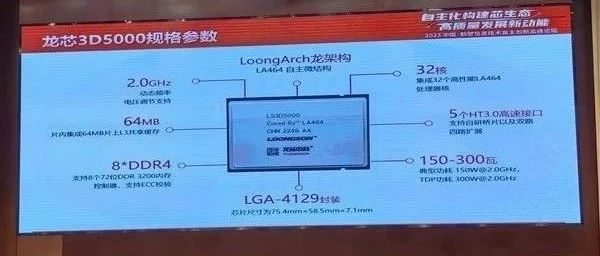
龙芯3D5000高性能CPU发布:LoongArch指令集,Chiplet技术,32核,支持4路扩展!
4月8日上午,在鹤壁举行的信息技术自主创新高峰论坛上,龙芯中科正式发布了龙芯3D5000处理器,这是龙芯5000家族的最新成员,首次使用芯粒(chiplet)技术将2个龙芯3C5000封装在一起,做到了32核。
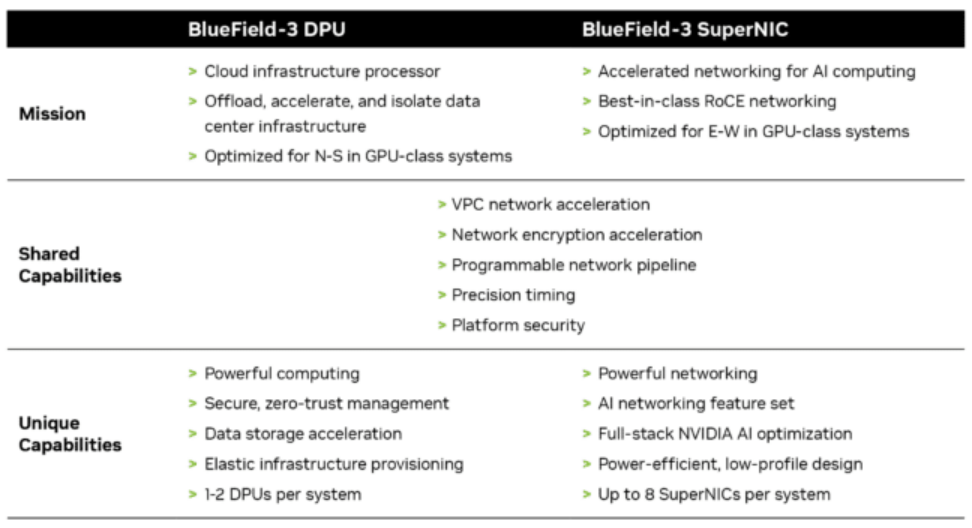
什么是超级网卡(SuperNIC)?
SuperNIC 是一种用于 AI 云数据中心的网络加速器,可在 GPU 服务器之间提供强大且无缝的连接
Kong:高性能、插件化的云原生 API 网关 | 开源日报 No.62
Kong 是一款云原生、平台无关且可扩展的 API 网关。它以高性能和插件化的方式脱颖而出,提供了代理、路由、负载均衡、健康检查和认证等功能,并成为编排微服务或传统 API 流量的中心层。

Kong:高性能、插件化的云原生 API 网关 | 开源日报 No.62
Kong 是一款云原生、平台无关且可扩展的 API 网关。它以高性能和插件化的方式脱颖而出,提供了代理、路由、负载均衡、健康检查和认证等功能,并成为编排微服务或传统 API 流量的中心层。

云原生 | 使用 CoreDNS 构建高性能、插件化的DNS服务器
在企业高可用DNS架构部署方案中我们使用的是传统老牌DNS软件Bind, 但是现在不少企业内部流行容器化部署,所以也可以将 Bind 替换为 CoreDNS ,由于 CoreDNS 是 Kubernetes 的一个重要组件,稳定性不必担心,于此同时还可将K8S集群SVC解析加入到企业内部的私有的CoreDNS中。

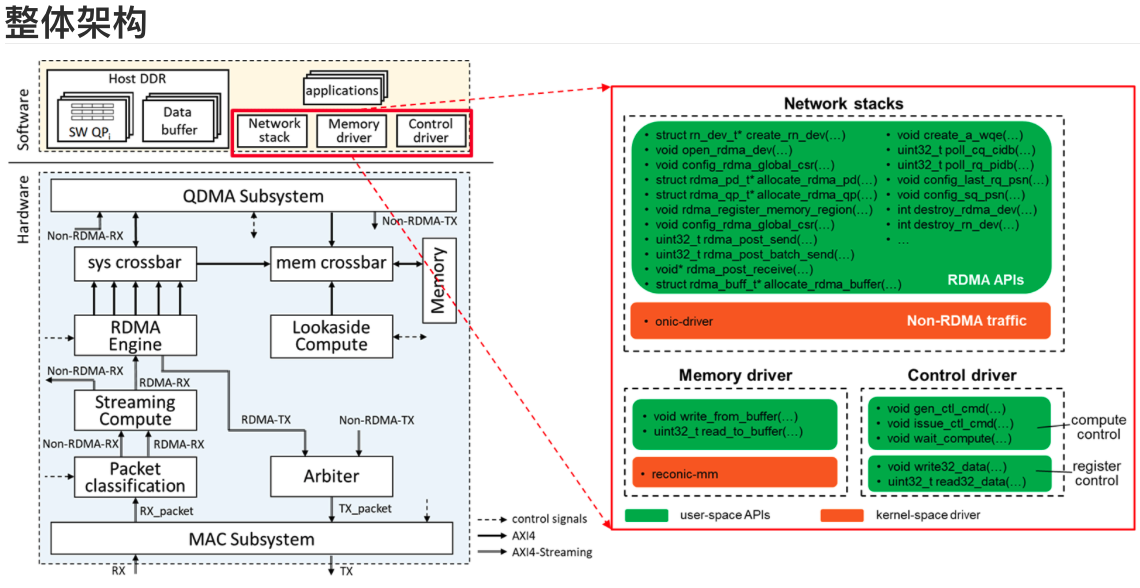
RecoNIC 入门:SmartNIC 上支持 RDMA 的计算卸载-FPGA-智能网卡-AMD-Xilinx
当今的数据中心由数千台网络连接的主机组成,每台主机都配有 CPU 和 GPU 和 FPGA 等加速器。 这些主机还包含以 100Gb/s 或更高速度运行的网络接口卡 (NIC),用于相互通信。 我们提出了 RecoNIC,这是一种基于 FPGA、支持 RDMA 的 SmartNIC 平台,旨在通过使网络数据尽可能接近计算来加速计算,同时最大限度地减少与数据副本(在以 CPU 为中心的加速器系统中)相关的开销。 由于 RDMA 是用于改善数据中心工作负载通信的事实上的传输层协议,因此 RecoNIC 包含一个用于高吞吐量和低延迟数据传输的 RDMA 卸载引擎。 开发人员可以在 RecoNIC 的可编程计算模块中灵活地使用 RTL、HLS 或 Vitis Networking P4 来设计加速器。 这些计算块可以通过 RDMA 卸载引擎访问主机内存以及远程对等点中的内存。 此外,RDMA 卸载引擎由主机和计算块共享,这使得 RecoNIC 成为一个非常灵活的平台。 最后,我们为研究社区开源了 RecoNIC,以便能够对基于 RDMA 的应用程序和用例进行实验
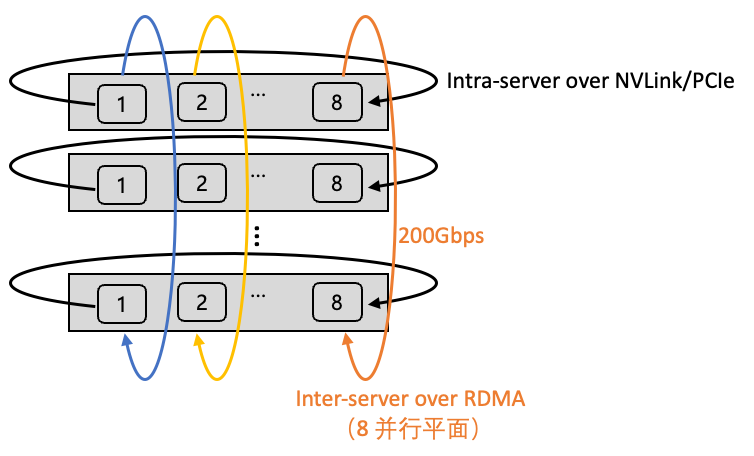
腾讯星脉高性能计算网络:为AI大模型构筑网络底座
阿里灵骏智算产品有磐久可预期网络(参考:阿里整网络顶呱呱,整图苦哈哈!),腾讯也没闲着,星脉高性能计算网络为AI大模型构筑网络底座。

使用 NVIDIA DOCA 2.5 提供高效、高性能的 AI 云
NVIDIA DOCA 2.5的发布标志着其三周年, 探索彻底改变人工智能基础设施的最新网络产品

一款云原生时代的高性能 Java 框架
Quarkus 是一个为 Java 虚拟机(OpenJDK HotSpot)和原生编译而设计的全堆栈 Kubernetes 原生 Java 框架,用于专门针对容器优化 Java,并使其成为无服务器、云和 Kubernetes 环境的高效平台。
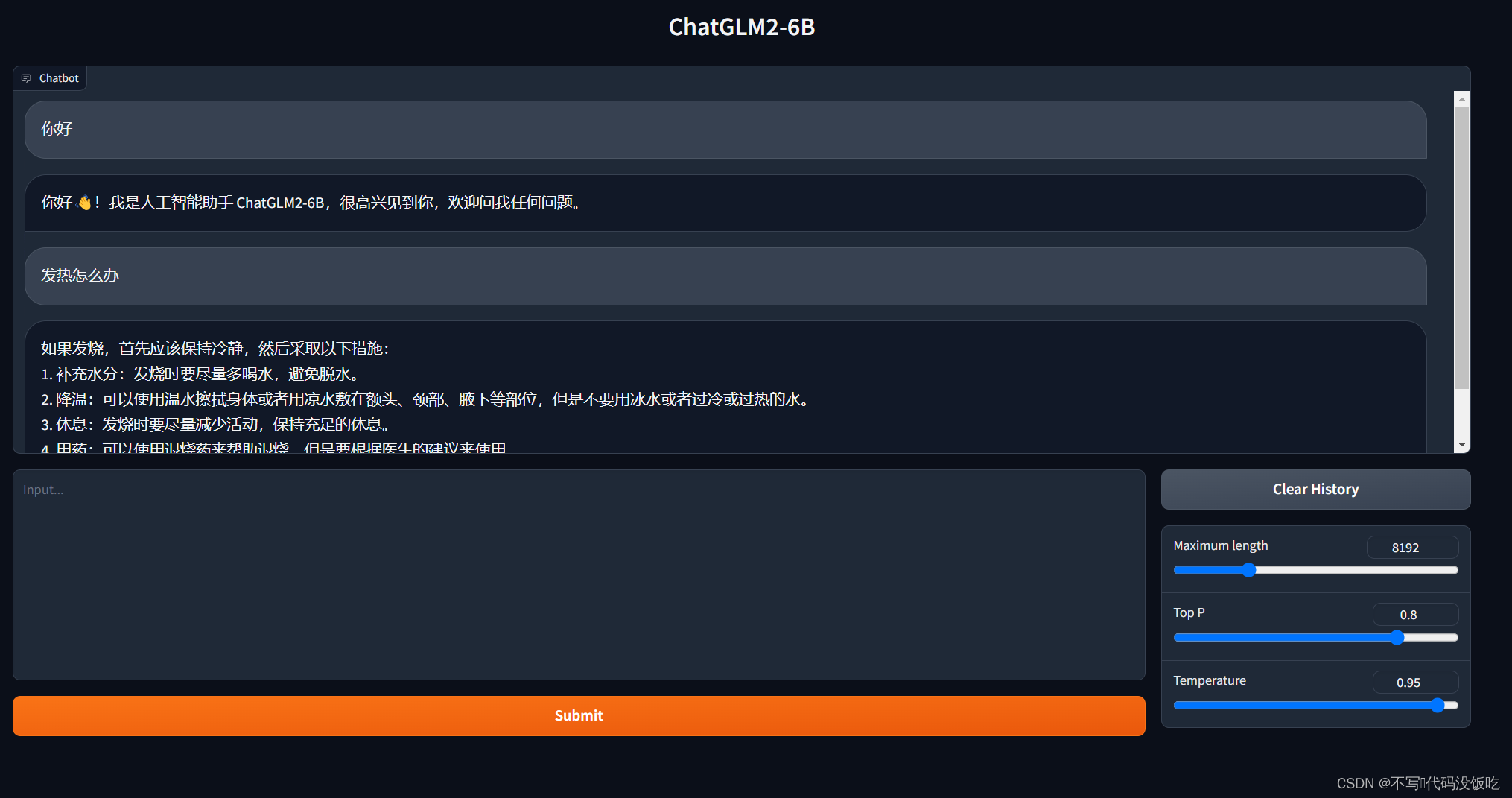
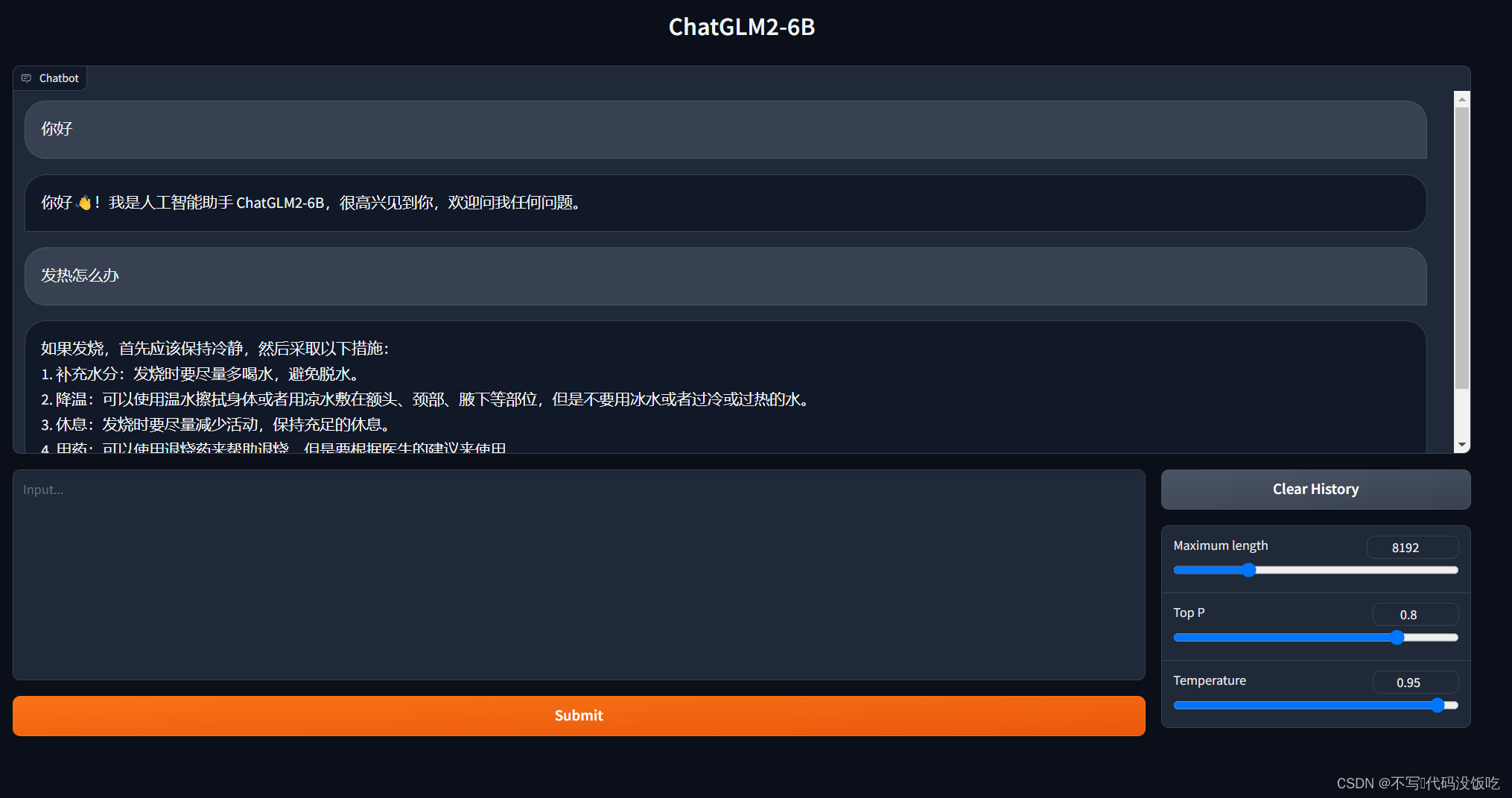
【腾讯云HAI域探秘】0基础也能开发应用
在当今数字化时代,人工智能(AI)和科学计算已经成为许多行业中不可或缺的技术和工具。然而,对于许多开发者和研究者来说,建立和管理高性能应用环境可能是一项具有挑战性的任务。幸运的是,腾讯云的高性能应用服务(Hyper Application Inventor,HAI)为开发者提供了一个强大而便捷的解决方案。
一款云原生时代的高性能 Java 框架
Quarkus 是一个为 Java 虚拟机(OpenJDK HotSpot)和原生编译而设计的全堆栈 Kubernetes 原生 Java 框架,用于专门针对容器优化 Java,并使其成为无服务器、云和 Kubernetes 环境的高效平台。
【腾讯云HAI域探秘】0基础也能开发应用
在当今数字化时代,人工智能(AI)和科学计算已经成为许多行业中不可或缺的技术和工具。然而,对于许多开发者和研究者来说,建立和管理高性能应用环境可能是一项具有挑战性的任务。幸运的是,腾讯云的高性能应用服务(Hyper Application Inventor,HAI)为开发者提供了一个强大而便捷的解决方案。
星脉高性能计算网络:为AI大模型构筑网络底座
前言
AI大模型以其优异的自然语言理解能力、跨媒体处理能力以及逐步走向通用AI的潜力成为近年AI领域的热门方向。业内头部厂商近期推出的大模型的参数量规模都达到了万亿、10万亿级别。
前几天横空出世的AI爆款产品ChatGPT,可以聊天、写代码、解答难题、写小说,其技术底座正是基于微调后的GPT3.5大模型,参数量多达1750亿个。据报道,GPT3.5的训练使用了微软专门建设的AI超算系统,由1万个V100 GPU组成的高性能网络集群,总算力消耗约3640 PF-days (即假如每秒计算一千
计算机科学:高通最新PC端CPU Snapdragon X 解读
高通公司作为全球领先的移动芯片制造商,一直在推动ARM架构的普及。随着移动设备和笔记本市场的不断融合,高通推出了其最新的PC端CPU——Snapdragon X。本文将详细介绍Snapdragon X的技术特性、优势及其对PC市场的影响。

腾讯云原生TKE团队【校招】开始啦!
腾讯云原生TKE是一款基于 Kubernetes 构建的高度可扩展的高性能容器管理服务,是腾讯集团对内和对外统一的云原生技术底座,实现了云上云下、任意位置、任意类型资源的统一管理,运行了数千万核心规模的业务,支撑着多款国民级互联网应用的稳定运行,创造了国内最大规模的云原生上云实践。

WebGPU:下一代 Web 图形和计算 API
WebGPU 是一种新兴的 Web 标准,旨在为现代图形和计算应用提供高性能、低功耗的 API。本文将介绍 WebGPU 的背景、特点、用途以及和 WebGL 的对比。

高性能私有云网络解决方案
针对以上问题,客户决定建设一套自己的私有云网络环境。通过私有云来分配较高配置的虚机满足研发的快速编译需求;通过将企业的IT应用迁移到私有云来节省不必要的开支,并实现统一运维和管理;
高性能私有云网络解决方案
针对以上问题,客户决定建设一套自己的私有云网络环境。通过私有云来分配较高配置的虚机满足研发的快速编译需求;通过将企业的IT应用迁移到私有云来节省不必要的开支,并实现统一运维和管理;
【腾讯云HAI域探秘】“赋予艺术生命:通过腾讯云HAI和MagicAnimate呈现动态蒙娜丽莎“
AI 视频生成领域近期算是非常热闹,个人也是非常的感兴趣,奈何电脑不给力,在搭建的过程中总是提示各种各样的问题 , 不过天无绝人之路, 最近 腾讯云高性能应用服务(Hyper Application Inventor,HAI) 活动正在如火如荼的进行着, 因此决定挑战一下, 看下在HAI 上搭建 AI 动画生成框架 MagicAnimate 是否会有不一样的收获.

基于 GPU 渲染的高性能空间包围计算
现代煤矿开采过程中,安全一直是最大的挑战之一。地质空间中存在诸多如瓦斯积聚、地质构造异常、水文条件不利等隐蔽致灾因素,一旦被触发,可能引发灾难性的后果。因此在安全生产过程中有效的管理和规避各隐蔽致灾因素,有着重要的意义。
