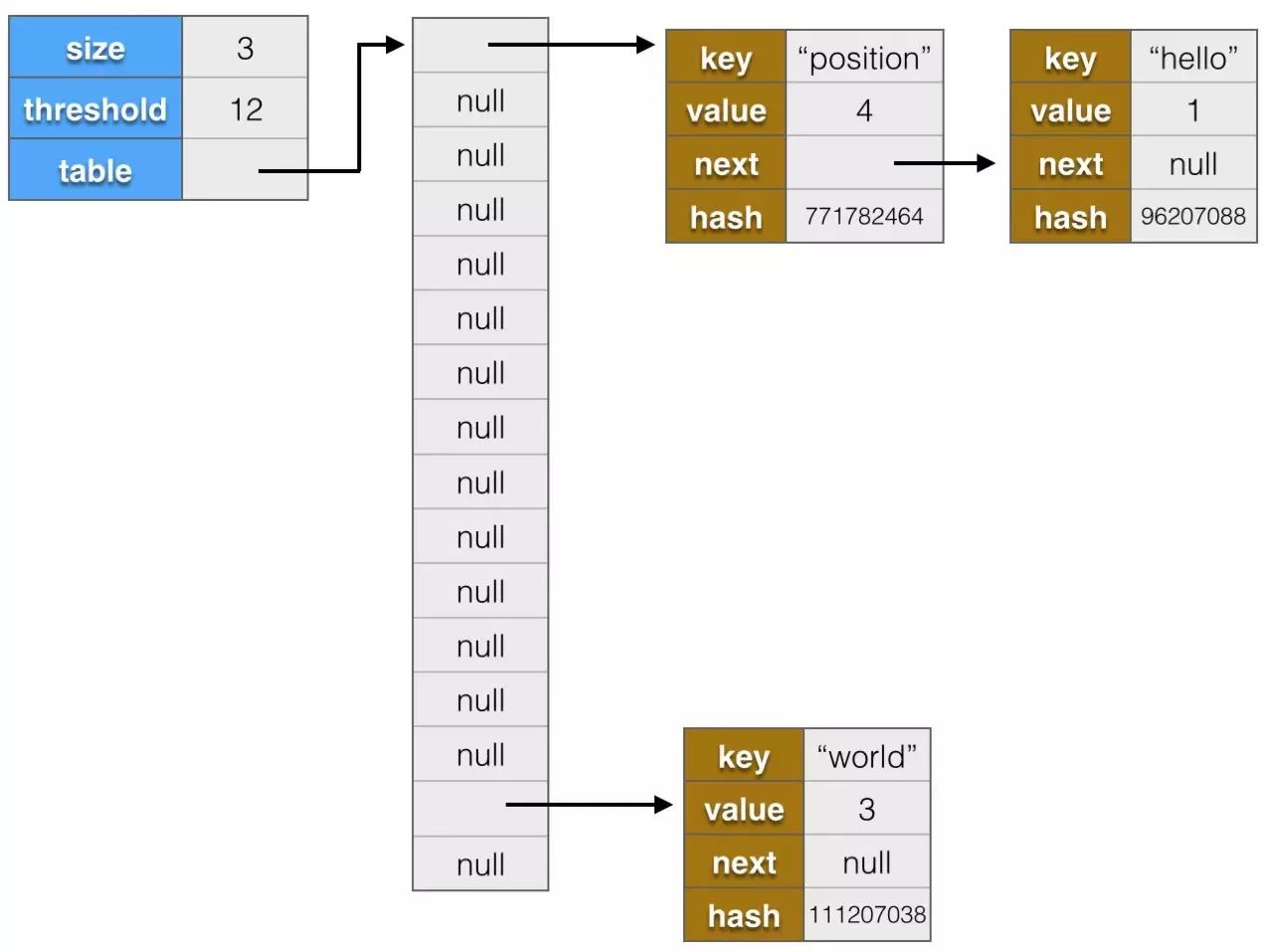
HashMap是Java程序员使用频率最高的用于映射键值对(key和value)处理的数据类型。随着JDK版本的跟新,JDK1.8对HashMap底层的实现进行了优化,列入引入红黑树的数据结构和扩容的优化等。本文结合JDK1.7和JDK1.8的区别,深入探讨HashMap的数据结构实现和功能原理。
Java为数据结构中的映射定义了一个接口java.uti.Map,此接口主要有四个常用的实现类,分别是HashMap,LinkedHashMap,Hashtable,TreeMap,IdentityHashMap。本篇文章主要讲解HashMap以及底层实现原理。
根据 key 计算出对应的 hash 值
注意:这里的加锁操作是针对某个具体的 Segment,锁定的是该 Segment 而不是整个 ConcurrentHashMap。因为插入键 / 值对操作只是在这个 Segment 包含的某个桶中完成,不需要锁定整个ConcurrentHashMap。此时,其他写线程对另外 15 个Segment 的加锁并不会因为当前线程对这个 Segment 的加锁而阻塞。同时,所有读线程几乎不会因本线程的加锁而阻塞(除非读线程刚好读到这个 Segment 中某个 HashEntry 的 value 域的值为 null,此时需要加锁后重新读取该值)。
相比较于 HashTable 和由同步包装器包装的 HashMap每次只能有一个线程执行读或写操作,ConcurrentHashMap 在并发访问性能上有了质的提高。在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设置为 16),及任意数量线程的读操作。
根据 key 计算出对应的 hash 值
注意:这里的加锁操作是针对某个具体的 Segment,锁定的是该 Segment 而不是整个 ConcurrentHashMap。因为插入键 / 值对操作只是在这个 Segment 包含的某个桶中完成,不需要锁定整个ConcurrentHashMap。此时,其他写线程对另外 15 个Segment 的加锁并不会因为当前线程对这个 Segment 的加锁而阻塞。同时,所有读线程几乎不会因本线程的加锁而阻塞(除非读线程刚好读到这个 Segment 中某个 HashEntry 的 value 域的值为 null,此时需要加锁后重新读取该值)。
相比较于 HashTable 和由同步包装器包装的 HashMap每次只能有一个线程执行读或写操作,ConcurrentHashMap 在并发访问性能上有了质的提高。在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设置为 16),及任意数量线程的读操作。
2021-2-17:Java HashMap 的中 key 的哈希值是如何计算的,为何这么计算?
首先,我们知道 HashMap 的底层实现是开放地址法 + 链地址法的方式来实现。
计算机程序设计哲学
计算机程序设计哲学
计算机抽象模型
图灵机(Turing machine)
一台图灵机是一个七元组,M = {Q,Σ,Γ,δ,q0,qaccept,qreject},其中 Q,Σ,Γ 都是有限集合,且满足:
1、Q 是状态集合;
2、Σ 是输入字母表,其中不包含特殊的空白符;
3、Γ 是带字母表,其中 □∈Γ且Σ∈Γ ;
4、 δ:Q ×「 → Q × Γ × {L,R} 是转移函数,其中L,R 表示读写头是向左移还是向右移;
5、q0∈Q是起始状态;
6、qaccept是接受状态。
7
HashMap 计算 Hash 值的扰动函数
理论上 hash 散列是一个 int 值,如果直接拿出来作为下标访问 hashmap 的话,考虑到二进制 32 位,取值范围在-2147483648 ~ 2147483647。大概有 40 亿个 key , 只要哈希函数映射比较均匀松散,一般很难出现碰撞。
