Byzer + OpenMLDB 实现端到端的,基于实时特征计算的机器学习流程
本文示范如何使用OpenMLDB和 Byzer-lang 联合完成一个完整的机器学习应用。Byzer-lang 作为面向大数据和AI的一门语言,通过 Byzer-Notebook 和用户进行交互,用户可以轻松完成数据的抽取,ETL,特征/模型训练,保存,部署到最后预测等整个端到端的机器学习流程。OpenMLDB在本例中接收Byzer发送的指令和数据,完成数据的实时特征计算,并经特征工程处理后的数据集返回Byzer,供其进行后续的机器学习训练和预测。
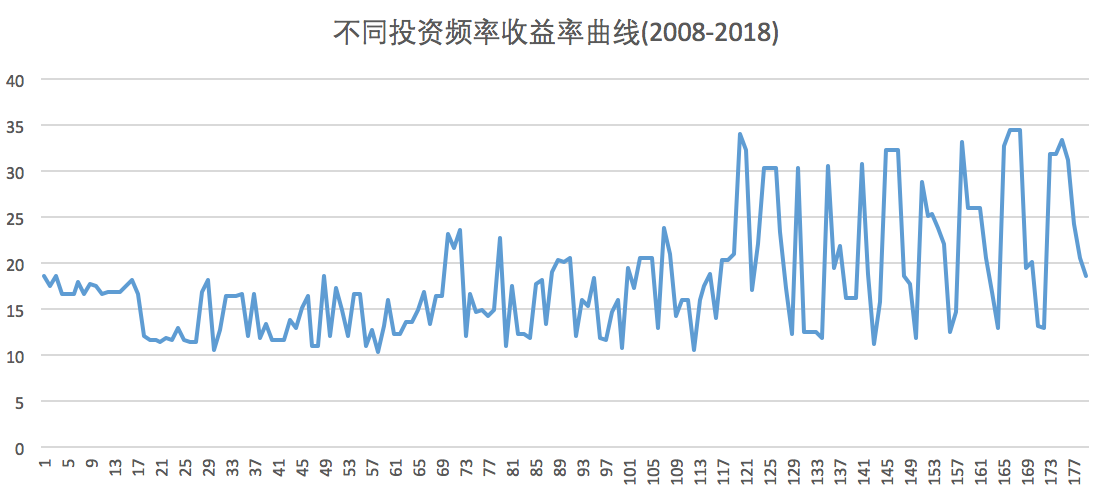
用python教你计算定投能获得多少收益
经常有一些专家告诉你,定投风险小,长期能获得不错的收益。因为投资者在高点时买入的份额较少,而在低处买入的份额较多。
【点云学习】 源代码和关键功能介绍
https://pan.baidu.com/s/1XaKFZLudnnISui7lV8540A
【点云学习】 源代码和关键功能介绍
https://pan.baidu.com/s/1XaKFZLudnnISui7lV8540A
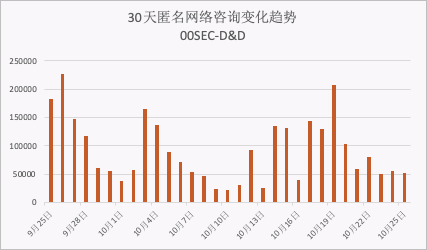
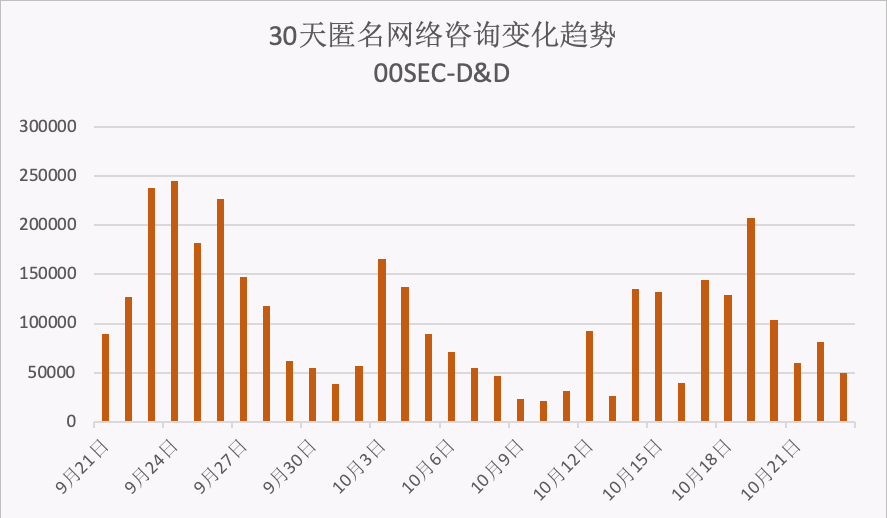
零零信安-D&D数据泄露报警日报【第27期】
2022.10.20共发现匿名网络资讯信息103,249条;最近7天共发现匿名网络资讯信息891,289条,同比增长200.51%;最近30天共发现匿名网络资讯信息3,237,609条。
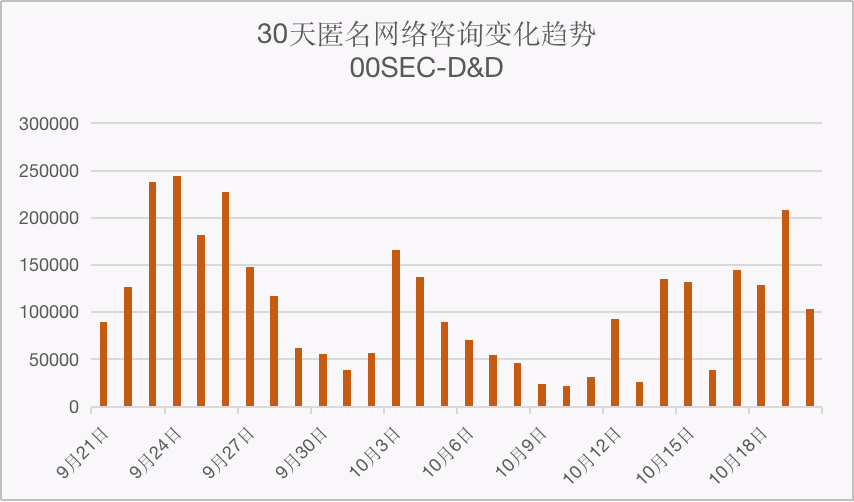
零零信安-D&D数据泄露报警日报【第30期】
2022.10.25共发现匿名网络资讯信息51,776条;最近7天共发现匿名网络资讯信息609,339条,同比增长-12.9%;最近30天共发现匿名网络资讯信息2,654,384 条。
十分钟,用 Python 带你看遍 GDP 变迁
偶然之间,发现了一个网站,title 是世界银行,很高级的样子,可以下载很多有趣的数据,这对于我们练手数据分析及可视化真的是太好的资源了,不多说,戳下面的链接可以火箭直达哦!
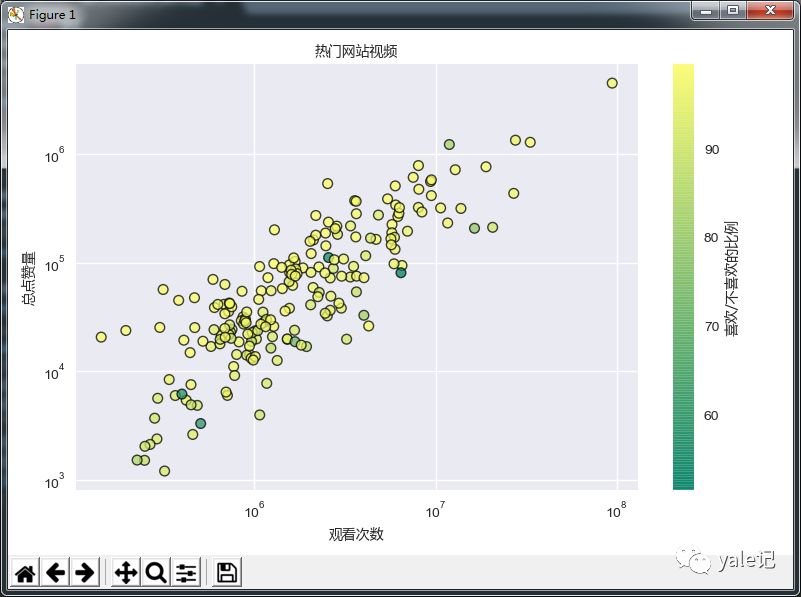
数据可视化-Matplotlib散点图统计最热门视频
今天我们将学习如何在Matplotlib中创建散点图。散点图非常适合确定两组数据是否相关。如果存在相关性,散点图可以让我们发现这些趋势。散点图的想法通常是比较两个变量,让我们开始吧。
互联网企业裁员潮背后的就业危机与机遇-采集招聘信息
近年来,随着经济增速放缓、互联网流量见顶、资本寒冬等因素的影响,许多知名的互联网公司都进行了组织结构调整和人员优化,以降低成本和提高效率。据智联招聘统计,有43.4%的被裁员者表示原因是“企业生产经营状况发生困难”,有37%的被裁员者表示原因是“企业进行组织结构调整”。受到裁员影响最大的岗位是前端开发、软件测试和UI设计等职能较为单一且容易被替代的岗位。其他受到疫情影响较大的领域包括旅游、餐饮、零售、媒体等。 全球范围内,IT行业都面临着就业形势严峻和竞争激烈的局面。一方面,由于市场需求下降和技术变革加速,导致了部分岗位被淘汰或缩减;另一方面,由于IT行业门槛相对较低和薪资水平相对较高,吸引了大量的求职者涌入或转行进入该行业。这就造成了供需失衡和人才结构失衡的问题。 对于求职者来说,在这样一个充满挑战和机遇的时代里,如何提升自己的核心竞争力和适应能力成为了关键。在当今的互联网时代,找工作不再局限于传统的招聘网站或者人才市场,而是有了更多的选择和渠道。其中,领英、boss直聘和猎聘网是三个比较受欢迎且有效果的招聘平台 。 那么如何快速通过这三个平台找到适合自己并符合市场需求的工作岗位呢:

【Rust日报】2024-05-11 Tabiew 简介:用于查看和查询 CSV 文件的基于终端的工具
Kira 是一个与后端无关的库,用于为游戏创建富有表现力的音频。它提供了用于平滑调整声音属性的补间、用于将效果应用于音频的灵活混音器、用于精确计时音频事件的时钟系统以及空间音频支持。

基于flink的电商用户行为数据分析【4】| 恶意登录监控
前言
在上一期内容中,菌哥已经为大家介绍了实时热门商品统计模块的功能开发的过程(?基于flink的电商用户行为数据分析【3】| 实时流量统计)。本期文章,我们需要学习的是恶意登录监控模

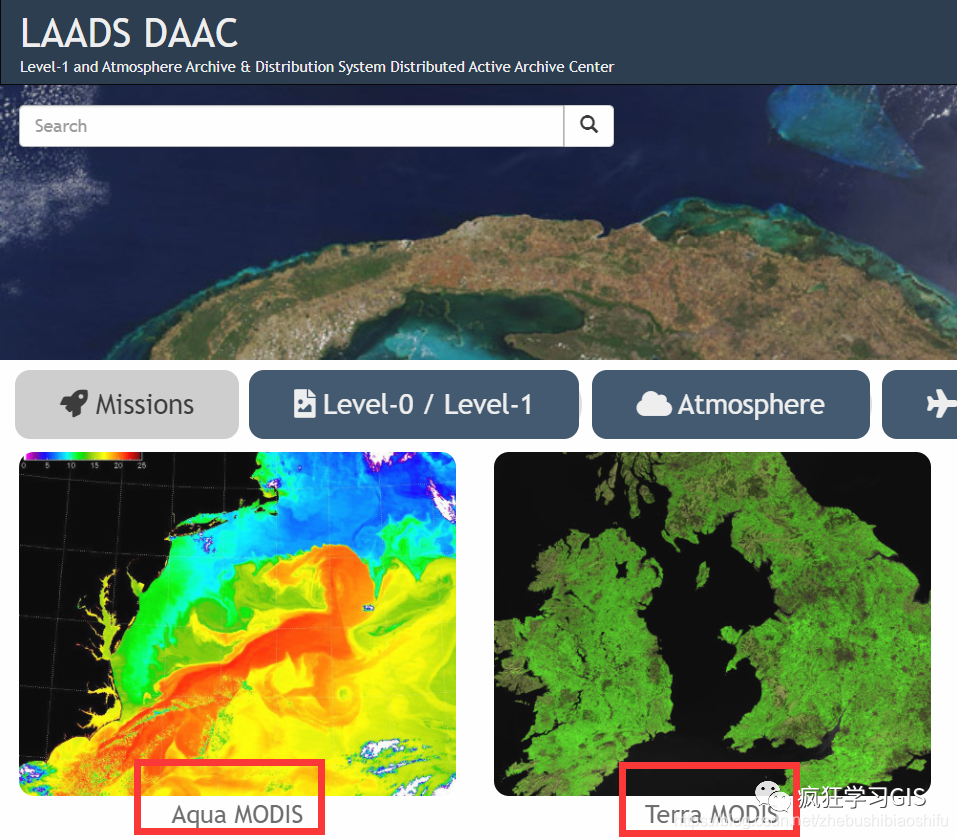
基于LAADS DAAC的MODIS遥感影像批量下载
本文介绍国内用户在LAADS DAAC中批量下载MODIS遥感影像各产品的方法。
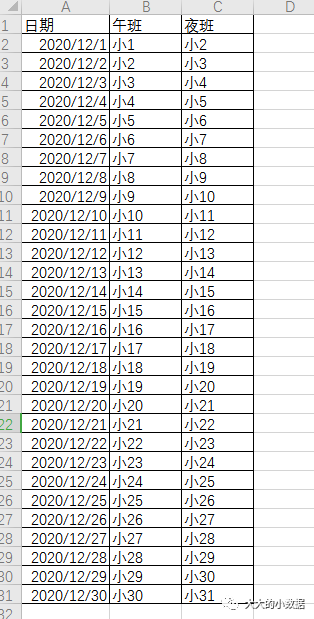
python+csv+datetime+pushplus的值班提醒推送2020.12.19
建一个值班表。
📷
#1、读取excel中的内容
#2、匹配当天日期,格式化为/形式。
#3、把匹配到的日期后面内容推送到微信
# -*- coding: utf-8 -*-
import datetime # 引入time模块
import csv
import pysnooper
import requests
#@pysnooper.snoop(normalize= True,prefix="主程序")
def main():
with open('值班2020.12.19.csv',
Python抓取API得到的字符串写入csv分隔问题
在Python中写了如下代码,直接打印出来可以实现,但是在写入csv时遇到了困难,

零零信安-D&D数据泄露报警日报【第28期】
2022.10.23共发现匿名网络资讯信息49,638条;最近7天共发现匿名网络资讯信息775,042条,同比增长62%;最近30天共发现匿名网络资讯信息2,972,908条。
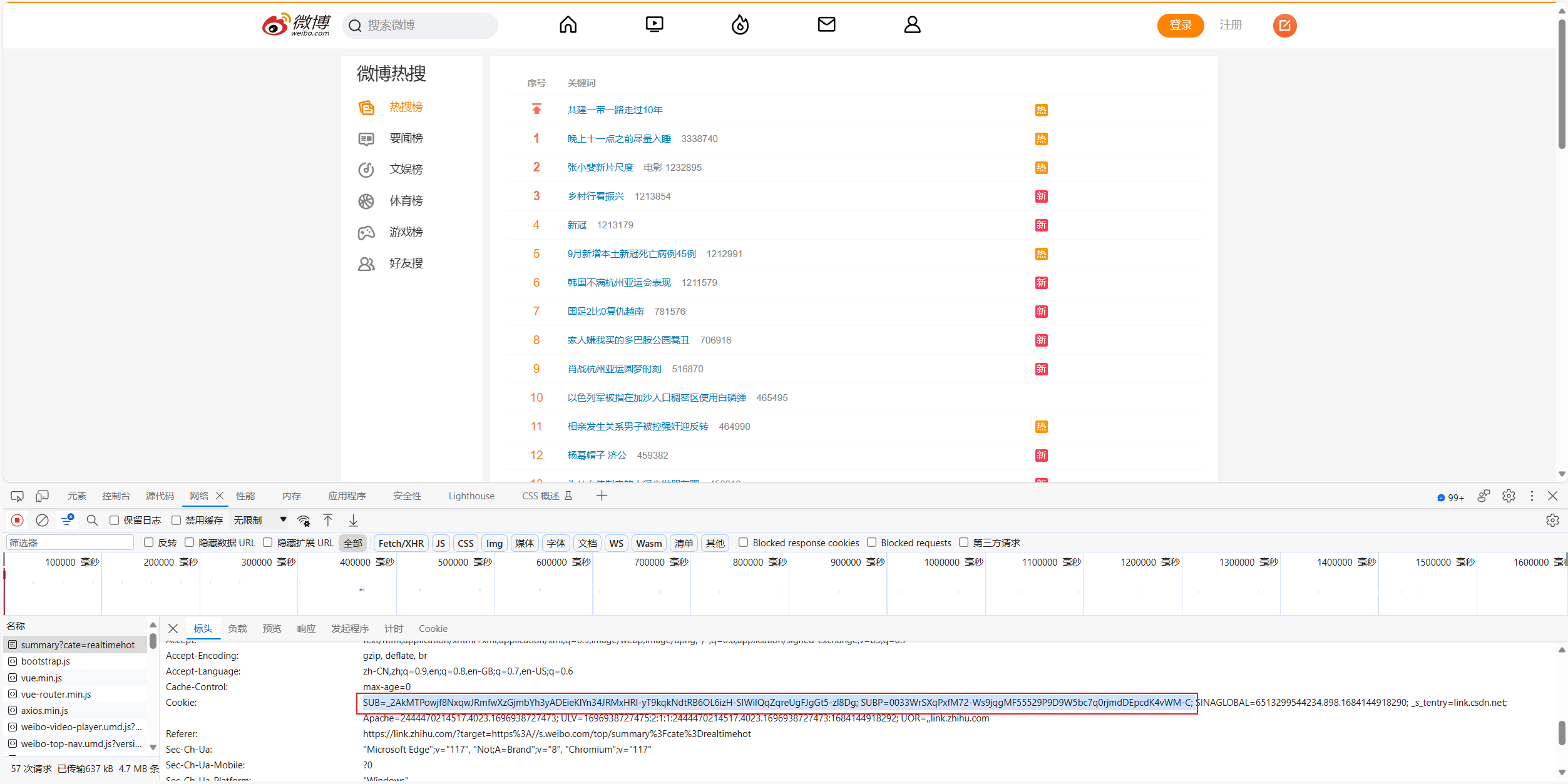
爬取微博热榜并将其存储为csv文件
基于大数据技术的社交媒体文本情绪分析系统设计与实现,首先需要解决的就是数据的问题,我打算利用Python 语言的Scrapy、Beautiful Soup等工具抓取一段时间内新浪微博用户对于热点事件的博文之后,按照事件、时间等多种方式进行分类,接着利用正则表达式等工具过滤掉微博正文中的超链接、转发信息、表情符号、广告宣传和图片等无效信息之后,将处理完的文本进行手工标注,最终将标注的文本作为训练语料库。今天的主要工作量就是对数据的获取,进行简单的热榜爬虫、和热点爬虫,热榜爬虫代码进行公开,热点爬虫代码需要的欢迎私信有偿获取。
python脚本之批量查询网站权重
相信很多人在批量刷野战的时候,会去查看网站的权重吧,然后在决定是否提交给补天还在是盒子。但是不能批量去查询,很困惑,作为我这个菜鸟也很累,一个个查询的。所以写了这个脚本。
参考脚本爱站批量查询网址权重2.0版本。
使用Python创建faker实例生成csv大数据测试文件并导入Hive数仓
这段代码使用Faker库生成模拟的个人信息数据,每个CSV文件包含一定数量的行数据,数据字段包括 Rowkey, Name, Age, Email, Address, IDNumber, PhoneNumber, Nationality, Region, SourceCode。
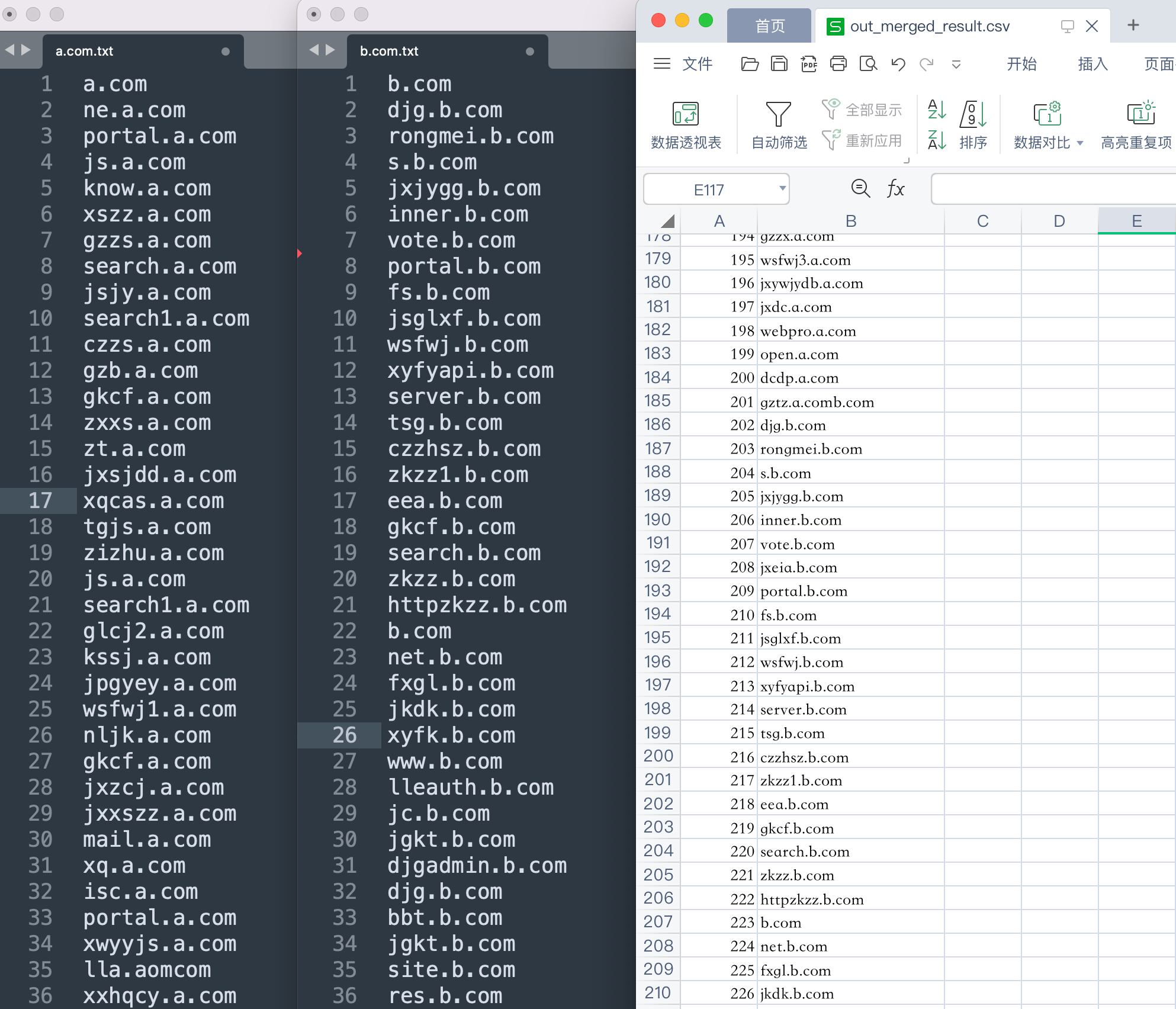
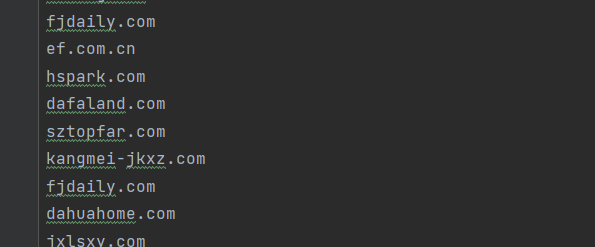
(字典、子域名)合并去重 Python 脚本
一般在做渗透测试的时候,前期对目标资产子域名进行信息搜集时,往往会从多个在线或者离线子域名采集工具中导出结果。然而每个工具平台导出的结果中都会有很多重复的子域名,如果靠手工对这些子域名结果进行合并去重的话,是非常的繁琐且低效率的,因此可以借助脚本工具替我们去完成这一复杂的整理工作,提高渗透效率。
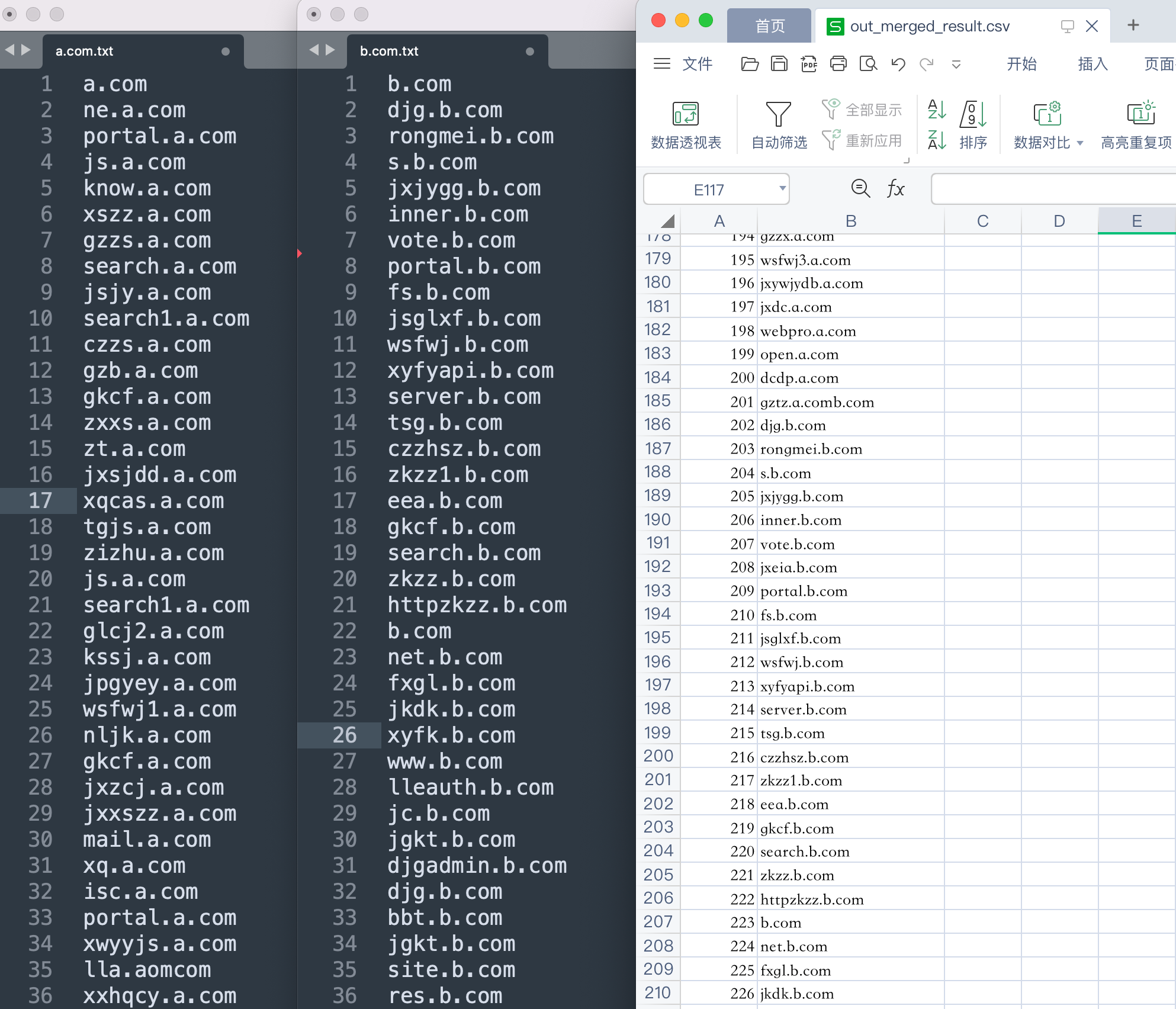
(字典、子域名)合并去重 Python 脚本
一般在做渗透测试的时候,前期对目标资产子域名进行信息搜集时,往往会从多个在线或者离线子域名采集工具中导出结果。然而每个工具平台导出的结果中都会有很多重复的子域名,如果靠手工对这些子域名结果进行合并去重的话,是非常的繁琐且低效率的,因此可以借助脚本工具替我们去完成这一复杂的整理工作,提高渗透效率。