腾讯云什么产品可以满足大型语言模型的开发需求?
腾讯云提供了多种产品和服务,可以满足大型语言模型的开发需求,以下是一些常用的产品和服务:
腾讯云什么产品可以满足大型语言模型的开发需求?
腾讯云提供了多种产品和服务,可以满足大型语言模型的开发需求,以下是一些常用的产品和服务:
PHP如何计算两篇文章的相似度
要计算两篇文章的相似度,可以使用自然语言处理技术,对两篇文章的内容进行分析,并计算它们之间的相似度。具体实现方式如下:
计算机视觉之Vision Transformer图像分类
自注意结构模型的发展,特别是Transformer模型的出现,极大推动了自然语言处理模型的发展。Transformers的计算效率和可扩展性使其能够训练具有超过100B参数的规模空前的模型。ViT是自然语言处理和计算机视觉的结合,能够在图像分类任务上取得良好效果,而不依赖卷积操作。

开发大型语言模型需要什么计算资源?
开发大型语言模型需要大量的计算资源和时间,因此需要进行有效的资源管理和优化,以便提高计算效率和降低成本。同时,还需要进行不断的迭代和改进,以便提高模型的性能和效果。
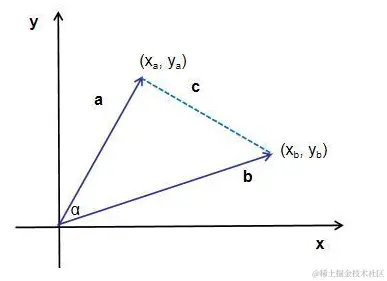
相似度计算——余弦相似度
余弦相似度是利用两个向量之间的夹角的余弦值来衡量两个向量之间的相似度,这个值的范围在-1到1之间。
ES相关性计算原理
按相关性排序,返回优先队列顺序长度的结果

ES相关性计算原理
按相关性排序,返回优先队列顺序长度的结果

Python 中进行文本分析的 Top 5 NLP 工具
翻译自 Top 5 NLP Tools in Python for Text Analysis Applications 。
Chat GPT是什么,初学者怎么使用Chat GPT,需要注意些什么
随着人工智能技术的不断发展,Chat GPT(Generative Pre-trained Transformer)作为一种强大的自然语言处理模型,引起了广泛的关注。它能够理解和生成人类语言,使计算机能够更好地与人进行交流和沟通。对于初学者来说,使用Chat GPT是一种非常有趣和有挑战性的体验。本文将介绍Chat GPT是什么,以及初学者如何使用它,同时提供一些建议,让大家能够充分利用Chat GPT的潜力。

chatgpt+midjourney初探
当今的社交网络已经成为人们生活中不可或缺的一部分,人们在这里分享生活、交流思想、寻找信息和娱乐等等。在日常的科研学习中,我们会遇到各种难题,我们会寻求某歌等搜索引擎,某瓣某虫等专业的社区,但是这样的速度实在是太慢了。

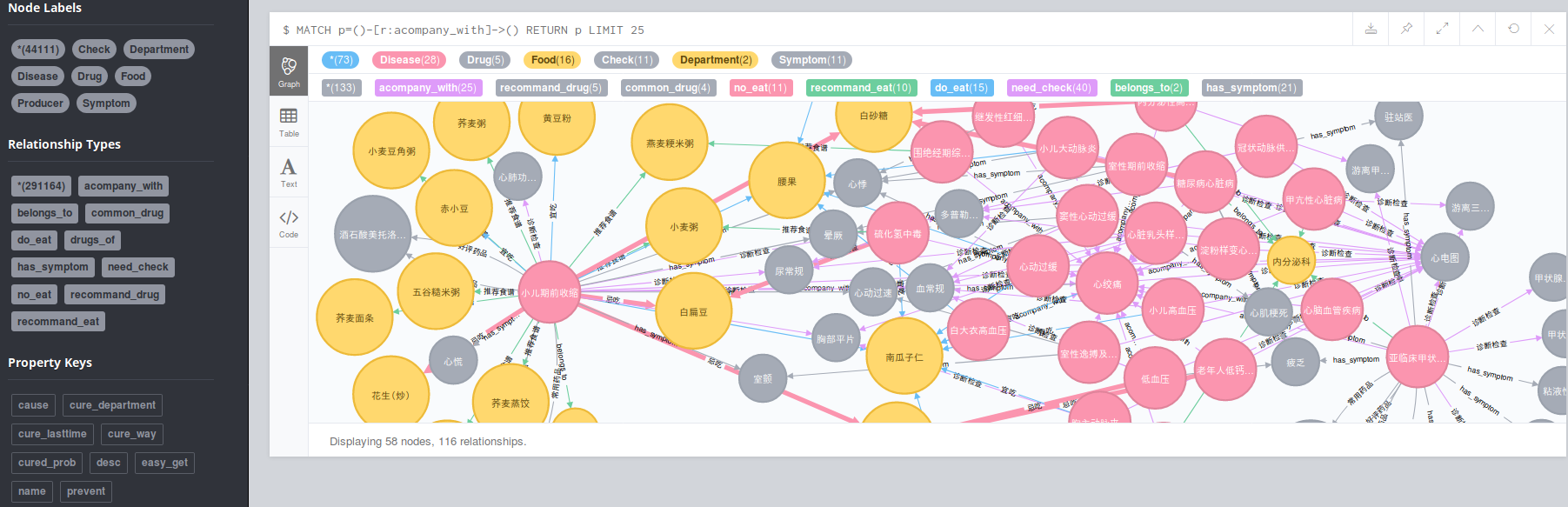
从零开始搭建医药领域知识图谱实现智能问答与分析服务(含码源):含Neo4j基于垂直网站数据的医药知识图谱构建、医药知识图谱的自动问答等
关于知识图谱概念性的介绍就不在此赘述。目前知识图谱在各个领域全面开花,如教育、医疗、司法、金融等。本项目立足医药领域,以垂直型医药网站为数据来源,以疾病为核心,构建起一个包含7类规模为4.4万的知识实体,11类规模约30万实体关系的知识图谱。
火爆国内外的大模型究竟是什么?有哪些大模型学习和参赛的网站?
大模型,通常是指由大量参数和复杂结构组成的机器学习模型。这些模型通常需要大量的数据和计算资源来训练和部署,以实现更高的预测性能和更复杂的任务。

基于编码注入的对抗性NLP攻击
研究表明,机器学习系统在理论和实践中都容易受到对抗样本的影响。到目前为止,此类攻击主要针对视觉模型,利用人与机器感知之间的差距。尽管基于文本的模型也受到对抗性样本的攻击,但此类攻击难以保持语义和不可区分性。在本文中探索了一大类对抗样本,这些样本可用于在黑盒设置中攻击基于文本的模型,而无需对输入进行任何人类可感知的视觉修改。使用人眼无法察觉的特定于编码的扰动来操纵从神经机器翻译管道到网络搜索引擎的各种自然语言处理 (NLP) 系统的输出。通过一次难以察觉的编码注入——不可见字符(invisible character)、同形文字(homoglyph)、重新排序(reordering)或删除(deletion)——攻击者可以显着降低易受攻击模型的性能,通过三次注入后,大多数模型可以在功能上被破坏。除了 Facebook 和 IBM 发布的开源模型之外,本文攻击还针对当前部署的商业系统,包括 Microsoft 和 Google的系统。这一系列新颖的攻击对许多语言处理系统构成了重大威胁:攻击者可以有针对性地影响系统,而无需对底层模型进行任何假设。结论是,基于文本的 NLP 系统需要仔细的输入清理,就像传统应用程序一样,鉴于此类系统现在正在快速大规模部署,因此需要架构师和操作者的关注。
