Python网页请求超时如何解决
在进行网络爬虫项目时,我们经常需要发送大量的请求来获取所需的数据。然而,由于网络环境的不稳定性,请求可能会因为超时而失败。请求超时可能导致数据获取不完整,影响爬虫的效率和准确性。此外,频繁的请求超时可能会被目标网站视为恶意行为,导致IP被封禁或其他限制。为了确保数据的完整性和准确性,我们需要处理这些超时问题。
anaconda安装gpu版pytorch
在安装pytorch环境时,发现好多教程都介绍从官网获取下载代码,然后在conda环境中输入在线下载,我在这样尝试时,总是因外网下载太慢timeout而下载中断。
后来从这个网站戳这里直接将whl文件下载,再用pip手动安装,顺利安装成功。
注:torch和torchvision版本需要对应
具体步骤不作赘述,将该网址记录于此,以便日后查阅
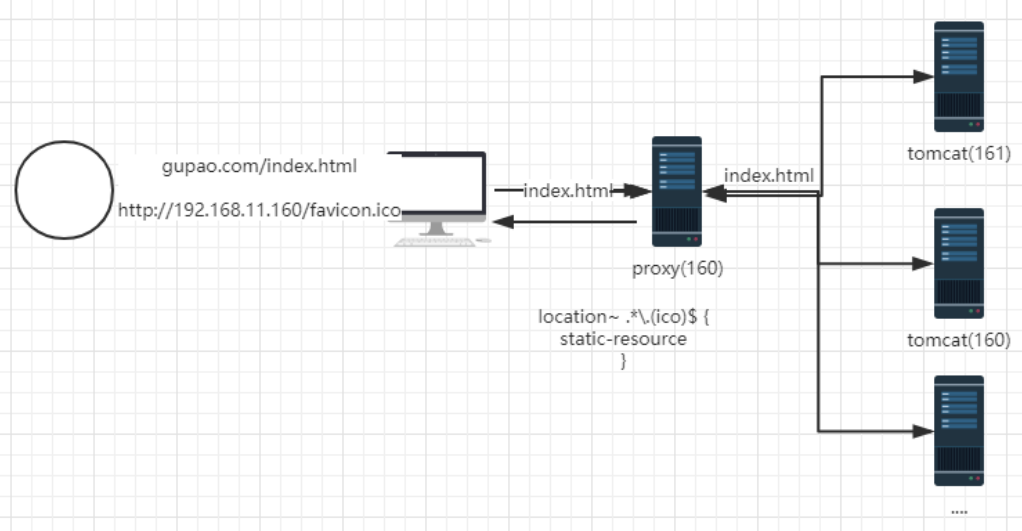
Nginx学习之Nginx实战(二)
nginx反向代理的指令不需要新增额外的模块,默认自带proxy_pass指令,只需要修改配置文件就可以实现反向代理。
python爬虫怎么解决超时timeou错误
爬虫在运行过程会出现各种报错的问题,比如当我们在进行网络爬虫的时候,一般都是先进行网站的访问才能够正常的进行数据的获取,但是有的时候进行网站的访问的时候,总是会出现请求超时的情况。这个就可能是因为网络状况不好或者是服务器的网络出现延迟导致的我们访问请求超时。或者又是在进行网络端口连接的时候时间的延迟也会导致或者是在请求量比较大,目标网站承重量有限的情况下可能会出现下面这种报错。
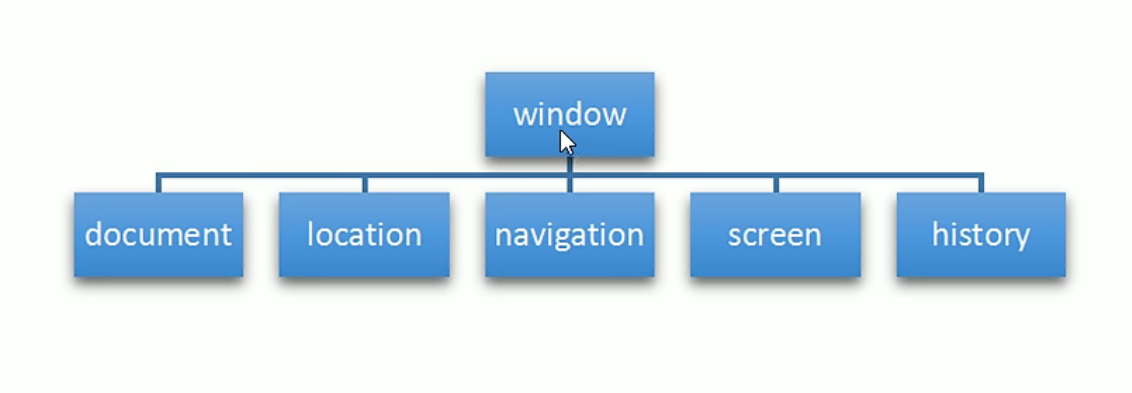
BOM概述
在上一篇文章中我们学习了DOM,接下来让我们先通过和DOM的对比来简单了解一下BOM
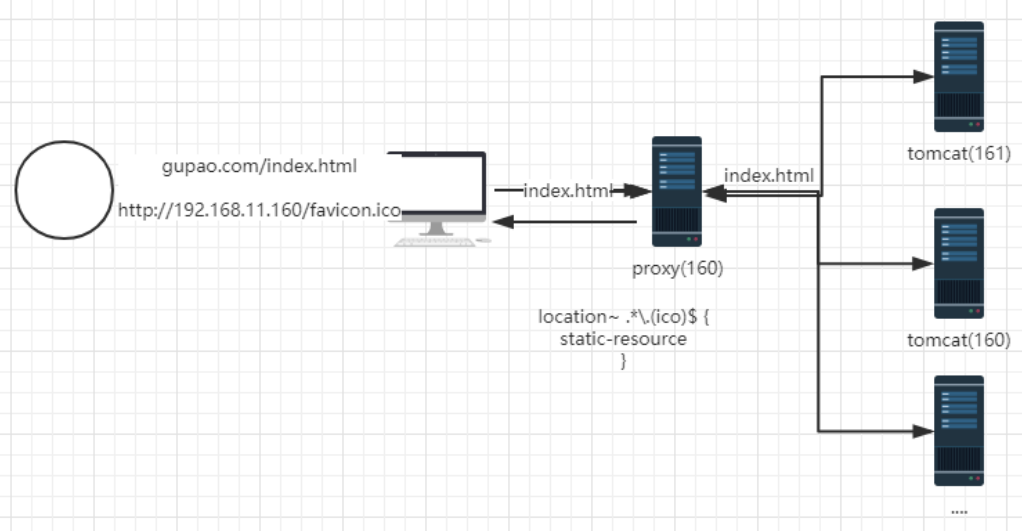
Nginx学习之Nginx实战(二)
nginx反向代理的指令不需要新增额外的模块,默认自带proxy_pass指令,只需要修改配置文件就可以实现反向代理。
Nginx结构全解析(91)
刷新页面发现页面会发生变化,证明负载配置成功。因为我配的权重第二个是第一个的两倍,所以第二个出现的概率会是第一个的两倍。
解决我遇到的Initial Connection 超长时间的问题
问题发生的过程是再点击按钮后弹出一个层,层里有一个表单,表单弹出之前会通过后台接口获取下拉选项列表,第一次点击这个按钮不会有任何问题。第二次点击的时候会发生个别请求 Initial Connection 时间特别长的问题,同时页面假死(CPU占用很高),无响应,需要等请求超时后页面可以恢复操作。
【MySQL】Mysql5.7.21 传统复制切换到gtid复制遇到的一个现象
系统:centos7
主库 M:192.168.16.12:3306
从库 S:192.168.16.15:3306
主从复制:传统复制