基于正交投影的点云局部特征描述详解
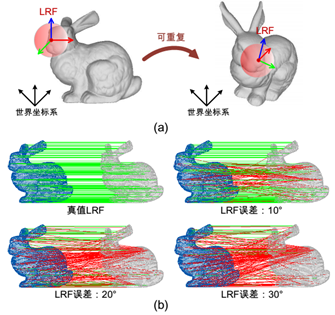
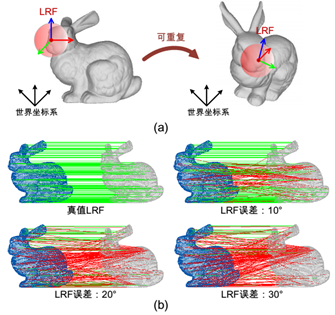
本次介绍一个发表于Pattern Recognition的经典三维点云描述子TOLDI,首先进行算法阐述,然后再给出数据集的介绍、局部参考坐标系与描述子的评估方法。
基于正交投影的点云局部特征描述详解
本次介绍一个发表于Pattern Recognition的经典三维点云描述子TOLDI,首先进行算法阐述,然后再给出数据集的介绍、局部参考坐标系与描述子的评估方法。
Sentence-BERT: 一种能快速计算句子相似度的孪生网络
BERT和RoBERTa在文本语义相似度等句子对的回归任务上,已经达到了SOTA的结果。但是,它们都需要把两个句子同时喂到网络中,这样会导致巨大的计算开销:从10000个句子中找出最相似的句子对,大概需要5000万(C100002=49,995,000)个推理计算,在V100GPU上耗时约65个小时。这种结构使得BERT不适合语义相似度搜索,同样也不适合无监督任务(例如:聚类)。

回答:计算系统发育多样性时排除物种数影响
以MNTD(mean-nearest-taxon-distance)和NTI(nearest-taxon-index)为例,其他系统发育多样性指数类似:
回答:计算系统发育多样性时排除物种数影响
以MNTD(mean-nearest-taxon-distance)和NTI(nearest-taxon-index)为例,其他系统发育多样性指数类似:
Python数据分析入门(七):Pandas统计计算和描述
示例代码:
arr1 = np.random.rand(4,3)
pd1 = pd.DataFrame(arr1,columns=list('ABC'),index=list('abcd'))
f = lambda x: '%.2f'% x
pd2 = pd1.applymap(f).astype(float)
pd2
运行结果:
A B C
a 0.87 0.26 0.67
b 0.69 0.89
Python数据分析入门(七):Pandas统计计算和描述
示例代码:
arr1 = np.random.rand(4,3)
pd1 = pd.DataFrame(arr1,columns=list('ABC'),index=list('abcd'))
f = lambda x: '%.2f'% x
pd2 = pd1.applymap(f).astype(float)
pd2
运行结果:
A B C
a 0.87 0.26 0.67
b 0.69 0.89
气象大模型论文中评估指标的计算详解
参考:https://github.com/xiazh18/WeatherBench/blob/master/src/score.py

计算等压面要素场的基本检验指标
本文假定上述数据均被插值成 WMO GDPFS 手册中规定的标准网格,即 1.5 度 * 1.5 度。下面的指标计算不涉及数据插值问题。
遗传变异系数怎么计算
今天有人问我遗传变异系数怎么计算, 我第一次听说这个概念, 一般来说, 大家在汇总统计中经常计算最大值, 最小值, 方差, 标准差, 变异系数, 这里的变异系数就是标准差除以平均数.
caffe中计算图像的均值
首先要编译compute_image_mean.cpp文件,生成compute_image_mean.exe文件,具体生成方式类似于
104-R茶话会19-几种查看函数源代码的方法
最近正好在探索[[管中窥rpca(ReciprocalProject)]] 函数以及seurat 家族里其他函数的用法,借此机会来总结一下。

Warning: [antd: Upload] `value` is not a valid prop, do you mean `fileList`?
最近我在使用React+antd重写博客网站,在编写一个表单页面时遇到了如下报错:Warning: [antd: Upload] `value` is not a valid prop, do you
几种小提琴图、箱线图绘制法2020.8.6
2、The level you wish to aggregate yourmeasure data at, to prevent incorrectaggregation prior to plotting。您希望在绘图之前将度量数据聚合到的级别,以防止错误聚合。
3、measuie data测量数据
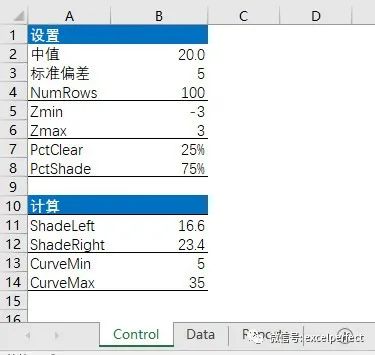
Excel图表学习:创建带有阴影区域的正态曲线图
打开一个新工作簿,至少包含有三个工作表,其名称分别为:Control,Data和Reports。